
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


行云季宇:谁困住了 AI 产业——大型机化的计算机形态与变革的可能性 | 奇绩潜空间活动报名
【奇绩潜空间】是 GenAI 时代冲得最快的一批科研学者/从业者/创业者聚集的 AI 人才社区,潜空间定期邀请大模型前沿创业者分享产品实践探索,邀请前沿科研学者分享最新技术进展。
第五季第二期潜空间邀请到的嘉宾是行云创始人兼 CEO ——季宇,在本次活动中季宇将在北京现场与大家面对面交流,他分享的主题是《谁困住了 AI 产业——大型机化的计算机形态与变革的可能性。

信号
Qwen2.5 Technical Report
-
多样化的模型规模: Qwen2.5在模型规模上进行了扩展,除了原有的0.5B、1.5B、7B和72B模型外,还新增了3B、14B和32B的版本。这些中等规模的模型在资源有限的场景下更加具有成本效益,填补了当前开放基础模型中对这些规模模型的需求空缺。此外,Qwen2.5-Turbo和Qwen2.5-Plus通过平衡准确性、延迟和成本,提供了更灵活的选择。 -
数据处理能力的提升: Qwen2.5的预训练数据量大幅增加,从7万亿个标记提升至18万亿个标记,重点增强了知识、编程和数学等领域的内容。这一增强的数据集支持更广泛的应用,特别是在技术性和数学性问题的处理上。此外,Qwen2.5采用了分阶段的预训练方法,使得模型能够在不同数据混合中进行有效过渡,提升了模型的灵活性和适应能力。 -
改进的后训练流程: Qwen2.5的后训练数据也有所增强,涵盖了超过100万条例子,涵盖了监督微调(SFT)、直接偏好优化(DPO)和群体相对策略优化(GRPO)等多个阶段。这些后训练技术的使用确保了模型在实际任务中的高效性和多样性。 -
更好的生成能力和工具支持: Qwen2.5在生成能力上取得了显著提升,生成长度从2K tokens增加到8K tokens,支持更加复杂和长篇的文本生成。此外,Qwen2.5还增强了对结构化输入输出(如表格和JSON)的支持,使得模型在处理实际应用中的任务时更加灵活。此外,Qwen2.5-Turbo版本甚至支持最多达100万个tokens的上下文长度,进一步扩展了模型的应用范围。 -
混合专家模型的引入: 除了传统的预训练模型,Qwen2.5还推出了Mixture-of-Experts(MoE)模型,如Qwen2.5-Turbo和Qwen2.5-Plus,这些模型能够根据任务需求动态选择专家模型,提高了计算效率并降低了成本。这些模型在与其他先进模型如GPT-4o-mini和GPT-4o的比较中表现出色,展示了Qwen2.5在大规模计算资源下的优越性。
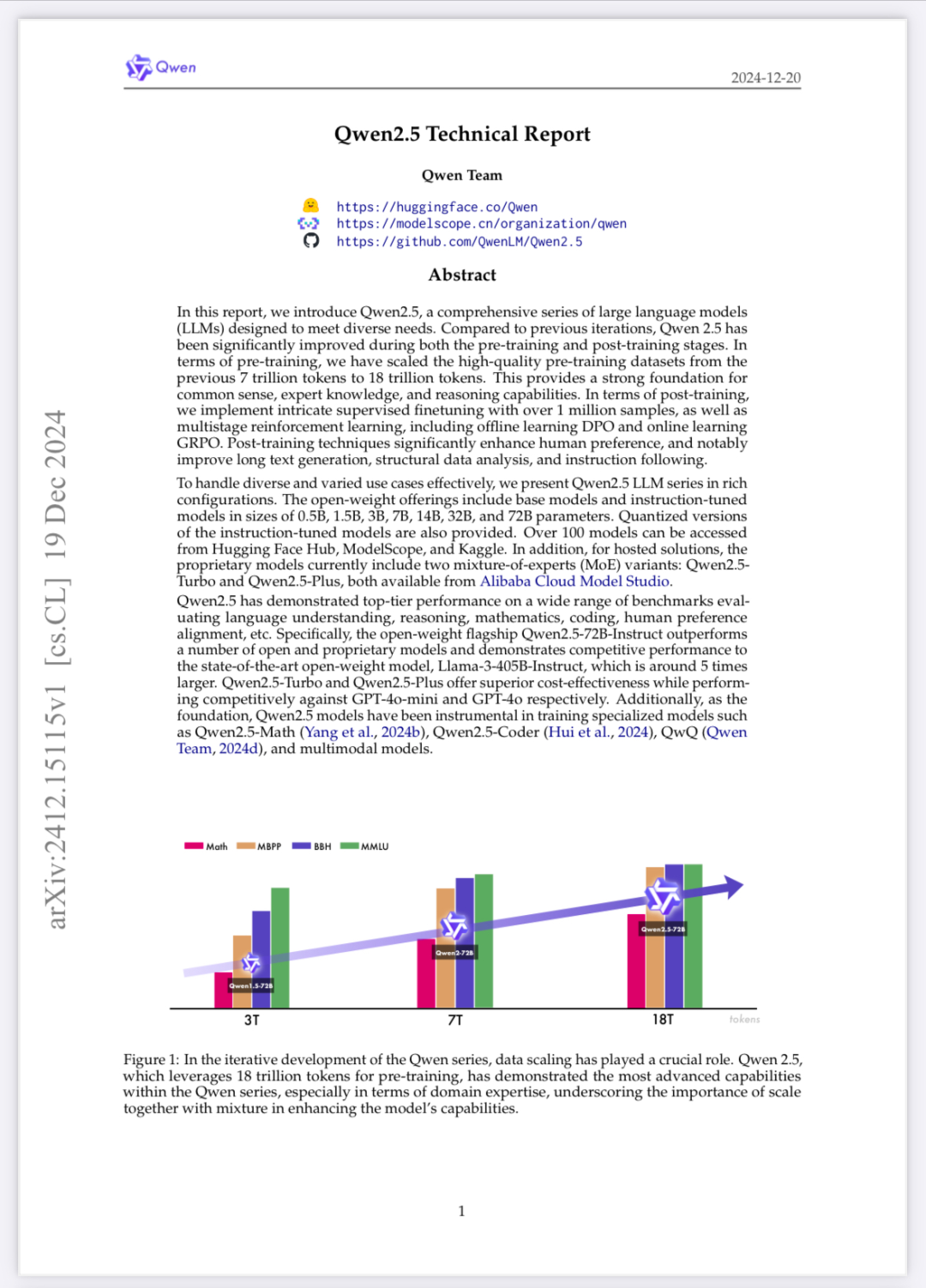
AceMath: Advancing Frontier Math Reasoning with Post-Training and Reward Modeling
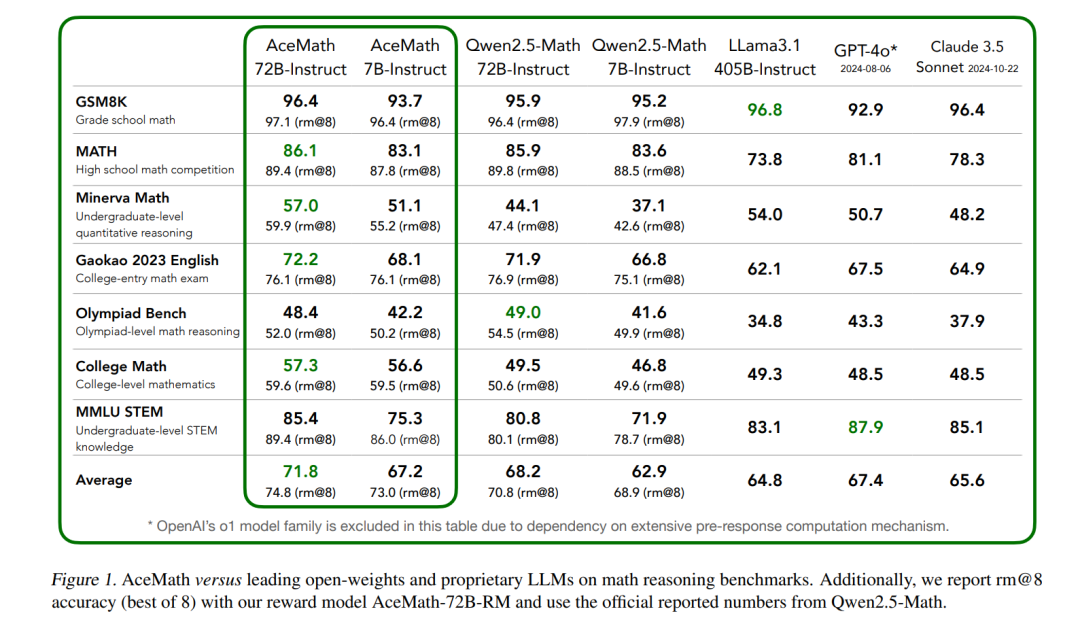
How to Synthesize Text Data without Model Collapse?
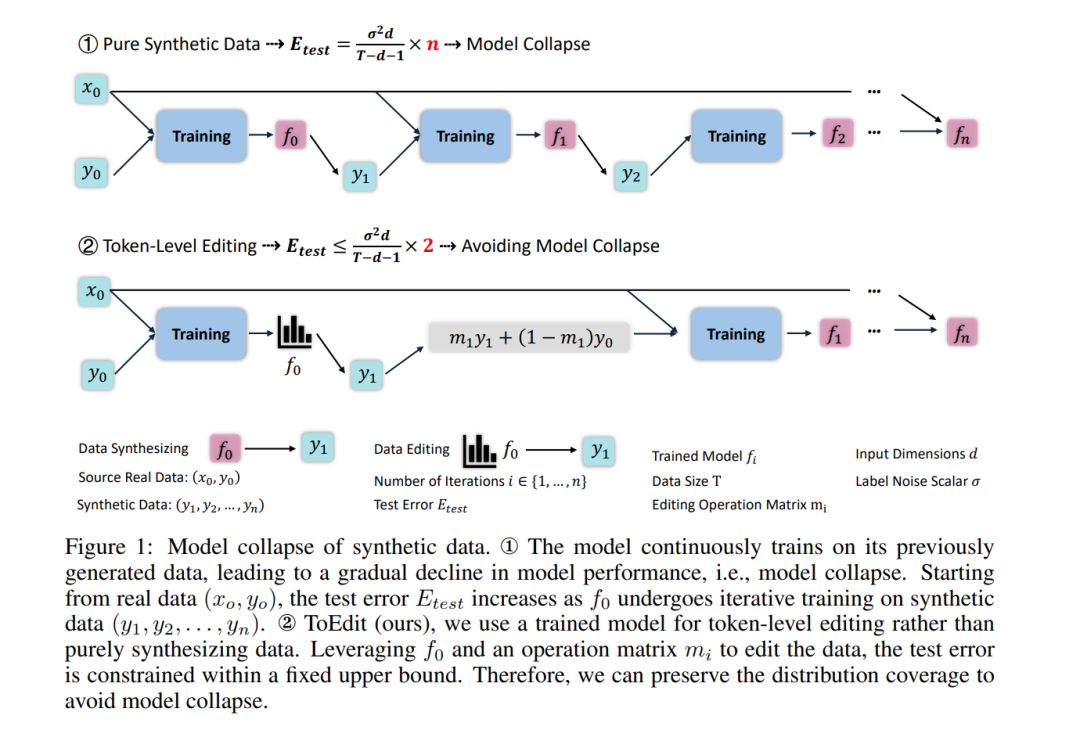
Proposer-Agent-Evaluator(PAE): Autonomous Skill Discovery For Foundation Model Internet Agents
-
自主技能发现: 传统的基础模型通常依赖人类定义的任务模板,限制了技能的多样性和扩展性。PAE框架的创新之处在于,代理能够自主发现新的任务和技能,而无需人工干预。这些技能可以用于未见过的任务,并通过零-shot方式解决人类注释过的任务,表现出较强的泛化能力。 -
技能提议、评估与执行的协同: PAE通过任务提议者生成可行的任务,并利用代理策略尝试这些任务,再通过自动评估者提供奖励信号。评估者基于最终结果(例如网页操作的成功与否)给予稀疏的0/1奖励,帮助代理评估自己的行动是否有效。这种设计极大地减少了对隐藏状态信息的依赖,提升了系统的鲁棒性。 -
上下文感知任务提议: 为确保代理能够执行实际的、可行的任务,PAE使用了上下文感知的任务提议者。这些提议者根据任务的环境和约束(例如某些功能是否可用)生成任务,从而避免了不可执行的任务。在实验中,任务提议者甚至能够通过简单的网页名称或用户示范来推断出可执行的任务。 -
增强的推理步骤: 在代理执行任务前,PAE设计了额外的推理步骤,使得代理能够反思自己的技能和执行结果。这个反思过程显著提升了代理对未见任务的泛化能力,确保其能够适应不同的实际应用场景。 -
强大的零-shot泛化能力: 在多种Web导航任务中,PAE框架展现了卓越的性能。使用LLaVa-1.6作为代理策略的PAE,可以在无需人工监督的情况下,通过与多个网站的互动自动发现有效技能,并能成功应对从未见过的任务指令。这一成果不仅验证了PAE的有效性,还展示了它在多达100个领域中的广泛适应性。
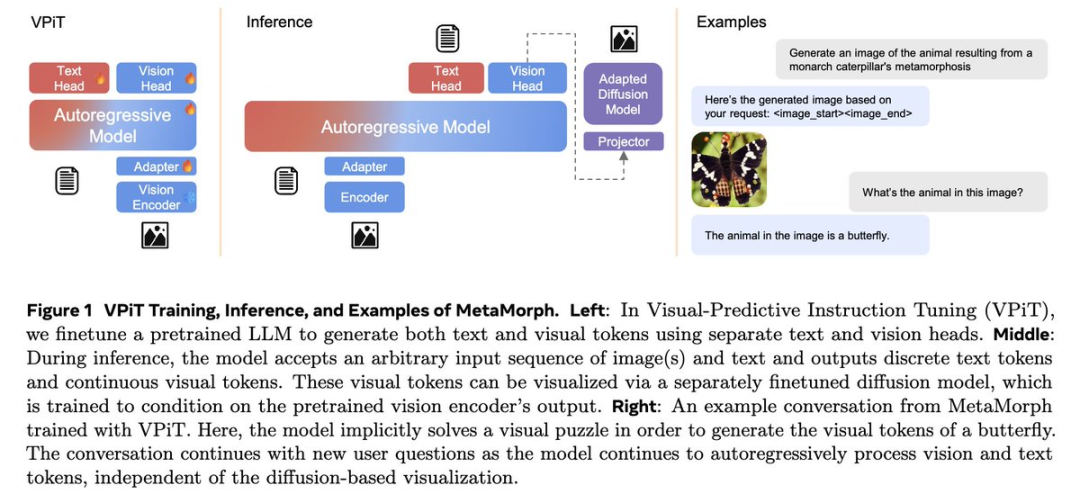
MetaMorph: Multimodal Understanding and Generation via Instruction Tuning
-
视觉理解与视觉生成的统一: 传统的多模态大语言模型通常将视觉生成与理解分开处理,需要大量的预训练和微调数据。而VPiT通过一种简化的方式,将连续的视觉标记作为输入,训练模型在理解图像内容的同时,也能生成相应的视觉输出。这种方法只需要少量额外的视觉生成数据(如20万条),且在处理时数据与计算效率较高。 -
视觉理解与生成的内在联系: 研究表明,视觉理解和生成能力是相互关联且不对称的。增加视觉理解数据能显著提高理解性能,同时也能提升生成效果;而增加生成数据则主要改善生成质量,并在一定程度上增强视觉理解,但对理解的提升较为有限。 -
模型性能的提升: 基于VPiT,论文提出的MetaMorph模型展示了视觉理解与生成能力的协同效应。在大量的视觉理解数据的支持下,MetaMorph能够在多模态标记预测任务中表现出色,并在视觉理解和视觉生成基准测试中取得了竞争性的成绩。特别值得注意的是,MetaMorph能够从预训练的大语言模型中提取知识,并且在生成视觉标记时进行推理。例如,当被要求生成“由帝王蝶幼虫蜕变而来的动物”时,MetaMorph成功生成了蝴蝶的图像。
HuggingFace&Github
Ant Design X
https://github.com/ant-design/x
2. 「理论与实践」AIPM 张涛:关于Diffusion你应该了解的一切
3. 「奇绩潜空间」吕骋访谈笔记 | AI 硬件的深度思考与对话
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/12/29028.html