
MOLAR NEWS
2021年第3期
MolarData人工智能每周见闻分享,每周一更新。
10亿参数,10亿张图!Facebook新AI模型SEER实现自监督学习,LeCun大赞最有前途
Facebook宣布了一个在10亿张图片上训练的AI模型——SEER,是自监督(Self-supervised)的缩写。


SEER模型结合了最近的架构家族「RegNet」和在线自我监督训练「SwAV」来规模训练数具有10亿参数的数十亿张随机图像。
科研团队改编利用了一种新算法,称为SwAV。它起源于FAIR的研究,后被应用于自我监督学习。

SwAV 使用在线聚类方法来快速分组具有相似视觉概念的图像,并且能利用图像的相似性改进自我监督学习的先进水平,而且训练时间减少了6倍。
这种规模的训练模型还需要一个在运行时间和内存方面都效率很高的,又不会损失精确性的模型架构。

幸运的是,FAIR 最近在架构设计领域的一项创新催生了一个称为 RegNets 的新模型家族,它完全符合这些需求。
RegNet 模型能够扩展到数十亿甚至数万亿个参数,可以优化这些参数以适应不同的运行时间和内存限制。
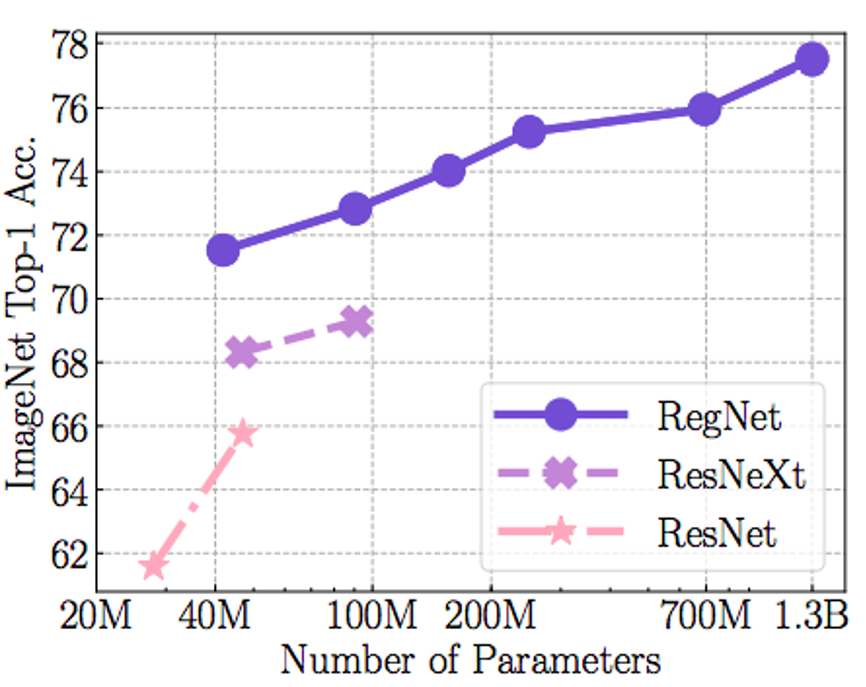
科研团队对比了SEER在随机IG图像上的预训练和在ImageNET上的预训练,结果表明非监督特性比监督特性平均提高了2%。
为SEER技术添上最后一块砖的是VISSL自我监督学习通用库。VISSL通过整合现有的几种算法,减少了对每个GPU的内存需要,提高了任意一个给定模型的训练速度,从而实现了大规模的自我监督学习。
来源:新智元
提速20倍!谷歌AI发布TensorFlow 3D,智能汽车场景亲测好用
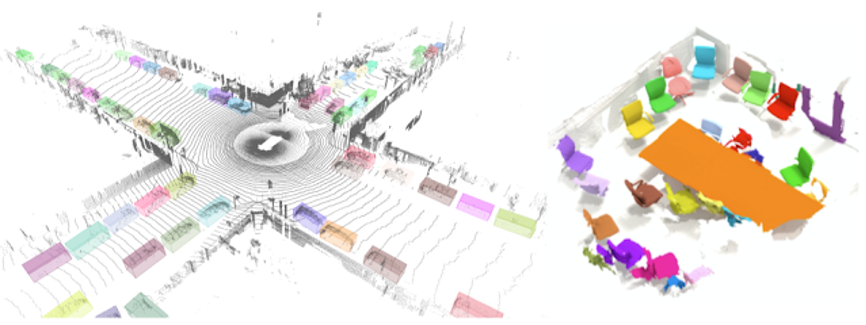
为了进一步提高对3D场景的建模,简化研究人员的工作,Google AI发布了TensorFlow 3D (TF 3D) ,一个高度模块化、高效的库,旨在将3D深度学习能力引入TensorFlow.
TF 3D提供了一系列当下常用的操作、损失函数、数据处理工具、模型和度量,使更多的研究团队能够开发、培训和部署最先进的3D场景理解模型。
TF 3D包含用于最先进的3D语义分割、3D目标检测和3D实例分割的培训和评估任务,还支持分布式训练。
另外,TF 3D还支持其他潜在的应用,如三维物体形状预测、点云配准和点云增密。此外,它提供了一个统一的数据集规范和训练、评价标准三维场景理解数据集的配置。
目前,TF 3D支持Waymo Open、 ScanNet和Rio数据集。
然而,用户可以自由地将其他流行的数据集,如NuScenes和Kitti,转换成类似的格式,并将其用于已有或自定义的pipeline模型中,还可以利用TF 3D进行各种3D深度学习研究和应用,从快速原型设计到部署实时推理系统。
 来源:新智元
来源:新智元
华为云IEEE TPAMI论文解读:规则化可解释模型助力知识+AI融合
华为云联合中科院计算所发表的论文《What is a Tabby? Interpretable Model Decisions by Learning Attribute-based Classification Criteria》
通过利用物体类别之间存在的层级关系约束,自动学习从数据中抽取识别不同类别的规则,一方面对模型的预测过程进行解释,另一方面也提供了一条引入人工先验知识的可行途径。
实际中,由于类别数量巨大、海量属性难以定义,不可能通过人工的方式对每个类别的属性进行定义。那么有什么方法可以在不对数据进行额外标注的情况下实现类似的分类方式呢?

具体来说,作者在提出的方法中设计了一个包含两条分支的模型,如图 2 所示。上边的分支以图像作为输入,主要作用是学习属性;下边的分支以层级结构作为输入,主要作用是对学习属性的过程施加约束:
其中上边的分支使用常见的卷积神经网络 backbone,上边分支的输出是一个 1×D 维的「属性向量」,向量中的每一维表示一个属性,每一维的值则表示图像样本是否具有这个属性(0 表示样本不具有这个属性,大于 0 的值表示样本具有这个属性),同时当激活值大于 0 时,激活值的大小表示图像样本在这个属性上的强度;
下边的分支按照类别间属性数量的约束关系,学习类别层级结构中每个类别的属性表示形式。
来源:机器之心
量子NLP已来?一英国创企:实现迄今最大规模量子自然语言处理
英国时间2021年3月2日,一家名为Cambridge Quantum Computing (下文简称CQC)的创企宣布,他们在量子计算机上实现了有史以来最大规模的量子计算自然语言处理任务。
CQC团队使用了两种不同的数据集。第一个数据集含130个句子,由一个简单的无上下文语法自动完成,一半的句子与食物有关,一半的句子与食物有关,面向二元分类任务。另一个数据集含105个名词短语,提取自RELPRON数据集。而模型的目标是,预测名词短语是否包含基于主语或基于宾语的相对从句,即再次执行二进制分类任务。
来源:新智元
AI资讯
掌握最新时事新闻
长按扫码关注我们

原创文章,作者:整数智能,如若转载,请注明出处:https://www.agent-universe.cn/2021/03/8455.html