
MOLAR NEWS
2020年第48期
MolarData人工智能每周见闻分享,每周一更新。
16000亿!谷歌发布人类历史首个万亿级模型 Switch Transformer,预训练速度提高7倍以上
近日,Google Brain的研究人员William Fedus、Barret Zoph、Noam Shazeer等在arxiv上提交了一篇新论文,“Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity”,提出了稀疏激活专家模型Switch Transformer。
研究人员表示,这个1.6万亿参数模型似乎是迄今为止最大的模型,其速度是Google之前开发的最大语言模型(T5-XXL)的4倍,参数规模几乎是1750亿参数的GPT-3的十倍!这应该是人类历史上发布的第一个万亿级人工智能模型。
Switch Transformer的新颖之处在于,它有效地利用了为稠密矩阵乘法(广泛用于语言模型的数学运算)而设计的硬件——例如GPU和Google TPU。研究人员为不同设备上的模型分配了唯一的权重,因此权重会随着设备的增多而增加,但每个设备上仅有一份内存管理和计算脚本。
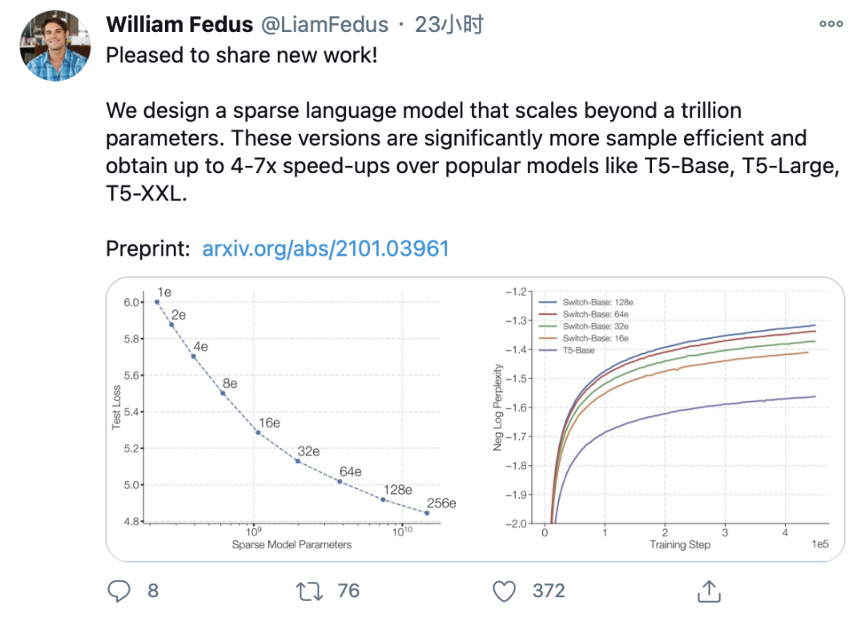

Switch Transformer 在许多下游任务上有所提升。研究人员表示,它可以在使用相同计算资源的情况下使预训练速度提高7倍以上。他们证明,大型稀疏模型同样可以用于创建较小的、稠密的模型,通过微调,这些模型相对大型模型会有30%的质量提升。论文一作William Fedus 也在twitter上表示,「我们的模型采样更加高效,相比于流行的模型,T5-Base,T5-Large、T5-XXL等能实现4到7倍的增速。」
来源:AI科技评论
Nature Machine Intelligence论文:“概念白化”,提供神经网络可解释性的新技术
深度神经网络的成功,要归功于它们极其庞大而复杂的参数网络,但是这种复杂性也导致了某些弊端:神经网络的内部运作通常是一个谜 —— 即使对于其创造者而言也是如此。自从深度学习从 2010 年代初期开始流行以来,这个难题就持续困扰着人工智能社区。
最近,Nature Machine Intelligence 发表的一篇论文,介绍了一种有潜力的新方法。杜克大学的科学家提出了一种名为 “concept whitening”(概念白化)技术,可在不牺牲性能的前提下帮助引导神经网络学习特定的概念。concept whitening 将可解释性带入了深度学习模型,而不是在数百万经过过训练的参数中寻找答案,显示出令人鼓舞的结果。
这次提出的 concept whitening,目标是让神经网络的隐空间与一些概念所对齐,而这些概念就是神经网络的目标。这种方法将使深度学习模型具有可解释性,也使我们更容易找出输入图像的特征与神经网络的输出之间的关系。Rudin 称:“我们的工作直接改变了神经网络,以解耦隐空间,使 axes 与已知概念对齐。”

来源:数据实战派
中国物流供应链“零的突破”!阿里路径规划算法入围运筹学“奥斯卡”
1月15日,国际运筹学与管理科学学会(INFORMS)公布了2021年Franz Edelman杰出成就奖总决赛名单,阿里巴巴凭借领先的路径规划算法及新零售实践,首度闯进总决赛。
INFORMS评价称,阿里开创了新零售模式,通过技术优化了仓配流程,可在极短时间内实现80%~90%的最优性能。
自适应大规模邻域搜索算法(ALNS),是2016年菜鸟开始建设路径规划算法系统之初,就择定的技术路线。
自适应大规模邻域搜索(ALNS)算法框架的优势在于:
-
易于拓展,除了求解标准的VRP(车辆路径规划)之外,还能够求解其各种变型问题;
-
相对于局部搜索类型的算法,ALNS在每一步搜索过程中能够探索更大的解空间;
-
ALNS算法在搜索过程中能够自适应地选择合适的算子,对于不同类型的数据都能有比较鲁棒的求解效果;
-
便于算法升级拓展,通过设计实现不同类型的算子,ALNS可以实现不同的搜索策略。
来源:量子位
隐私保护与生成模型: 差分隐私GAN的梯度脱敏方法
机器学习模型的训练需要大量的数据喂食,而这些数据的应用就会涉及到个人隐私的问题。而随着数据规模越来越大,隐私问题也获得了更多的关注,而如何保护隐私也逐渐成为了比较热门的研究方向。一个直观的想法是能否利用生成模型来生成数据,既满足了隐私保障,不损害用户的个人隐私,也能满足模型训练对于数据规模的需求,还可以通过机器学习算法的验证。因此这篇文章的主要任务就是实现privacy preserving data generation,即隐私保护的数据生成,具体来说就是结合了差分隐私(differential privacy)和生成对抗网络(GAN),其中差分隐私可以提供严格的隐私保障,而GAN可以用于拟合数据分布,特别是拟合高维数据的数据分布。与传统的privacy preserving data generation方法需要对后续任务做假设相比,使用基于神经网络的生成模型可以避免对后续的任务做假设。鉴于传统方法往往只能处理简单的后续任务,使用GAN可以很好的避免这个局限。
来源:AI TIME 论道
前沿丨戴琼海院士团队:利用深度学习构建复杂表型的遗传效应解释模型
遗传效应解释了从基因突变到复杂疾病发展的因果关系。因此,全面识别遗传效应可以为疾病的发展和治疗提供有价值的见解。但如何解释复杂表型的遗传因果关系一直以来都是学界悬而未决的热点问题。近日,清华大学脑与认知科学研究院戴琼海院士团队在Cell Press旗下Patterns期刊发表了一篇题为“Explaining the Genetic Causality for Complex Phenotype via Deep Association Kernel Learning”的文章,提出可以通过深入关联核学习(DAK)解释复杂表型的遗传因果关系。
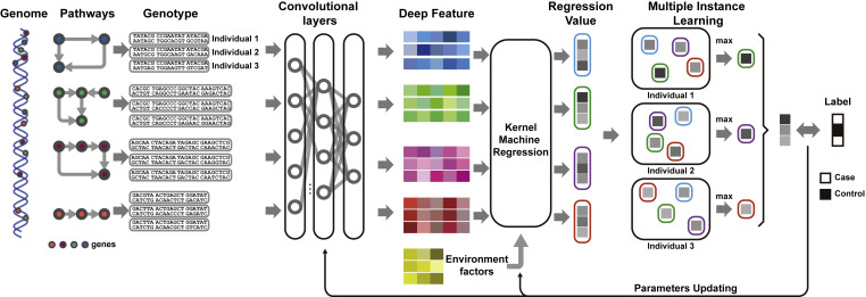
此项研究引入了深度关联核学习(DAK)模型,一种在深度学习框架中构建的GWAS方法,它可以在基因通路水平上实现自动基因型编码。
在基因研究领域,虽然深度学习已经在基因调控、突变效应预测和结合位点识别方面取得了成功,但尚未建立解决一般GWAS问题的深度学习模型。在这项研究中,DAK框架结合卷积网络来编码原始SNP,提取遗传隐变量表示;核回归方法对编码的遗传表示进行进一步统计推断,预测疾病状态。更重要的是,这个内核回归层允许对自动推断的遗传表示进行统计检测,揭示疾病相关的生物过程。卷积层和核回归层都是以端到端的方式使用多实例损失函数联合训练的。因此,DAK不依赖于预先假定的遗传模型,以纯数据驱动的方式学习所有模型参数。
来源:中国人工智能学会
AI资讯
掌握最新时事新闻
长按扫码关注我们

原创文章,作者:整数智能,如若转载,请注明出处:https://www.agent-universe.cn/2021/01/8467.html