
特别活动


我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。

学习
新兴的AI AgentOps景观:建设者的视角
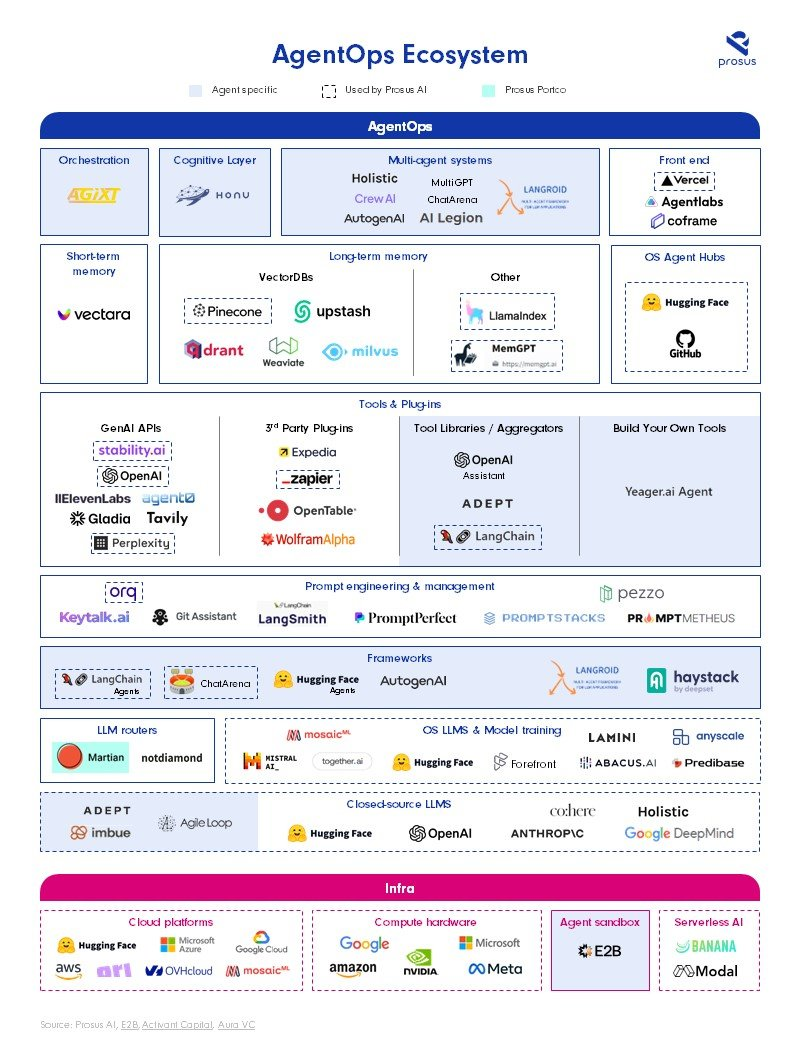 https://www.prosus.com/news-insights/group-updates/2024/ai-agentops-landscape
https://www.prosus.com/news-insights/group-updates/2024/ai-agentops-landscape原理&图解vLLM Automatic Prefix Cache(RadixAttention): 首Token时延优化
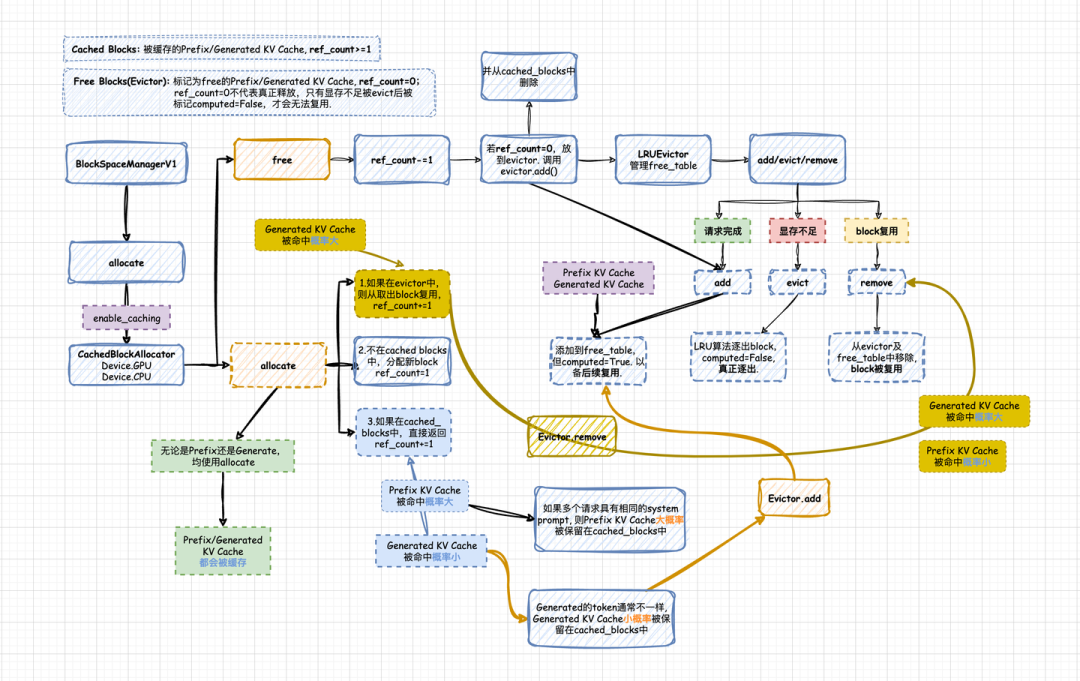 https://zhuanlan.zhihu.com/p/693556044?utm_psn=1772536403207225344
https://zhuanlan.zhihu.com/p/693556044?utm_psn=1772536403207225344Flash Attention (GPT2 implement)
forward方法中如何修改以支持Flash Attention,包括对attention_mask处理的调整以及如何封装_flash_attention_forward方法。文章还探讨了_upad_input函数的实现,以及如何使用flash_attn_varlen_func和pad_input函数处理变长序列。最后,作者提供了一个测试Flash Attention正确性的函数,并分享了初步测试结果,指出当前Flash Attention在GPT2上可能存在问题,因为引入Flash Attention后训练loss与不使用时有较大差异。 https://zhuanlan.zhihu.com/p/685695553?utm_psn=1772229392350957568
https://zhuanlan.zhihu.com/p/685695553?utm_psn=1772229392350957568StarCoder2-Instruct: 完全透明和可自我对齐的代码生成
 https://mp.weixin.qq.com/s/g2VvvKCy577XdYQKEmAXzw
https://mp.weixin.qq.com/s/g2VvvKCy577XdYQKEmAXzwPyTorch加速LLAMA3技术详解
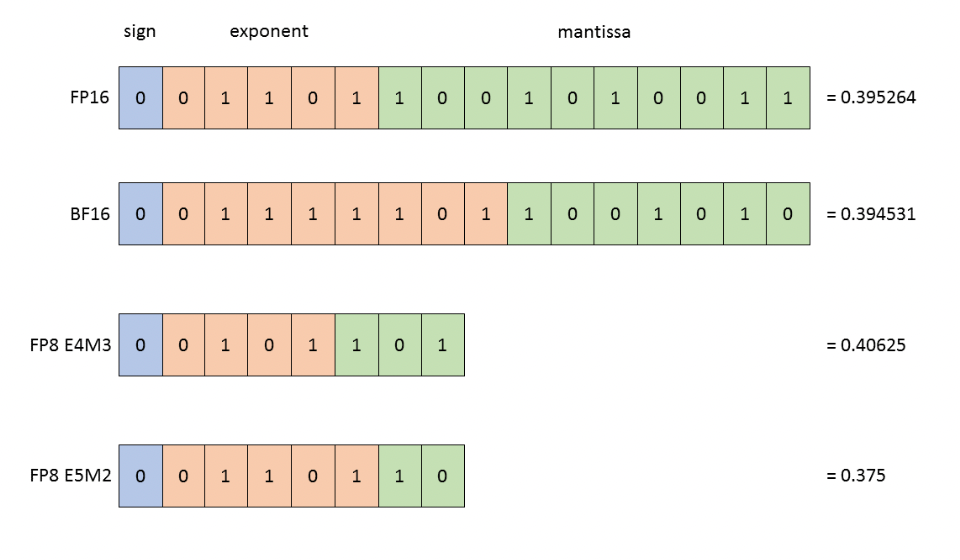 https://deploy-preview-1596–pytorch-dot-org-preview.netlify.app/blog/accelerating-llama3/
https://deploy-preview-1596–pytorch-dot-org-preview.netlify.app/blog/accelerating-llama3/[CUDA 学习笔记] GEMM 优化: 双缓冲 (Prefetch) 和 Bank Conflict 解决
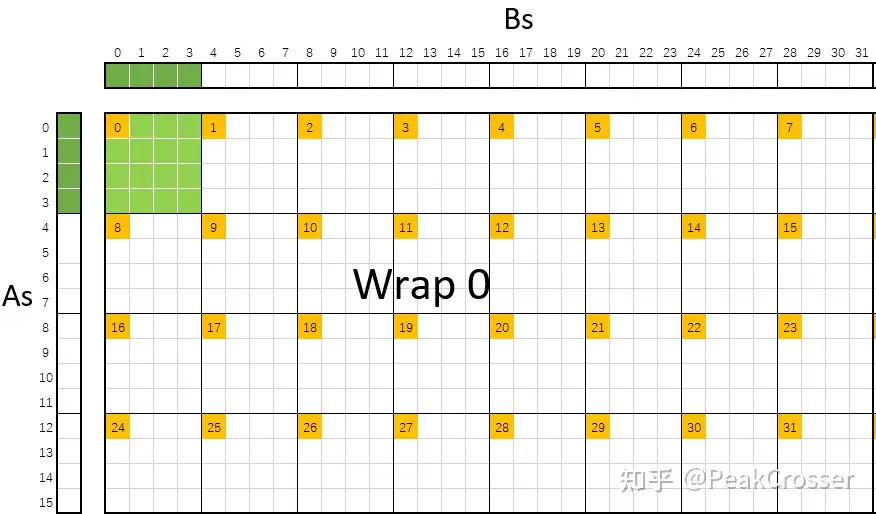 https://zhuanlan.zhihu.com/p/696844342?utm_psn=1772215247459176448
https://zhuanlan.zhihu.com/p/696844342?utm_psn=1772215247459176448Markdowner
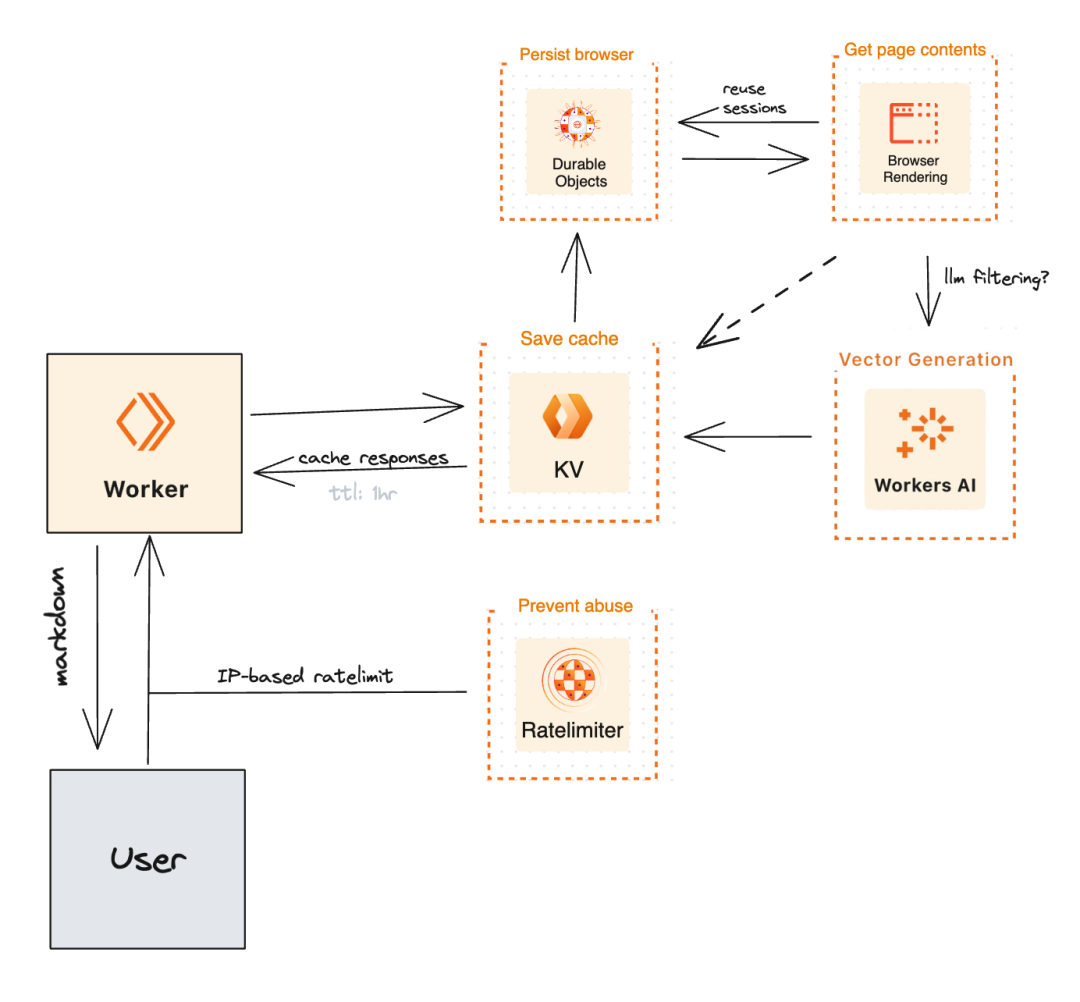 https://github.com/Dhravya/markdowner
https://github.com/Dhravya/markdownerCrawl4AI
Rill Flow
Agentcloud
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/05/15475.html