我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
学术分析报告:ResearchFlow — 奇绩F23校友的开发的深度研究产品,PC端进入RFlow的分析报告,可直接点击节点右侧的小数字展开节点,登录后可在节点上直接“询问AI”,进一步探索深度信息 如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢 迎 大 家 一 起 交 流 !
潜空间活动报名
本期活动将在11月9日 10:00开始,我们邀请到的嘉宾是鱼哲,Lepton AI 创始成员,曾在阿里云担任高性能 AI 平台产品负责人,专注于 AI 在多个行业的落地及应用。Lepton AI 致力于建立高效可用的AI 基础设施,让团队更关注于应用构建及落地。在本次分享中鱼哲将带来关于不同AI产品形态对团队的挑战相关的思考,分享主题《Beyond Infra,What matters?—— 不同AI产品形态对团队的挑战》。除嘉宾分享外,每期设置了【匹配合伙人 Cofounder Matching】环节。你可以和 GenAI 时代最有活力的创业者和研究者线下面对面交流,将有机会找到志同道合、有共同创业梦想的小伙伴。报名通道已开启,欢迎扫描下方二维码报名。
资讯
交付“开箱即用”的AI数据中心、租用AI芯片设计师为自己工作 计算的指数级增长: NVIDIA的目标是在未来十年内, 每年将计算性能(以数据中心规模衡量)翻倍或三倍,同时将成本和能耗降低一半或三分之一。这将导致一种“超摩尔定律”的增长曲线。 实现这一目标的关键在于协同设计(co-design)和数据中心规模的计算。 协同设计和全栈方法: 为了实现指数级增长,NVIDIA 采用协同设计方法,即同时优化算法和架构。这包括在不同精度级别(FP64到FP4)之间进行切换,以及将网络作为计算结构的一部分。 数据中心规模的计算: NVIDIA 将网络视为计算结构,并通过技术如NVLink,将数百个GPU整合为一个虚拟GPU,从而实现极低的延迟和高吞吐量,平衡了这两个通常相互冲突的需求。 他们将数据中心视为计算的基本单元,并构建了全面的、垂直整合的数据中心解决方案。 训练和推理基础设施的可互换性: 为训练构建的基础设施同样适用于推理。 大型模型用于训练和知识蒸馏,从而产生更小、更高效的模型,用于特定任务。 CUDA生态系统和软件生产力: CUDA提供了稳定的基础,允许在软件层面上快速迭代。NVIDIA致力于维护其软件,确保其在不同硬件和平台上的兼容性,从而最大限度地提高软件开发者的生产力。 快速部署大型AI集群的能力: NVIDIA展示了其为xAI快速部署一个拥有10万个GPU的超级集群的能力,这得益于其在供应链、软件集成和数字孪生方面的预先规划和准备工作。 未来超级集群的挑战: 构建更大规模的超级集群(例如,20万、50万甚至100万个GPU)将面临能源、供应链和资本等多重挑战。然而,NVIDIA 认为这些挑战并非不可克服。 AI对科学和工程的影响: AI和机器学习正在彻底改变各个科学和工程领域,从芯片设计到材料科学、生物技术等。NVIDIA认为AI正成为这些领域中发现和创新的基础。 AI芯片设计: AI已经成为芯片设计的关键工具,能够探索比人工设计更大的设计空间,并找到更好的局部最优解。 NVIDIA的未来:从电脑到工厂: NVIDIA已经从简单的电脑制造商转型为构建“AI工厂”的企业,生产用于各种应用的“智能”——无论是机器人、软件还是其他形式的智能。 这种转型将对各个行业产生深远的影响。 AI的具身化: NVIDIA 认为,AI和机器人技术即将融合,创造出例如自动驾驶汽车和具身机器人等应用,并最终实现更广泛的AI具身化。 AI员工的出现: 未来,AI将成为各种角色的“员工”,协助人类工作,从营销到供应链管理等各个领域。这些观点共同描绘了NVIDIA对未来AI和计算的愿景,强调了指数级增长、协同设计、数据中心规模计算、以及AI对各个行业和科学领域变革性影响的重要性。 https://mp.weixin.qq.com/s/DsfIOj6qzDuYd3bU_Zmn0A
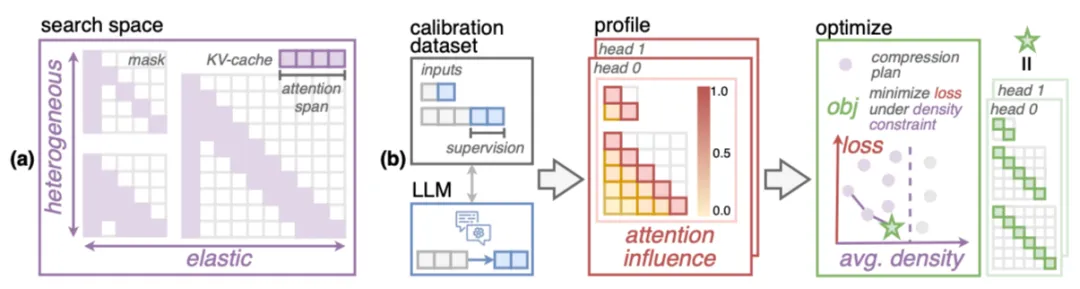
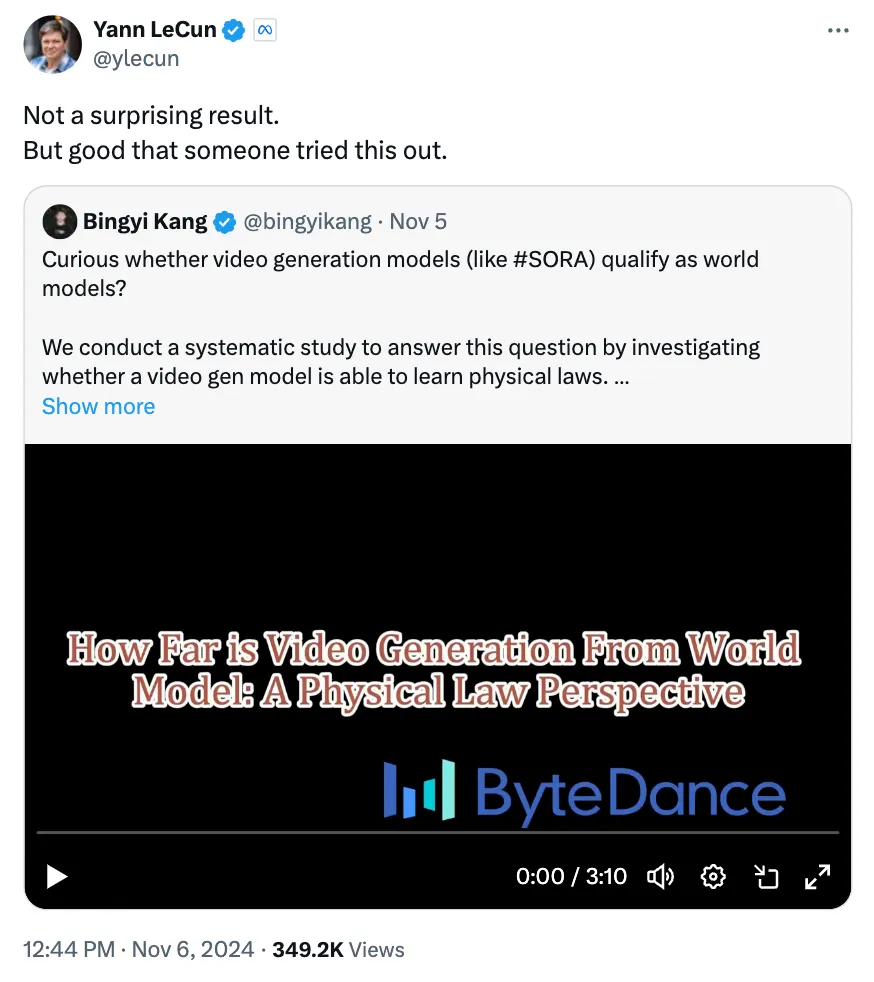
无问芯穹提出混合稀疏注意力方案MoA 随着长文本需求增加,大语言模型的注意力机制面临高计算成本和内存压力。传统稀疏注意力采用统一的稀疏模式,但难以适应各注意力头的不同需求,影响长文本处理效果。清华大学等团队提出的混合稀疏注意力(MoA)创新性地为不同注意力头配置独特稀疏模式,在保持25%注意力密度下实现接近100%上下文记忆力,大幅优化内存和计算资源利用。 MoA通过自动搜索最优稀疏策略,提高长文本信息检索的准确性和效率,相较基线方法,其在同等注意力密度下性能下降小于5%。MoA在Vicuna-7B和Llama-3-8B等模型上提高了检索和理解长文本的精度达1.5至7.1倍。其异质弹性规则的动态适配增强了长文本泛化能力,在12K输入长度下的压缩方案可延伸至256K长文本上,高效且精准。 MoA也显著提高运行效率,配合CUDA优化后,相较FlashAttention2和vLLM,MoA在7B和13B模型的解码吞吐量提升达6.6-8.2倍和1.7-1.9倍。 类Sora模型能否理解物理规律? 字节豆包大模型团队的一项系统性研究,针对视频生成模型是否理解物理规律进行了深入实验。该研究通过基于DiT架构的视频生成模型,分析了模型是否能抽象出并泛化物理规则。实验发现,尽管扩大模型参数和数据量会在分布内泛化(ID)中有所改进,但模型依然无法理解并应用物理定律,尤其在分布外泛化(OOD)场景中表现较差。 实验中,团队利用物理引擎生成了匀速直线运动、弹性碰撞和抛物线运动等经典物理场景,用于训练视频生成模型,并验证其生成视频是否符合经典物理学定律。模型的泛化能力在三种场景中得到测试:分布内泛化(ID)、分布外泛化(OOD)和组合泛化(Combinatorial Generalization)。
分布内泛化(ID):模型学习了与训练数据相同的物理场景,能够较好生成符合物理规律的视频,随着模型规模和数据量增加,生成结果与物理规律越来越接近。
分布外泛化(OOD):当模型遇到从未见过的新场景时,生成的视频无法遵循物理定律,且扩展数据量和模型规模的影响有限,表明模型在推理新的物理场景时缺乏能力。
组合泛化:在包含多个物体和交互的复杂场景中,随着训练模板数目的增加,模型的泛化能力提升,生成视频的质量和物理一致性也得到改善。
记忆和模仿依赖:模型的行为主要依赖于记忆和对训练数据中的类似场景的模仿,而非抽象理解物理规律。特别是在速度和方向等属性上,模型倾向于模仿训练集中出现的情境,而非理解物理法则。
组合泛化能力:尽管模型可以处理不同物体间的组合与交互,但其能力仍受限于对底层物理规律的理解。扩展数据集和训练模板可以提升组合泛化,但仅依赖于这些方法并不能确保生成符合物理规律的视频。
视频表征局限性:模型在生成细粒度物理行为时存在误差,特别是在物体尺寸非常接近像素级别时,模型的判断能力受到视觉模糊性的影响,无法准确预测物理交互。
https://mp.weixin.qq.com/s/Mwt-NuGPUcsLSNPxxapdAA
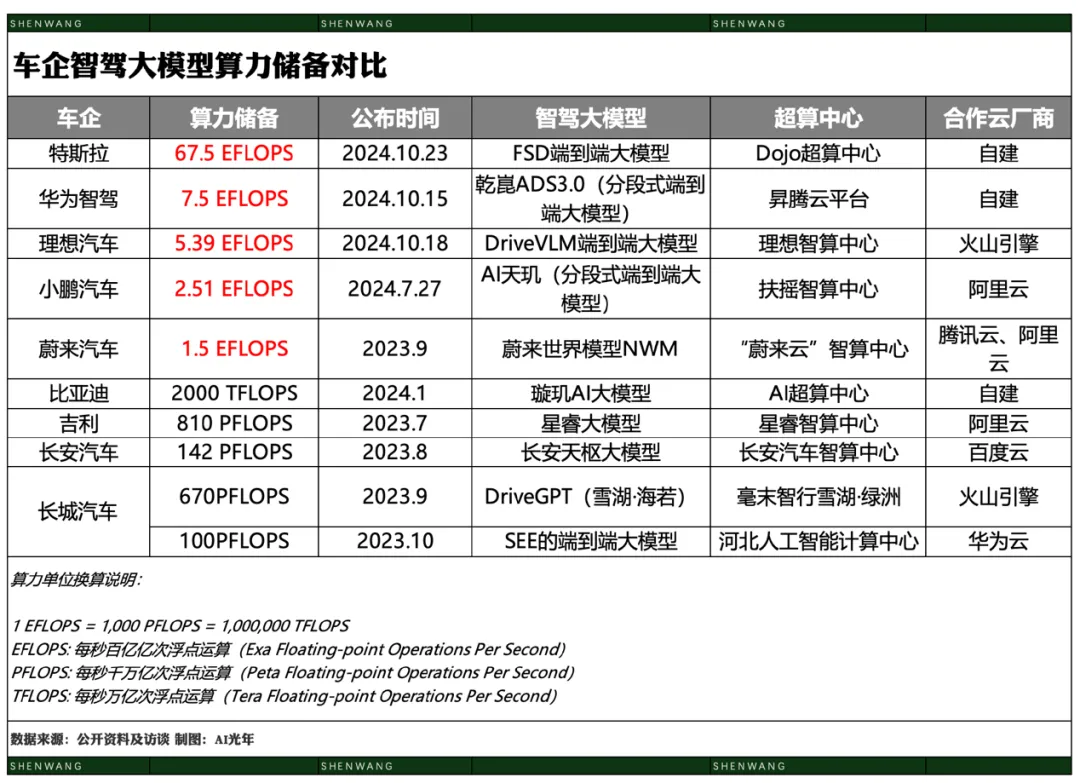
汽车厂商“批量生产”大模型 汽车行业正处于电动化向智能化转型的关键阶段,纷纷涉足大模型技术,试图提升竞争力。然而,目前车企大模型的应用场景有限,难以达到互联网公司级别的Token使用量。以抖音等大模型公司为例,其每日Token使用量远超车企,显示出大模型在汽车行业的需求尚未充分释放。 当前,智能化的核心在于车内智能座舱和自动驾驶,两者对算力需求高。特斯拉引领算力布局,其100 EFLOPS的目标超越大多数车企的总算力。国内车企如比亚迪、蔚小理等也在积极扩充算力,部分依赖于云服务商如阿里云和火山引擎,后者在与车企合作中迅速崛起。 智能化发展中,AI人才的匮乏和算力的高要求使车企大多采取“双腿”策略,既自研又借力成熟供应商,如华为、百度、商汤等。在智能座舱方面,合作对象包括OpenAI、亚马逊Alexa等。 车企智能化是必答题,智能座舱和智驾将成为未来差异化竞争的放大器。然而实现智能化仍需数年,并存在技术门槛高、算力资源紧缺的问题。 Mistral推出内容审查API,加强文本内容安全管理 AI初创公司Mistral发布了一个新的内容审查API,用于识别和分类可能包含不良内容的文本。该API基于Mistral的聊天平台Le Chat的内容审核技术,可以根据不同应用的需求和安全标准进行定制。API采用了微调模型Ministral 8B,支持多语言(如英语、法语和德语)文本分类,可识别九种类别:性内容、仇恨和歧视、暴力和威胁、危险和犯罪内容、自残、健康、金融、法律及个人身份信息。
安全策略导向:分类标准根据当前最相关的政策类别设定,确保模型安全。
异步处理模式:支持批量API调用,减少25%的模型服务成本。
https://techcrunch.com/2024/11/07/mistral-launches-a-moderation-api/ 推特
00 Arxiver开源:包含 138,830 篇 arXiv 论文的多Markdown格式
Meng To分享用 Cursor 和 Xcode 在 SwiftUI 中制作项目体验,新手友好 我用 Cursor 和 Xcode 在 SwiftUI 中做了这个项目。 Claude AI 在 iOS 开发上表现真的很好。在 Cursor 中输入提示词,然后在 Xcode 中预览/构建。SwiftUI 让自定义样式和动画的应用变得非常简单。 如果你是新手,这真的很有趣。不需要安装任何库,也不需要运行服务器。Apple 提供了一切所需的工具。
https://x.com/MengTo/status/1854522978652058081 字节跳动发布X-Portrait 2:AI 唇同步工具,捕捉到与情感完美契合的自然面部表情
介绍 X-Portrait 2:字节跳动的下一代 AI 唇同步工具 不仅能够呈现出极其逼真的唇部动作,还能够捕捉到与情感完美契合的自然面部表情。
https://x.com/EHuanglu/status/1854543663785005439
是否可以成为下一代树莓派?Pamir AI正在制作能承载3B模型的小芯片
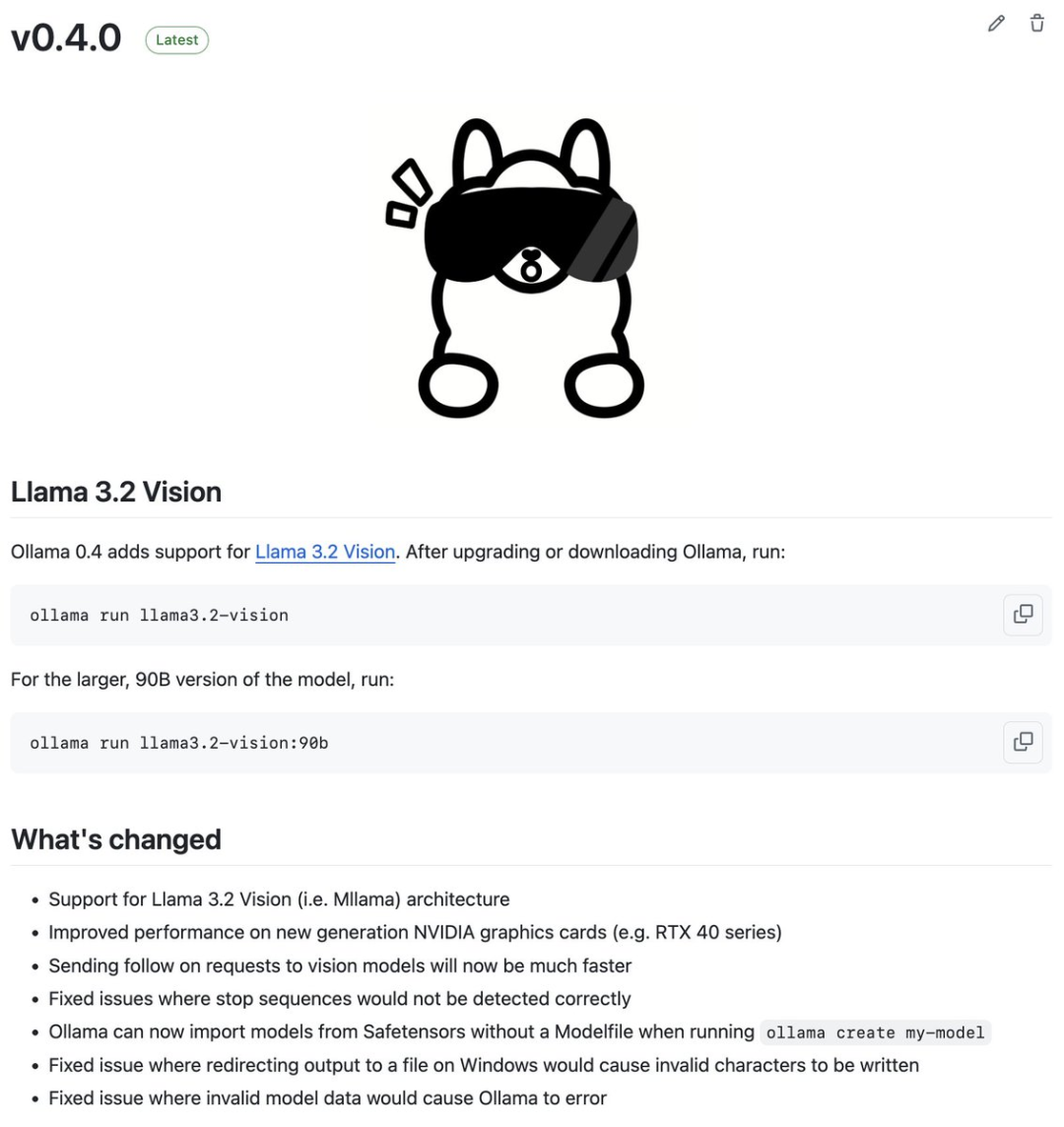
https://x.com/fdotinc/status/1854574327783624728 Ollama 0.4 发布:支持 Meta 的 Llama 3.2 Vision 模型 Ollama 0.4 已发布,支持 Meta 的 Llama 3.2 Vision 模型(11B 和 90B)。 https://ollama.com/blog/llama3.2-vision https://x.com/ollama/status/1854269461144174764 BlenderGPT创始人宣布获得来自他妈妈领投的1000刀融资引热议 很高兴宣布,BLENDERGPT 获得了我妈妈领投的0.001百万美元(1000美元)融资,用于打造全球最好的文本到3D转换工具。 https://x.com/gd3kr/status/1854544826345152889 产品 Commerce Pro by CapCut Commerce Pro by CapCut 是字节跳动推出的 AI 驱动的内容创作平台,可以让市场和社交媒体无缝集成。用户可以通过简单的产品链接生成可购物的视频广告、产品图片和社交媒体内容。该平台希望可以提升电商内容创作的效率,鼓励用户尝试并提供反馈,以便不断优化用户体验。 https://commercepro.capcut.com/ CopilotKit CopilotKit 是一个开源框架,可以帮助开发者轻松将 AI 助手和代理集成到 React 应用中。它提供即时集成、上下文感知功能、100% 开源和可定制的 UI,降低了 AI 开发的复杂性。新推出的 CoAgents 功能允许嵌入专用 AI 代理,进一步增强应用的智能化能力。 https://www.copilotkit.ai — END —
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/11/21685.html