我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
学术分析报告:ResearchFlow — 奇绩F23校友的开发的深度研究产品,PC端进入RFlow的分析报告,可直接点击节点右侧的小数字展开节点,登录后可在节点上直接“询问AI”,进一步探索深度信息
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


信号
Parallelized Autoregressive Visual Generation
自回归建模在语言建模中的成功启发了其在视觉生成中的应用。传统的自回归视觉生成方法通常依赖于逐个标记的顺序生成,这导致生成速度较慢,限制了实际应用。为了提高生成效率,本研究提出了一种新的方法,通过并行生成弱依赖标记,同时保持对强依赖标记的顺序生成,从而加速视觉生成过程并保持生成质量。
在语言建模中,已有通过投机解码和雅可比解码等方法实现的并行生成,但在视觉生成中,现有的非自回归方法和多尺度预测方法要么增加了模型复杂度,要么牺牲了灵活性。本研究的创新之处在于,提出了一种能够在保持标准自回归模型简洁性和灵活性的同时实现视觉生成并行化的方法。我们通过分析视觉数据中的标记依赖性,发现空间上距离较远的标记通常具有较弱的依赖性,因此可以并行生成,而相邻标记则需要顺序生成以避免生成不一致。基于这一观察,我们将图像划分为局部区域,先生成各区域的初始标记以建立全局上下文,然后通过识别并组合空间上远离的标记进行并行生成。
这一方法通过重新排序机制无缝地集成到标准自回归变换器中,能够在不同空间区域之间进行并行生成,同时保持全局上下文的建模能力。通过这种非局部并行生成,模型显著减少了推理步骤,提高了生成速度。实验证明,在ImageNet和UCF-101数据集上的图像和视频生成任务中,我们的方法不仅在生成质量上与基准方法相当,而且在生成速度上实现了3.9倍的步骤减少和3.6倍的推理时间加速,甚至在更激进的并行化下,步骤减少可达到11.3倍,推理速度加速9.5倍,质量损失极小(FID小于0.7,FVD小于10)。实验表明,我们的方法在不同视觉任务中的有效性,并且与多种标记化方法兼容。
https://arxiv.org/abs/2412.15119
ResearchFlow链接:https://rflow.ai/flow/f8639114-4be9-4183-970e-acbc2eb5e597
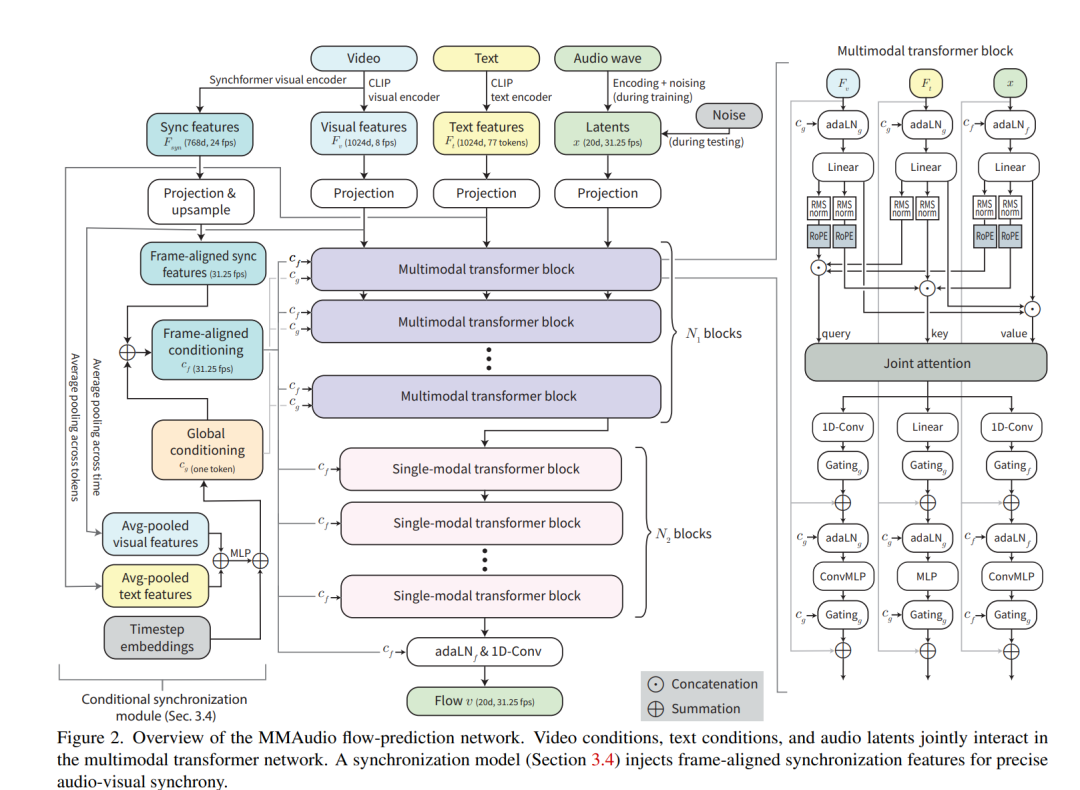
Taming Multimodal Joint Training for High-Quality Video-to-Audio Synthesis
本研究提出了一种新颖的多模态联合训练方法——MMAudio,用于视频到音频的生成。我们关注于Foley音效合成,即为给定的视频合成环境音(如雨声、河流声)和由可见事件引发的音效(如狗叫声、网球拍击球声)。与传统方法不同,Foley音效合成不涉及背景音乐或人声,而是强调语义和时间上的一致性。具体而言,语义一致性要求理解场景及其与音频的关联,而时间一致性要求音频与视频的同步性,因为人类能够察觉到仅25毫秒的音视频不匹配。
现有的视频到音频方法通常要么仅在音视频数据上训练,受限于数据量(如VGGSound数据集仅包含550小时视频),要么通过在预训练的文本到音频模型中增加控制模块来利用大规模音频文本数据的知识。尽管这种方法通过控制模块改善了效果,但它增加了网络复杂性,并且不清楚预训练的文本到音频模型是否能支持所有的视频到音频场景。
为了解决这些局限性,本文提出的MMAudio方法通过在单一的变换器网络中同时考虑视频、音频和文本的联合训练,并在训练过程中屏蔽缺失的模态。这种方法能够从头开始训练,利用音频视觉和音频文本数据集,并通过联合训练构建统一的语义空间,从而促进了自然音频分布的学习。实验表明,MMAudio在音频质量、语义一致性和时间一致性上均取得了显著提升,音频质量相比基准方法提高了10%,语义一致性提高了4%,时间同步性提高了14%。
此外,为了进一步提高时间一致性,我们提出了一种条件同步模块。该模块利用自监督音视频解同步检测器提取的高帧率视觉特征,并在自适应层归一化(adaLN)层的尺度和偏置空间内进行操作,从而实现更精确的音视频同步(同步性得分提高了50%)。这一创新模块有效解决了仅使用注意力层在音视频信号中指示精确时序的问题。
https://arxiv.org/abs/2412.15322
ResearchFlow链接:https://rflow.ai/flow/9b15552c-ea00-46bc-874e-040d61f5e0e
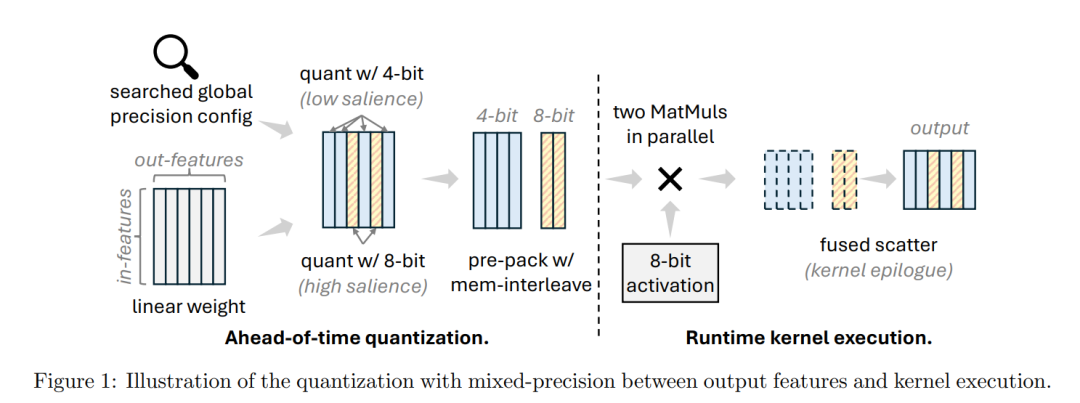
MixLLM: LLM Quantization with Global Mixed-precision between Output-features and Highly-efficient System Design
LLMs在多种任务中取得了显著成绩,但其庞大的内存消耗和计算成本已成为高效部署的障碍。量化技术通过以较低的比特宽度表示权重或激活来压缩LLM,成为减少其大小的有效解决方案。然而,现有的量化方法仍存在精度下降或系统效率低下的问题。量化效率的优化涉及精度、内存消耗和系统执行效率之间的平衡,我们称之为量化的“有效性三角”。现有的量化方案在这三者之间有不同的侧重点和权衡。
现有方法中,权重量化方法解决了内存消耗问题,并能加速小批量解码的执行,但对于精度要求较高的生产任务(例如4-bit量化可能导致的精度下降),以及在大批量工作负载中的系统性能降低,依然存在挑战。权重激活量化方法通过对激活进行低比特量化来提高系统效率,但其精度下降较为严重,且会增加去量化的开销,影响系统效率。使用异常值分离和混合精度技术的方案试图通过不同的精度分配来提高低比特量化的精度,但其系统效率和精度提升仍然有限。
为了解决这些问题并平衡三者的需求,本文提出了MixLLM。MixLLM通过以下贡献解决了现有方法的不足,并有效优化了量化过程:
首先,MixLLM在权重量化中采用了输出特征的混合精度量化,基于全局显著性识别,为不同的输出特征(即输出通道)使用不同的比特宽度。对于显著性较高的输出特征,采用8-bit量化;对于其他输出特征,则采用4-bit量化。这种全局显著性识别方法超越了以往基于单层估计的显著性方法,能够更精准地根据不同层次的重要性调整量化配置。此外,MixLLM的混合精度量化设计比输入特征的量化更容易实现,因为输出特征的计算通常是互不干扰的子问题。
其次,MixLLM还通过量化配置和GPU内核优化的联合设计,实现了精度与系统效率的双重提升。MixLLM使用8-bit量化激活,因为这种配置能够保持较好的精度。由于矩阵乘法执行通常更多地受到较大权重张量的限制,而不是较小激活张量的限制,因此减少激活的量化精度并不显著影响系统效率。MixLLM在8-bit量化和4-bit量化上采用对称量化和非对称量化配置,以保持良好的精度。为了优化系统效率,MixLLM采用了两步去量化策略,并利用快速的int8张量核心和整数浮点转换来减少去量化的开销。
https://arxiv.org/abs/2412.14590
ResearchFlow链接:https://rflow.ai/flow/0ee55b23-44e7-47ce-b8d0-febe3bdf9e74
HuggingFace&Github
ChatGPT 屏幕 功能提升
📜 在单个页面上查看多步骤说明或长食谱,以便于参考
🖥️ 以更美观的格式欣赏原创歌词、诗歌、散文或作曲
⚙️ 自定义功能,例如更大的聊天框和隐藏的页眉/页脚,以获得更宽敞的视图
🌐 适用于:chatgpt.com + perplexity.ai + poe.com
https://github.com/adamlui/chatgpt-widescreen
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/12/29073.html