
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


论文
Pandora:朝向具有自然语言动作和视频状态的通用世界模型
 http://arxiv.org/abs/2406.09455v1
http://arxiv.org/abs/2406.09455v1BABILong:测试LLM在长文本上的极限推理
 http://arxiv.org/abs/2406.10149v1
http://arxiv.org/abs/2406.10149v1正则化隐藏状态使得LLM学习通用奖励模型
 http://arxiv.org/abs/2406.10216v1
http://arxiv.org/abs/2406.10216v1ChartMimic:通过图表生成代码评估LLM的跨模态推理能力
 http://arxiv.org/abs/2406.09961v1
http://arxiv.org/abs/2406.09961v1
生成AI在教学实践中的系统性回顾
 http://arxiv.org/abs/2406.09520v1
http://arxiv.org/abs/2406.09520v1在评估基准中量化方差
 http://arxiv.org/abs/2406.10229v1
http://arxiv.org/abs/2406.10229v1分组和洗牌:高效的结构正交参数化
 http://arxiv.org/abs/2406.10019v1
http://arxiv.org/abs/2406.10019v1Lamini-Memory-Tuning
 https://github.com/lamini-ai/Lamini-Memory-Tuning
https://github.com/lamini-ai/Lamini-Memory-TuningStableSwarmUI
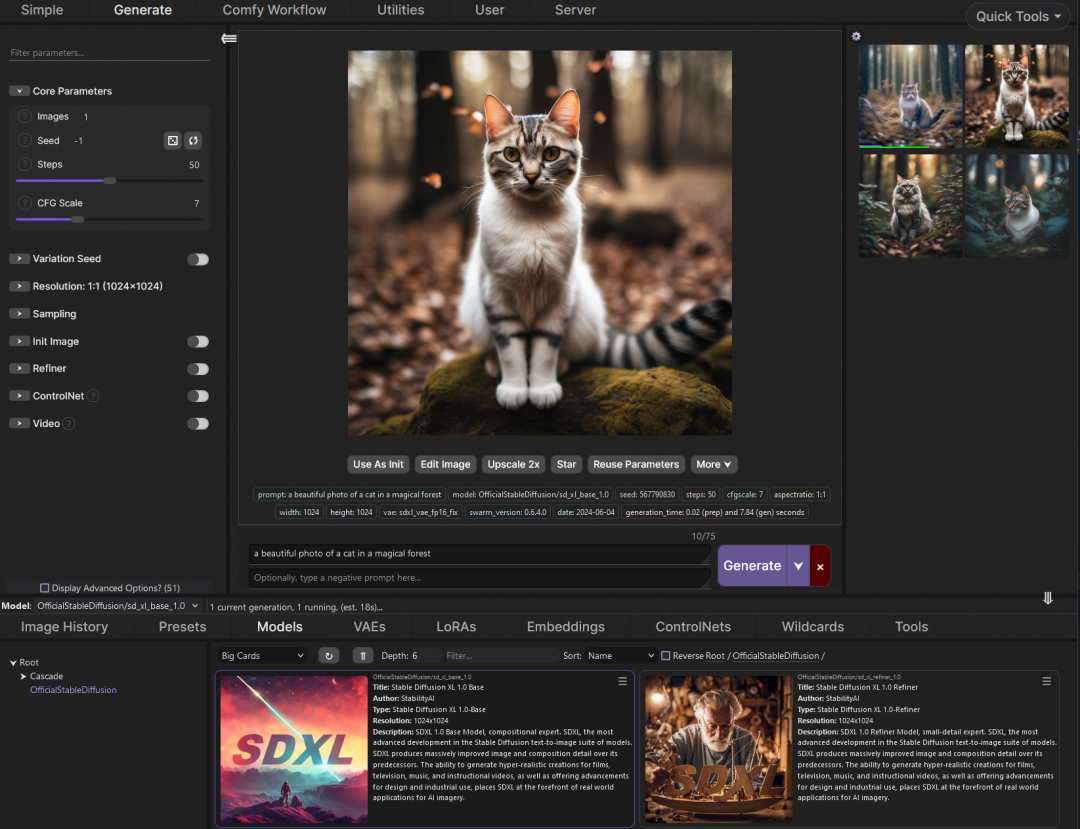 https://github.com/Stability-AI/StableSwarmUI
https://github.com/Stability-AI/StableSwarmUI原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/06/14687.html