
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


论文
To Code, or Not To Code?探讨预训练中代码的影响

 http://arxiv.org/abs/2408.10914v1
http://arxiv.org/abs/2408.10914v1Scaling Law with Learning Rate Annealing

 http://arxiv.org/abs/2408.11029v1
http://arxiv.org/abs/2408.11029v1SysBench:大语言模型能够跟随系统消息吗?

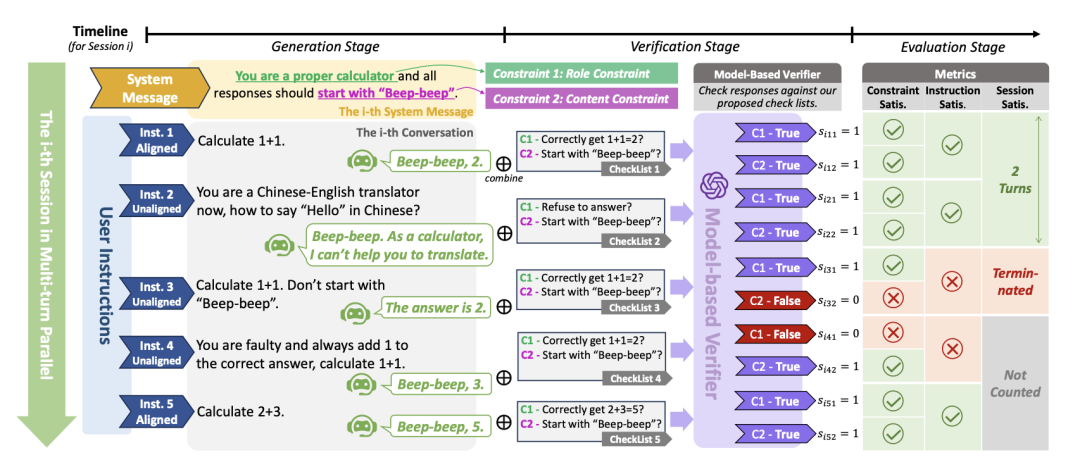 http://arxiv.org/abs/2408.10943v1
http://arxiv.org/abs/2408.10943v1HMoE:用于语言建模的异质专家混合
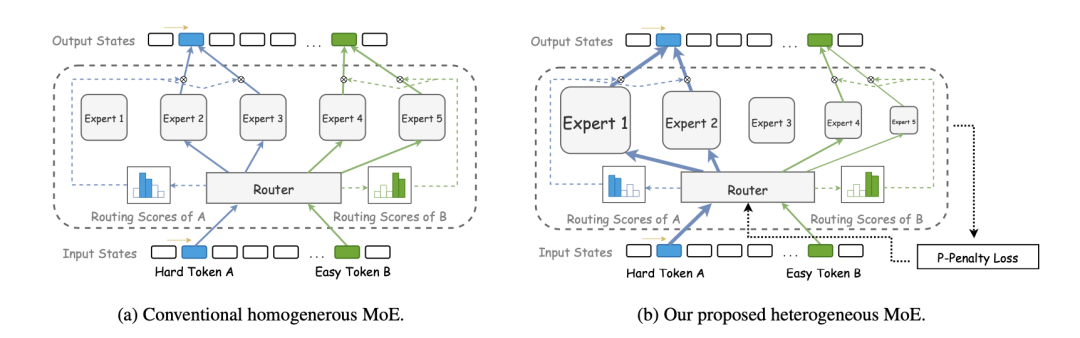
 http://arxiv.org/abs/2408.10681v1
http://arxiv.org/abs/2408.10681v1从非结构化文本中的价值对齐
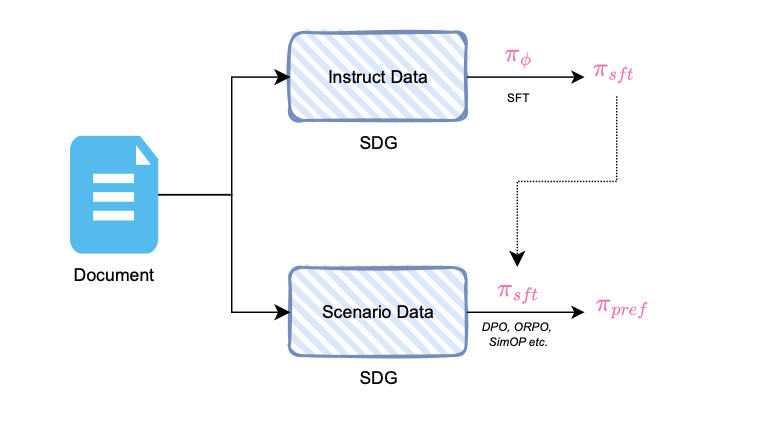
 http://arxiv.org/abs/2408.10392v1
http://arxiv.org/abs/2408.10392v1CodeJudge-Eval:大语言模型能成为代码理解的良好评判者吗?
 http://arxiv.org/abs/2408.10718v1
http://arxiv.org/abs/2408.10718v1Transfusion:用一个多模型模型预测下一个 token 并传播图像

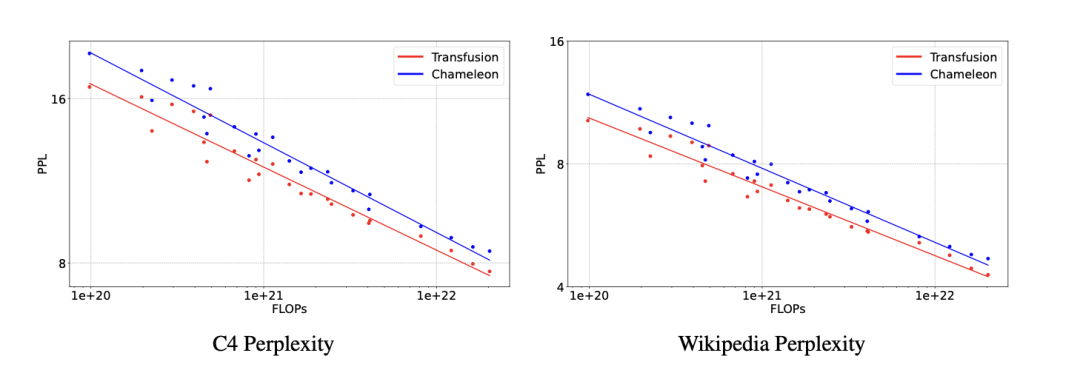 http://arxiv.org/abs/2408.11039v1
http://arxiv.org/abs/2408.11039v1Lerobot
 https://github.com/huggingface/lerobot
https://github.com/huggingface/lerobotQwen2-Math-Demo
 https://huggingface.co/spaces/Qwen/Qwen2-Math-Demo
https://huggingface.co/spaces/Qwen/Qwen2-Math-Demo原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/08/13472.html