我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢 迎 大 家 一 起 交 流 !
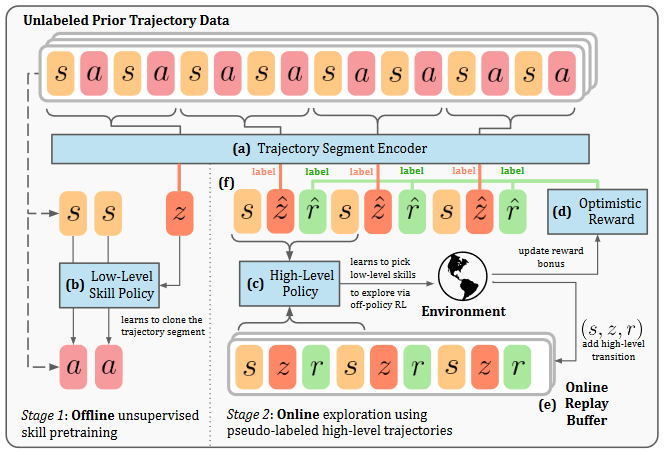
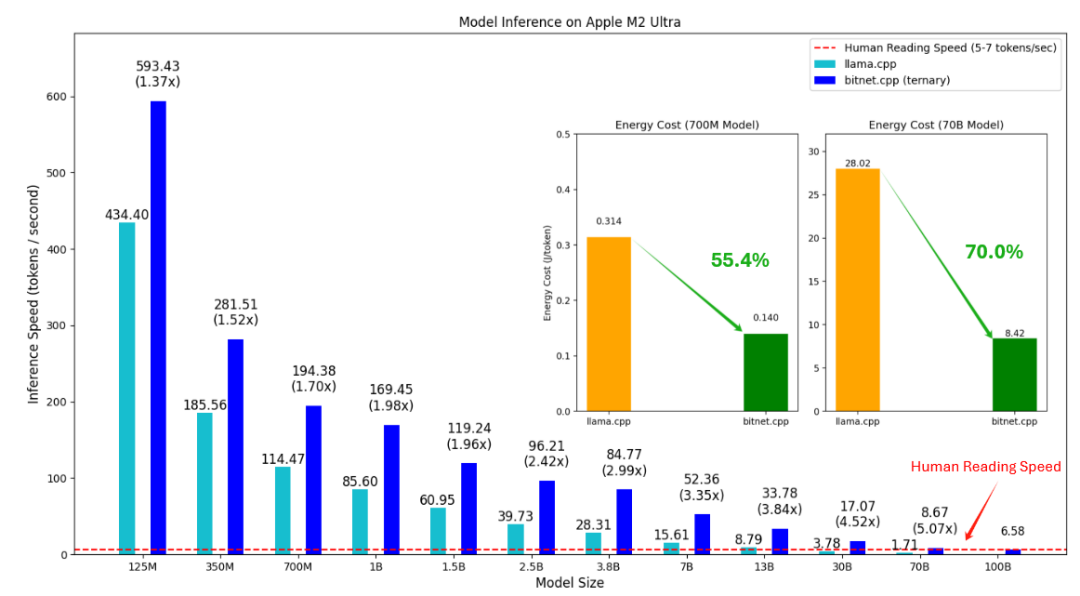
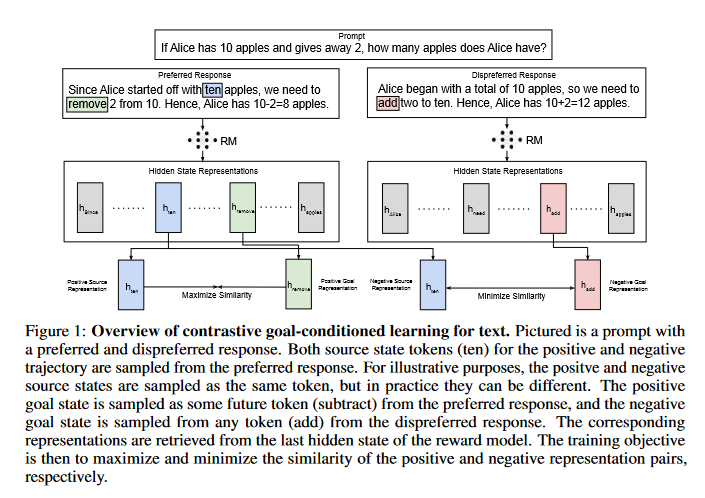
信号 Leveraging Skills from Unlabeled Prior Data for Efficient Online Exploration 在许多有监督的领域,无监督预训练都起到了变革性的作用。然而,将这种想法应用于强化学习(RL)会面临独特的挑战,因为微调并不涉及模仿特定任务的数据,而是通过迭代自我改进来探索和定位解决方案。在这项工作中,我们研究了如何利用未标记的先验轨迹数据来学习高效的探索策略。虽然先验数据可用于预训练一组低级技能,或作为在线 RL 的额外非策略数据,但如何将这些想法有效地结合到在线探索中,一直是个未知数。我们的方法SUPE(从未标明的先验数据中提取技能用于探索)证明,将这些想法精心组合在一起,会使它们的优势更加明显。 https://x.com/qiyang_li/status/1849460110118056215 1-bit AI Infra: Part 1.1, Fast and Lossless BitNet b1.58 Inference on CPUs BitNet 和 BitNet b1.58 等 1 位大型语言模型 (LLM) 的最新进展为提高 LLM 在速度和能耗方面的效率提供了一种有前景的方法。这些发展还使得本地LLM能够在广泛的设备上部署。在这项工作中,我们介绍了 bitnet.cpp,这是一个定制的软件堆栈,旨在释放 1 位 LLM 的全部潜力。具体来说,我们开发了一组内核来支持 CPU 上三元 BitNet b1.58 LLM 的快速无损推理。大量实验表明,bitnet.cpp 在不同的模型大小上实现了显着的加速,在 x86 CPU 上从 2.37 倍到 6.17 倍,在 ARM CPU 上从 1.37 倍到 5.07 倍。 https://x.com/BensenHsu/status/1849272919173771552 Learning Goal-Conditioned Representations for Language Reward Models 通过离线数据或自我监督目标学习改进表示的技术在传统强化学习(RL)中已经显示出令人印象深刻的结果。然而,目前尚不清楚改进的表示学习如何有利于语言模型(LM)上人类反馈(RLHF)的强化学习。在这项工作中,我们提出通过增加沿采样的首选轨迹的未来状态的表示相似性并降低沿随机采样的非首选轨迹的相似性,以对比、目标条件的方式训练奖励模型(RM)。这一目标在具有挑战性的基准测试(例如 MATH 和 GSM8k)中显着提高了 RM 性能高达 0.09 AUROC。 https://x.com/scale_AI/status/1849491836735455720 Introducing the analysis tool in Claude.ai 我们将推出分析工具,这是 Claude.ai 的一项新内置功能,使 Claude 能够编写和运行 JavaScript 代码。克劳德现在可以处理数据、进行分析并产生实时见解。该分析工具可在功能预览中供所有 Claude.ai 用户使用。 https://x.com/AnthropicAI/status/1849466473309241795 Introducing quantized Llama models with increased speed and a reduced memory footprint 虽然量化模型以前在社区中已经存在,但这些方法通常是在性能和准确性之间进行权衡的。为了解决这个问题,我们使用 LoRA 适配器进行量化感知训练,而不仅仅是后处理。因此,我们的新模型减少了内存占用,加快了设备上的推理速度,提高了准确性和可移植性,同时保持了开发人员在资源受限的设备上部署的质量和安全性。 https://x.com/AIatMeta/status/1849469912521093360 RankDPO 项目探讨了一种可扩展的方法,通过预训练的奖励函数生成全自动合成数据集,以支持直接偏好优化(DPO)在文本到图像(T2I)模型中的应用。该方法消除了人工标注的需求,显著提高了数据集收集效率。我们提出的 RankDPO 利用排名反馈增强 DPO 方法,在 SDXL 和 SD3-Medium 模型上应用合成偏好数据集“Syn-Pic”,有效提升了模型的提示跟随能力和视觉质量。这一流程为改进文本到图像模型的偏好数据集提供了实用且可扩展的解决方案。 https://snap-research.github.io/RankDPO/
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/10/21640.html