


今天埋头完成了Introduction和Methodology两个部分,然后来回地检查句子,短语、单词和逻辑,终于脑子开始进入混沌状态,实在没办法,随手找了一篇文献来读读。(主要这篇文章比较简单易懂,容易理思路。)
Arqane, A., et al. (2021). A Review of Intrusion Detection Systems: Datasets and machine learning methods.
这是一篇综述文章,此外题目还是有吸引力的,三个关键词:
Intrusion Detection Systems,Datasets 和 machine learning methods
关键词即主题:
-
保护网络安全的解决方案之一入侵检测系统Intrusion Detection Systems;
-
用来训练机器学习模型的数据集Datasets;
-
以及使用数据集来训练和测试模型的各种机器学习方法machine learning methods。
讨论的主题,文章的结构以及思路逻辑就不赘述,具体Google搜索可以访问。
要点理一下:
-
机器学习的模型优劣与否,很大程度取决于训练的数据集,文章整理并讨论了主流的数据集。
-
通过机器学习来提升入侵检测系统的攻击探测成功率,以及降低误报率,已经有相当多的研究和应用,该文章整理了相关的文献。
-
机器学习在IDS的应用当中,依然存在并且持续存在挑战,文章给出了相应观点,并给予了研究建议。
干货直接上:
-
主流的用于机器学习模型训练、验证和测试的数据如下:
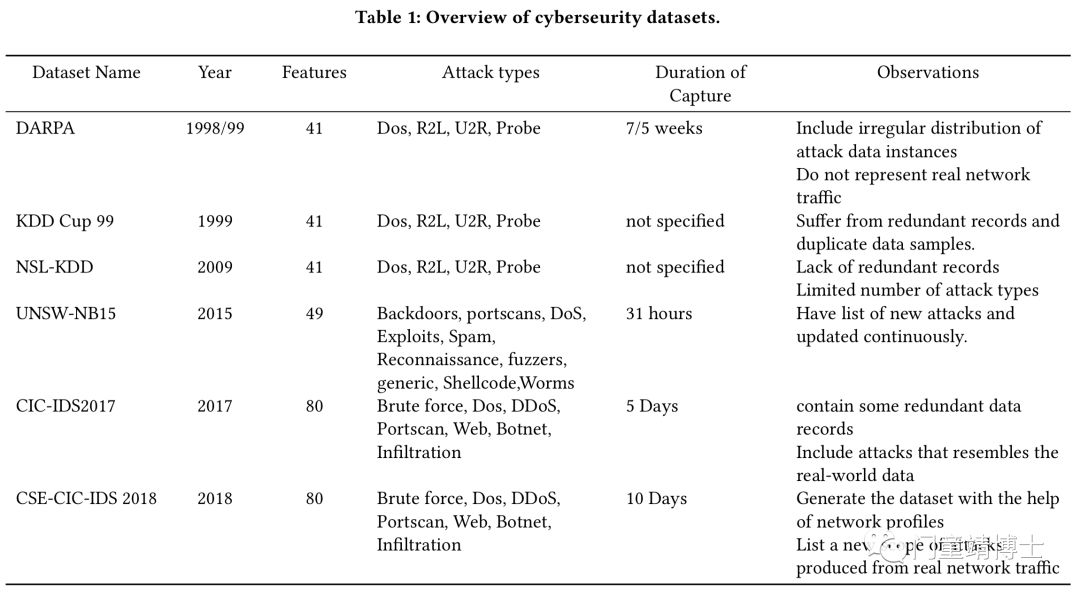
2. 通过机器学习来提升IDS探测能力的一些研究案例如下:

3. 那么挑战是什么呢?(数据集Datasets占了大头)
-
太缺了!从数据集表格里可以看到,从1998年到2018年只有6个公开并且大量用于模型研究的数据集。
-
太旧了!从机器学习的研究表格可以发现,2020的研究还依然在用两年前的数据集,这对于日新月异的网络安全领域来说,或者对于网络攻击者来说,会不会太落后?
-
真的吗?实际上以上的数据集基本是从实验室环境模拟出来的,尤其是早期的DARPA, KDD CUP99和NSL-KDD,随后UNSW-NB15,CIC-IDS2017和CSE-CIC-IDS2018增加了真实的用户流量,但依然无法模拟实际的网络环境。
-
太费了!目前对于机器学习在IDS上的研究和应用,大多数仍然是以受监督的机器学习(Supervised Learning)算法为主,因此,需要对数据集打标签,比如这条记录不是攻击,那这条记录是攻击,另外一条记录是DDoS攻击,还有一条又是R2L攻击…人工来做的话,真的费时费力!
-
脏乱差!毕竟数据集都是模拟环境下生成的裸数据(一大堆数据包),经过软件外加人工转化为数据集(想象一下巨大巨大的excel表格),然后又经过人工标签,整个流程下来,这数据有多脏(比如很多重复数据),乱(比如一些空数据和越界数据),差(比如真实的网络攻击和正常流量比例在1:10,然而数据集的比例是10:1),总体下来基于这样的数据集要训练出学习出有效的模型,真的很难为机器!
-
博弈战!网络安全领域,攻击和防御是永恒的主题。老实说,防守的还是要吃亏的,因为从IDS的机制上,对于攻击方来说,防守方是占下风的。比如说是先有了攻击,IDS才知道它是攻击,再将它纳入IDS的攻击库当中(Signature-based IDS),即便是通过机器学习发现异常状态(Anomaly-based IDS),比如在凌晨2点发现大量的正常访问,从而识别出异常并第一时间报告。但是攻击者也是可以通过AI和机器学习的方式来了解何为正常状态,然后将攻击隐藏在流量的正常状态(Adverserial Attack),从而达到其网络攻击的目的。所谓道高一尺,魔高一丈。
最后,文章不忘提及机器学习的优劣势,但从其调研的文献来看,混合机器学习模型要优于单个机器学习的模型,这也是该作者接下来要去研究的方向。
就大概分享到这,希望有所帮助。
参考文献
Arqane, A., et al. (2021). A Review of Intrusion Detection Systems: Datasets and machine learning methods. Proceedings of the 4th International Conference on Networking, Information Systems & Security. KENITRA, AA, Morocco, Association for Computing Machinery: Article 7.
原创文章,作者:门童靖博士,如若转载,请注明出处:https://www.agent-universe.cn/2022/08/12735.html