




1.1 V3/R1架构特征


1.2 R1 在CoT 的进化
1.2.1 DeepSeek-R1-Zero
1.2.2 DeepSeek-R1
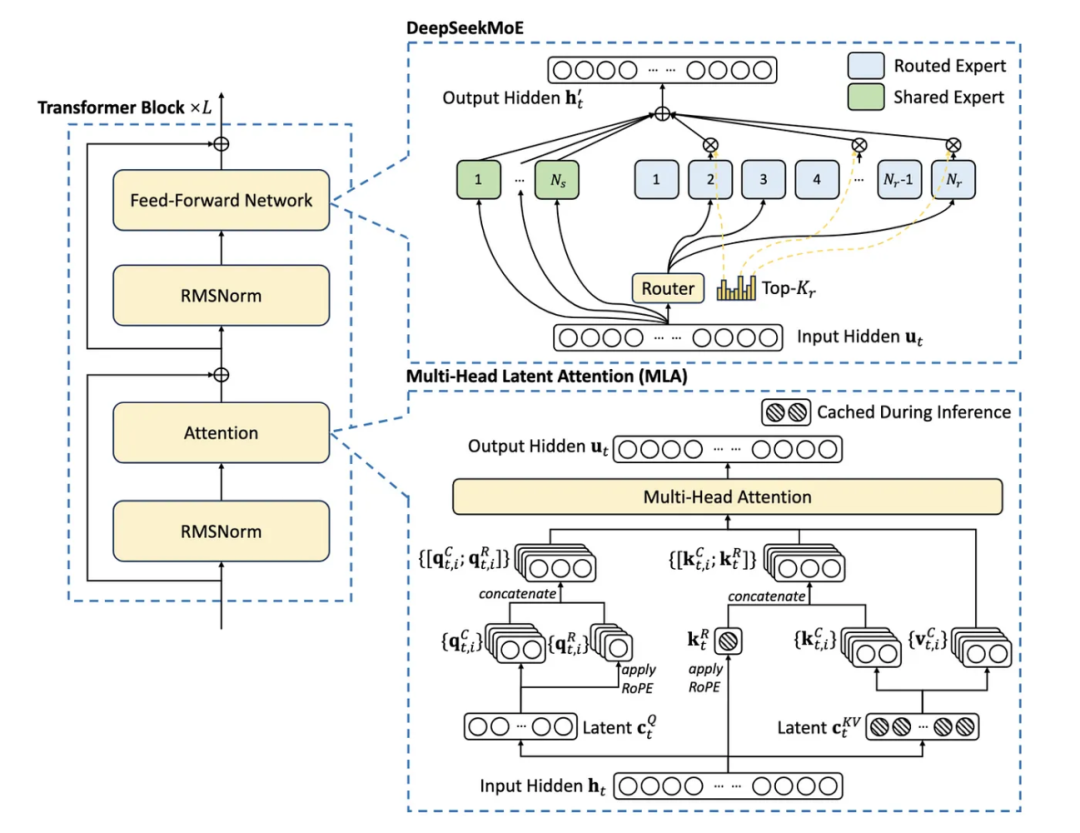
2 V3/R1的架构提升
2.1 多头潜注意力 (MLA)
2.1.1 从KV Cache(KV缓存)说起
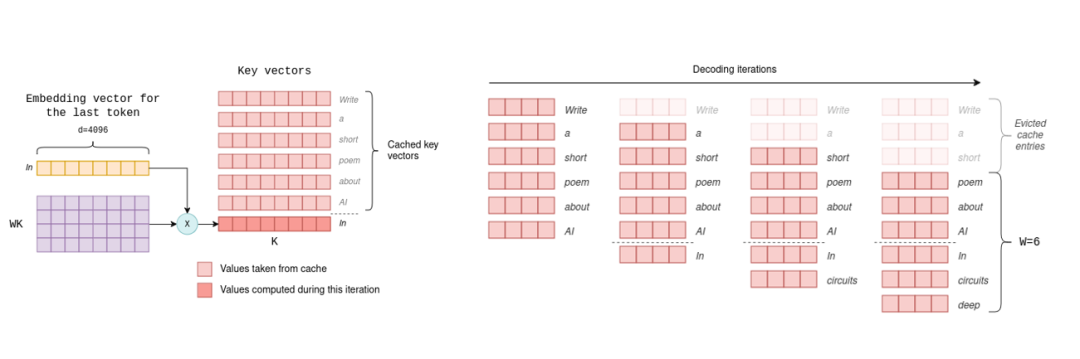

2.1.2 MLA 的原理与优势

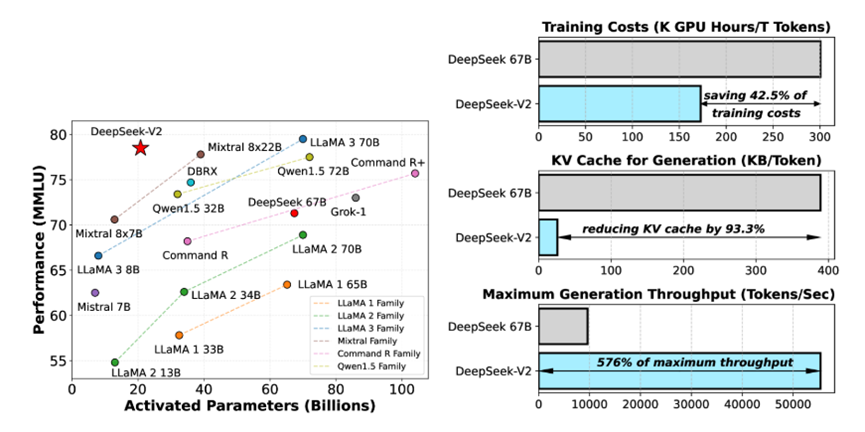
2.1.3 MLA是颠覆性创新吗?

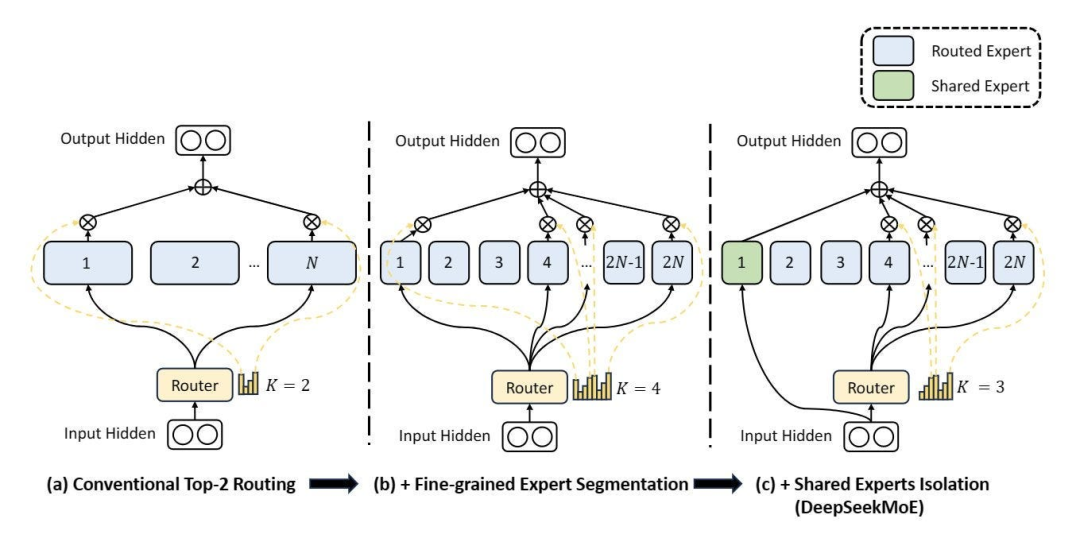
2.2 MoE 架构与辅助无损负载均衡
2.2.1 MoE 与 Dense 模型的混战

2.2.2 无辅助损耗负载均衡
2.2.3 MoE 会是大模型的终局吗?


3 V3/R1 训练架构的独特优势
3.1 HAI-LLM 框架的软硬件协同设计
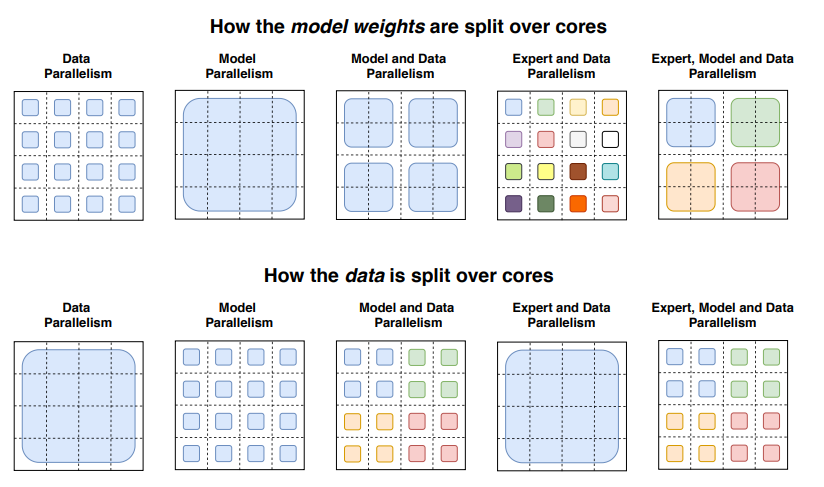
3.1.1 软件层面的并行优化
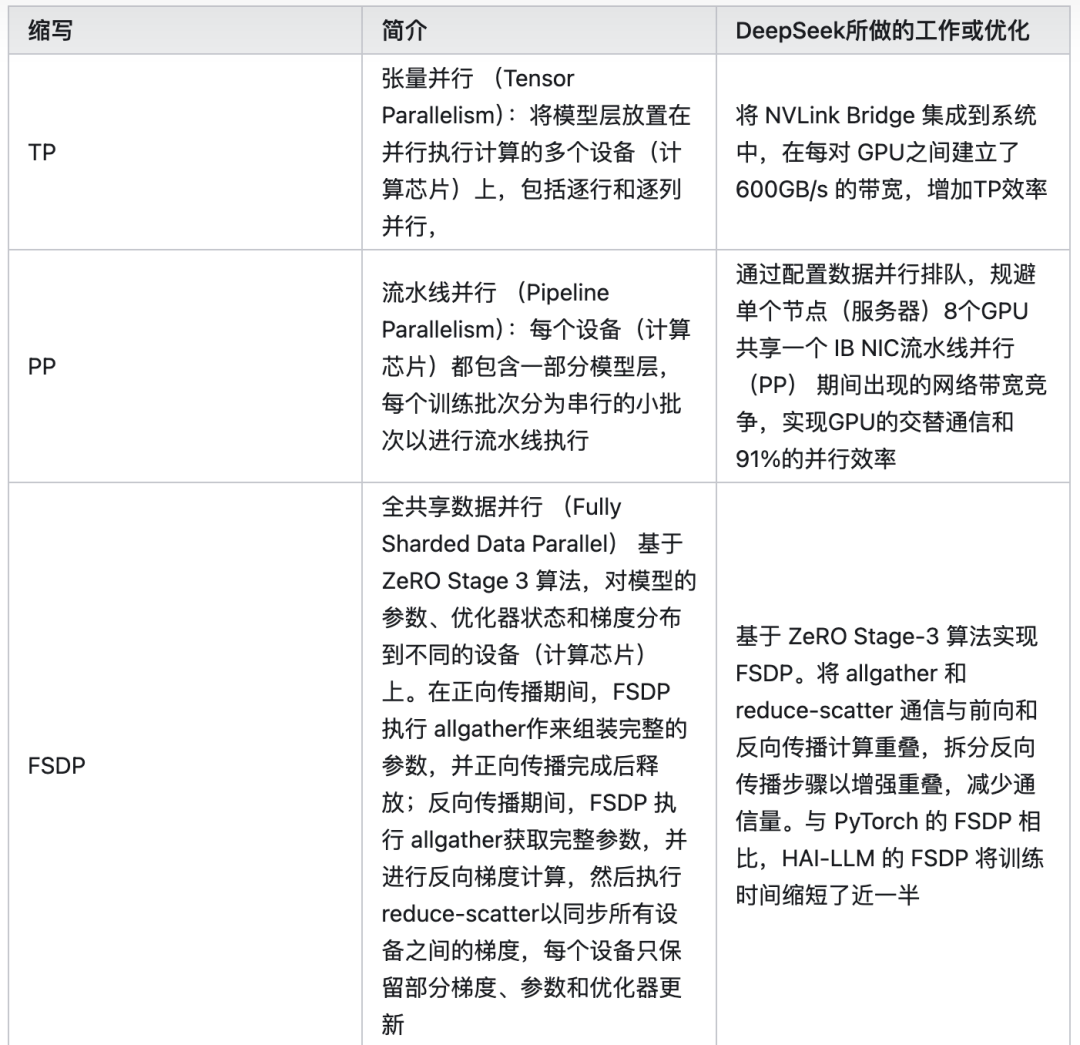
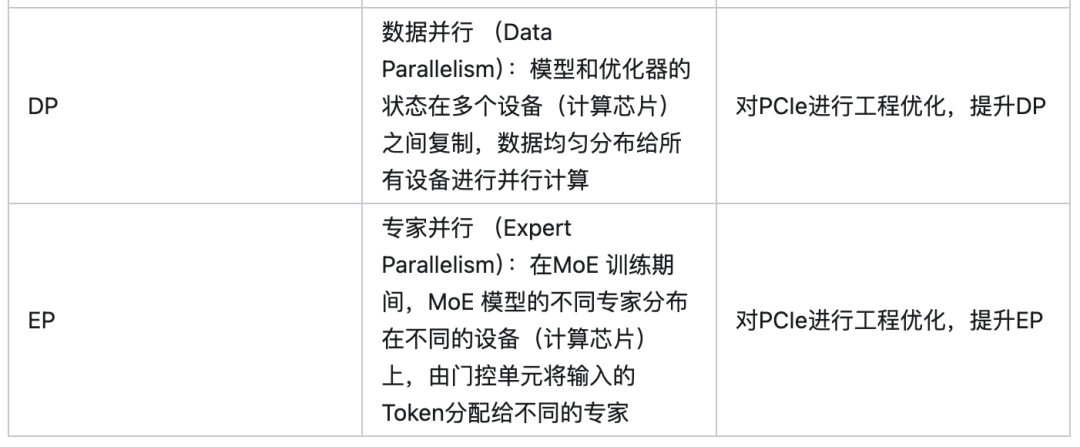
3.1.2 针对软件并行策略的硬件优化

3.1.3 针对硬件架构的软件优化
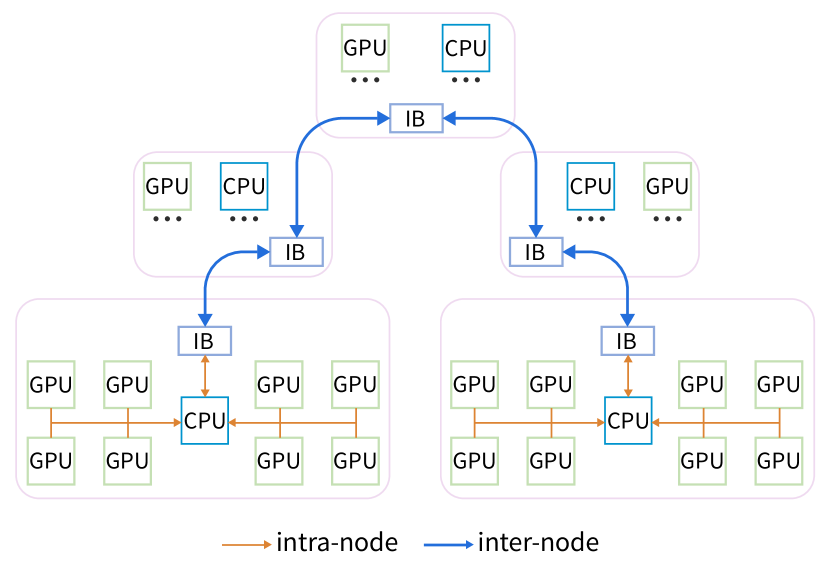
3.2 FP8 训练框架体系
3.2.1 低比特训练框架的构建
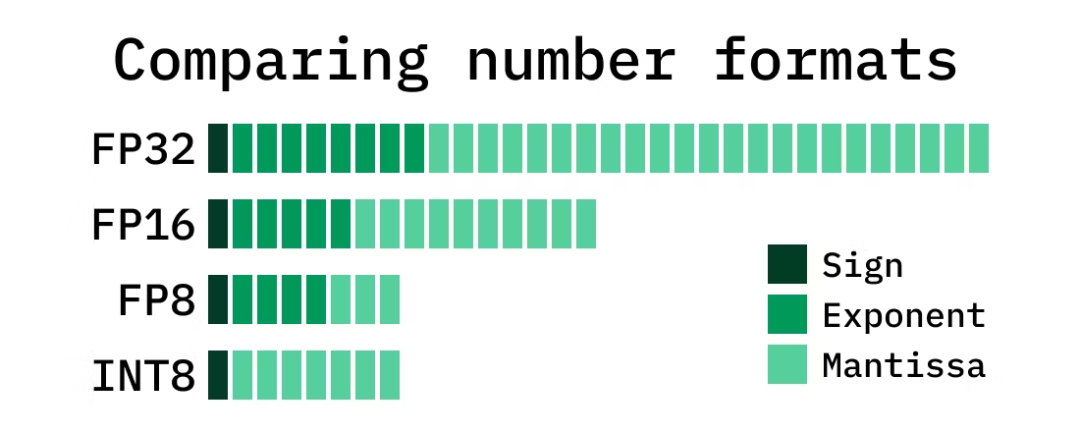

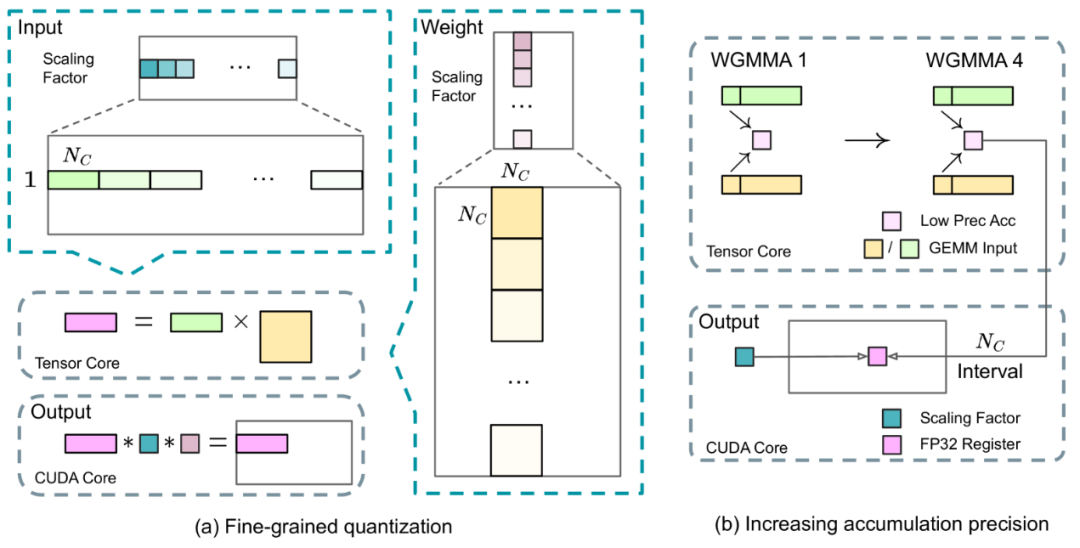
3.2.2 对英伟达 GPU 市场有巨大影响?
3.3 DualPipe 优化

3.4 跨节点 All-to-All 通信与显存优化
3.4.1 对于 SM 与 NVLink 的优化
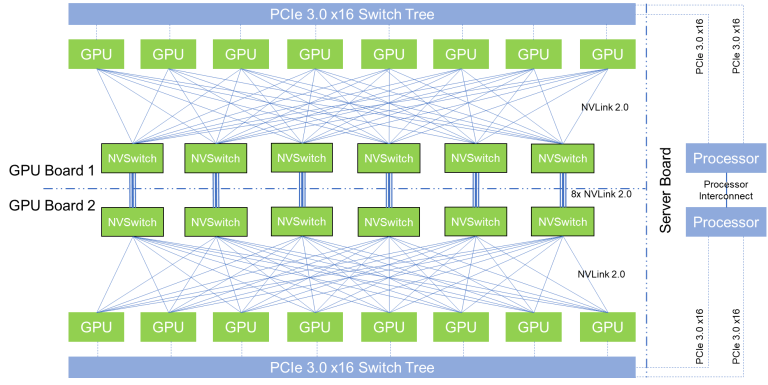
3.4.2 显存节省技术
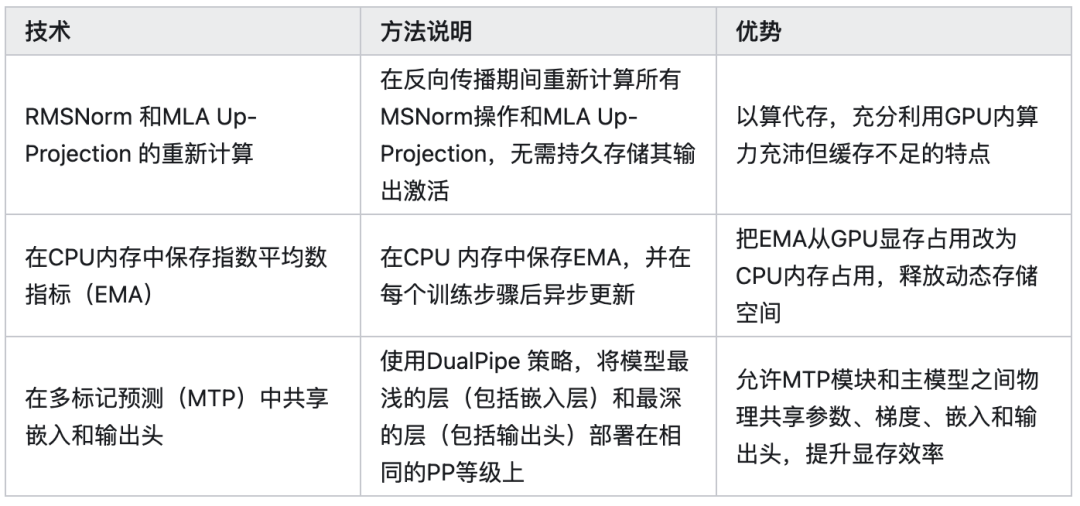
3.4.3 打破了 CUDA 生态壁垒?

3.4.4 挖了 NVLink 的墙角?
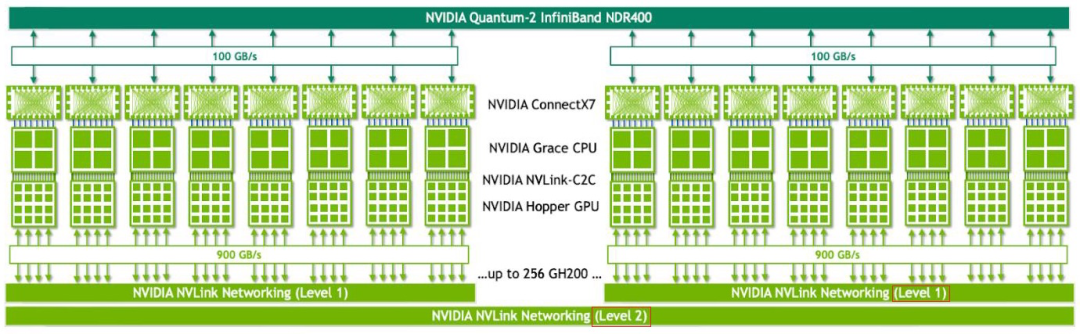
4 V3 的训练流程
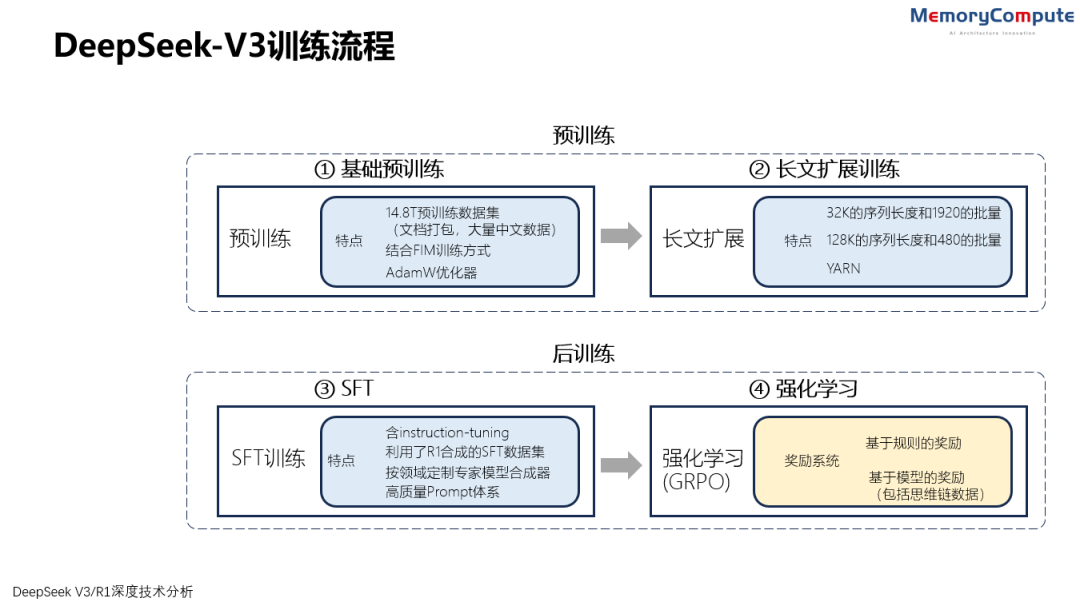
4.1 V3 的基础预训练
4.2 V3 长文扩展训练
4.3 V3 的后训练/精调
4.3.1 V3 的有监督精调(SFT)
4.3.2 V3 的强化学习

5 R1 的训练流程
5.1 无 SFT 的 R1-Zero 训练

5.2 DeepSeek-R1 的训练流程
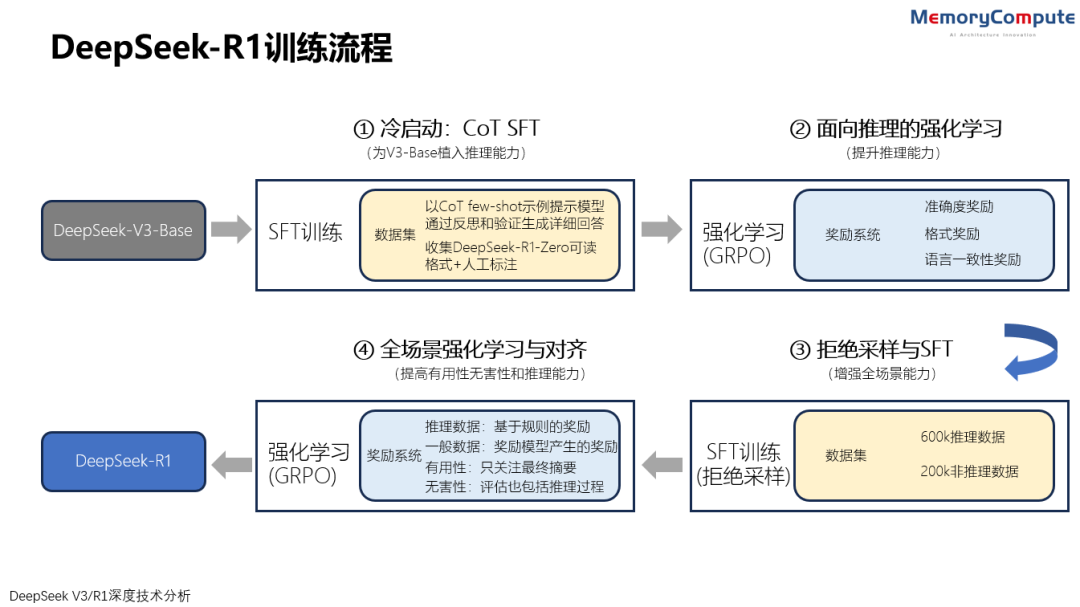
5.2.1 冷启动(Cold Start):CoT SFT
5.2.2 面向推理的强化学习
5.2.3 拒绝采样与SFT

5.2.4 面向全场景的强化学习与对齐


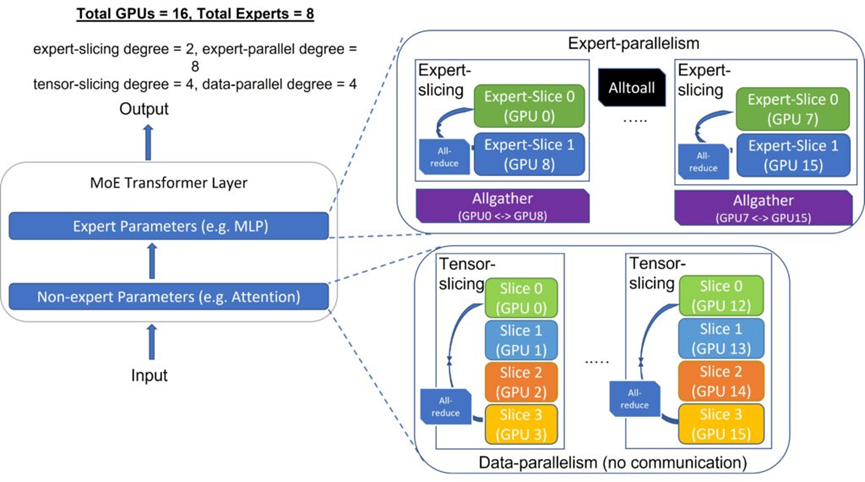
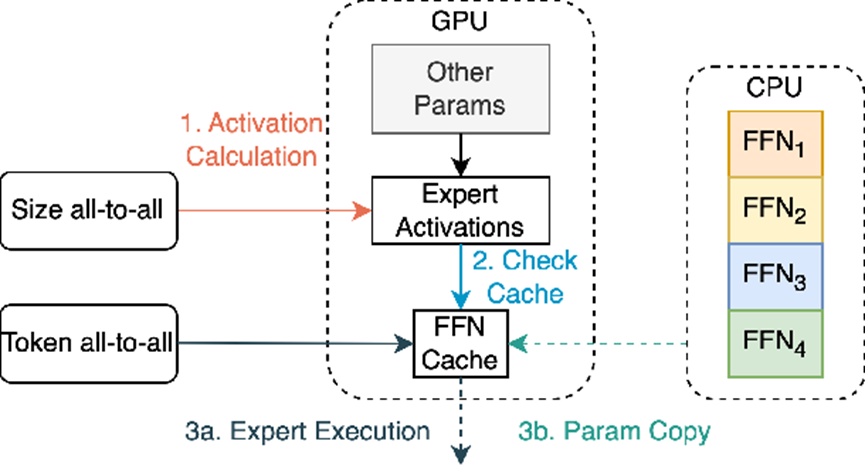
5.4 更大显存容量显得尤为重要?

6 结语
6.1 DeepSeek 的关键贡献

6.2 R1 的出现是国运级的贡献吗?
6.3 对于国产 AI 芯片的启示
DeepSeek 的进步和成果,也给国产 AI 芯片的发展提供了一些启示。
一方面,一级市场需要升级投资逻辑,不用再崇洋媚外。事实证明纯本土的研发团队,甚至是纯本土新人团队,完全由能力做出有国际影响力的成果和产品。国内算法不再死跟着老美屁股后面,国内的AI芯片也大可不必死跟着英伟达做传统 GPU。新的架构 AI 芯片,新的 GPU 架构,跨领域的技术融合,正形成新的产业窗口。


原创文章,作者:特工宇宙,如若转载,请注明出处:https://www.agent-universe.cn/2025/02/38335.html