我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
学术分析报告:ResearchFlow — 奇绩F23校友的开发的深度研究产品,PC端进入RFlow的分析报告,可直接点击节点右侧的小数字展开节点,登录后可在节点上直接“询问AI”,进一步探索深度信息 如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢 迎 大 家 一 起 交 流 !
资讯
国产之光DeepSeek 671B大模型训练只需此前算力1/10 DeepSeek V3 是一款开源的 MoE 模型,参数量达 671B,激活 37B,基于 14.8T 高质量 token 进行预训练,标志着在开源大模型领域的重要进展。相比同类的 Llama 3.1 405B、GPT-4o 和 Claude 3.5 Sonnet,DeepSeek V3 在多个评测中超越了它们,且在训练效率和成本上表现出色。它的训练耗时仅为 Llama 3.1 的 1/11,训练成本约 557.6 万美元(约 4070 万人民币),远低于其他顶级模型的训练成本。 DeepSeek V3 的训练过程仅用了不到 280 万 GPU 小时,相较于 Llama 3.1 的 3080 万 GPU 小时,展现了显著的算力优化。此优化通过架构、算法和硬件的协同工作实现,采用了创新的负载均衡策略和无辅助损失的训练目标。在模型架构上,DeepSeek V3 引入了 FP8 混合精度训练,并设计了高效的跨节点通信策略,如 DualPipe 高效流水线并行算法,以减少通信瓶颈并提升训练速度。 在实际应用中,DeepSeek V3 展现出卓越的性能和性价比。它的生成速度提高了 3 倍,能够每秒生成 60 个 token,API 价格也极具竞争力,每百万输入 tokens 的价格为 0.5 元(缓存命中),输出为 8 元。此外,DeepSeek V3 还推出了 45 天的优惠期,进一步降低了使用成本。 DeepSeek V3 支持 FP8 和 BF16 推理,适配了多个推理框架,如 SGLang、LMDeploy、TensorRT-LLM 和 MindIE。官方还开源了模型的原生 FP8 权重和转换脚本,方便用户进行部署和优化。 在测试中,DeepSeek V3 在多个基准测试中达到了开源模型的 SOTA,并且能够高效理解和生成复杂的回答。例如,在“Which version is this?”的测试中,DeepSeek V3 能准确识别自己的版本,超越了其他模型,如 ChatGPT 和 Grok。 DeepSeek V3 的成功不仅在于其高效的技术实现,还得益于其背后团队的多年积累。DeepSeek 团队采用了创新的技术路线和实践经验,逐步优化和提升了大规模模型的训练和推理效率。整体来看,DeepSeek V3 在模型能力、训练成本、速度和性能上都具备显著优势,是当前开源大模型领域的一大亮点。 小米将对AI大模型大力投入,正搭建GPU万卡集群 小米正在建设GPU万卡集群,并加大对AI大模型的投入。小米大模型团队自成立以来,已配备6500张GPU资源。据了解,这一计划已实施数月,并且雷军在其中扮演了重要角色。小米在AI硬件领域的布局尤为重视手机而非眼镜,显示出公司在此领域的战略决心。12月20日,DeepSeek-V2的核心开发者罗福莉加入小米,预计将担任AI实验室的重要职务,领导大模型团队。罗福莉在MLA(Multi-head Latent Attention)技术上的创新曾大大降低了大模型的使用成本,为小米AI大模型的发展注入了强大动力。 2023年4月,小米AI实验室大模型团队正式组建,栾剑被任命为团队负责人,并向小米技术委员会副主席王斌汇报。栾剑曾是小米语音生成团队负责人,并在微软等公司有丰富的AI研究经验。雷军曾在多个场合提到小米对于AI的重视,特别是在大模型和AIGC领域的布局。他表示,小米在AI领域已经有多年积累,拥有AI实验室、语音助手“小爱同学”和自动驾驶等多个团队。 小米大模型技术的突破方向主要集中在轻量化和本地部署方面。小米已成功跑通了一款参数为13亿的大模型,并且在某些场景下其效果接近于云端60亿参数的大模型。此外,小米还发布了MiLM-6B和1.3B两款模型。王斌曾表示,尽管小米坚持自研,仍保持开放合作的态度,采用自研与第三方模型相结合的方式来推动大模型发展。在小爱同学的首次大模型升级中,正是采用了自研与第三方模型的混合方案。 自2016年成立AI团队以来,小米的人工智能技术团队规模已达3000多人,覆盖视觉、声学、语音、NLP、机器学习、大模型等多个领域,并逐步将其技术应用到手机、汽车、AIoT和机器人等产品中。 OpenAI科学家:现有模型+后训练足以产生黎曼猜想的新证明 OpenAI科学家塞巴斯蒂安・布贝克提出了一个新颖的能力衡量指标——“AGI时间”,用以描述AI模型完成任务的时间跨度。根据这个概念,GPT-4可以在几秒或几分钟内完成任务,o1模型则能够在几小时内完成,而未来的模型甚至可能在“AGI日”和“AGI周”内解决重大开放问题。该观点引发了广泛的讨论,有人认为这代表模型已接近AGI,能处理长时间推理和计划任务,但也有人质疑这一概念的模糊性及其实际可行性。 在一场辩论中,布贝克强调,LLM(大语言模型)通过不断的规模扩展,展现出了显著的能力提升,尤其在多个领域的基准测试中取得了突破性成绩。例如,GPT-4在MMLU测试中的得分接近90%,o1模型甚至接近95%。布贝克认为,随着后训练技术的进步,模型将能进一步挖掘潜力,解决如数学难题等复杂问题。他提到,o1模型已经能够迅速将不相关的知识点联系起来,为解决难题提供新的线索,未来有望在AGI日级甚至周级时间内,通过更深入的推理和训练,找到解决数学猜想的路径。 然而,反方辩手汤姆・麦考伊提出了对LLM能力的质疑。他认为,LLM目前的发展依赖于大量的训练数据,但这种数据驱动的模式存在严重的局限性,尤其是在面对低频任务时,如数学证明。麦考伊指出,LLM难以从训练数据之外的全新思维中产生创新突破,并且在处理长推理时容易产生错误,这种“幻觉”问题会对数学证明的严谨性构成威胁。他还认为,现有的语言模型架构无法深入到数学推理和抽象逻辑的核心,缺乏创新思维。 对于这些观点,布贝克进行了反驳,强调人类的顶级科学成就也常依赖现有知识的组合,模型在这方面的能力将通过强化学习等技术不断增强。他还提出,未来不同智能体可以相互合作,纠正彼此的错误,从而避免累积错误影响推理结果。 其他专家如Anthropic的帕维尔·伊斯梅洛夫和MIT的安库尔·莫伊特拉也对LLM在数学领域的应用发表了看法。伊斯梅洛夫认为,LLM在数据结构的识别上有优势,但数学领域的专业性要求可能需要结合强化学习和证明验证器等工具。而莫伊特拉则表示,解决重大数学问题不仅仅是堆叠能力,更需要新的思维方式和创新。 国产GPU厂商象帝先续命 象帝先,这家知名国产GPU厂商,近日迎来了融资的新曙光,成功走出此前困境。自4月以来,象帝先曾遭遇资金链断裂,传出倒闭和大规模裁员的消息,幸好公司通过澄清公告并在员工支持下进行了人员优化,保留了核心力量。经过一段时间的努力,公司不仅得到了新一轮融资支持,还在研发和市场拓展方面迎来了突破,特别是在量产新一代GPU产品上取得了重要进展。 象帝先的成功自救策略,主要体现在“营销与研发”双轮驱动。公司通过增强营销团队的能力,与多家整机厂商和主流软件厂商完成了适配测试,逐渐赢得客户的信任。同时,研发团队在已量产GPU的基础上,进一步优化产品性能并进行技术创新,为公司提供了坚实的支持。 象帝先成立于2020年,在中国科技竞争日益激烈的背景下,迅速发展并在2022年发布了“天钧一号”GPU,这是首款拥有自主知识产权的国产高性能GPU。该芯片基于Imagination的IP核,采用12纳米工艺,拥有2048个计算核、4TFLOPS的FP32算力、16TOPS的AI算力、16GB显存和256GB/s带宽。紧接着,公司在2023年发布了面向工控、嵌入式和边缘计算领域的“天钧二号”GPU,并以此为基础,计划填补国内高性能通用GPU市场的空白。 然而,尽管技术实力不容小觑,象帝先仍面临市场开拓的困难,尤其是在国内芯片市场的竞争中没有获得突破。今年,象帝先经历了资金危机和多次负面消息,但随着政策支持力度的加强和公司内部的团结,象帝先成功逆转局面,继续推动技术创新和市场开拓。2024年,象帝先被评为“重庆市独角兽企业”,估值一度达到21.69亿美元,展现了其巨大的成长潜力。 推特
00 Arxiver开源:包含 138,830 篇 arXiv 论文的多Markdown格式
2024年谷歌AI重要新闻回顾 2024年是谷歌AI蓬勃发展的一年,从新产品发布到技术突破,多个创新项目改变了用户的日常生活。以下是一些关键的谷歌AI新闻和更新:
Gemini与Bard的升级2024年初,谷歌推出了更强大的Gemini 1.5版本,并宣布Bard将转型为Gemini。该月还发布了Circle to Search功能,允许用户通过圈选文本直接搜索相关信息。
生成性AI工具的持续发展谷歌在各大产品中推出了生成性AI功能,涵盖了Chrome、Pixel、Google Photos等。特别是生成AI在健康领域的应用,极大地提升了人们获取健康信息的便捷性。
Google I/O大会与产品发布2024年Google I/O大会上,谷歌展示了如何通过AI提升产品功能,尤其是Google Search、Photos和Bard的多项更新。此外,AlphaFold 3模型的发布也为科学界带来了突破。
AI在教育和工作中的应用通过Google Workspace、NotebookLM等工具,AI正逐步进入教育和商业领域。NotebookLM更是推出了支持音频概述的新功能,提升了工作效率。
月度更新与产品优化各月份持续推出多项AI更新,包括Pixel手机的AI功能增强、Google Translate新增语言支持,以及对Google Lens和Shopping的改进等。
量子计算与未来展望在12月,谷歌推出了全新的Gemini 2.0模型,标志着AI进入了“代理时代”,并且发布了首款量子芯片Willow。与此同时,AI在Pixel、Android等平台上的应用也进入了全新的阶段。
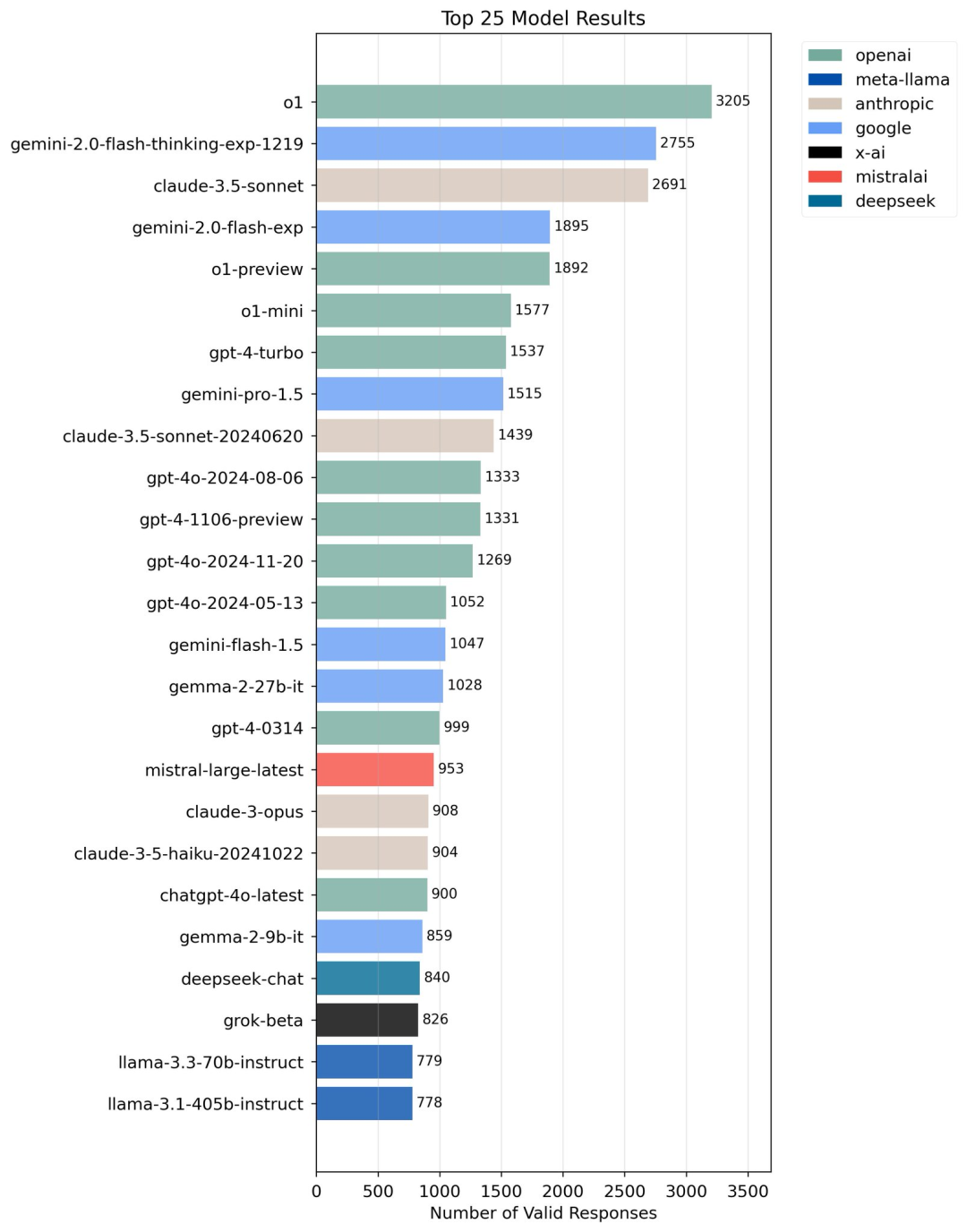
https://x.com/JeffDean/status/1872500136351526987 DeepSeek v3在AidanBench上的表现不如预期,Gemini-2.0-Flash-Thinking表现提升 近期,DeepSeek v3在AidanBench上的表现比预期差,明显低于像Aider这样的相似基准测试中取得的成绩。类似的情况也出现在Claude-3.5-Haiku上,后者在Aider上表现优异,但在AidanBench上表现较差。
AidanBench仍在持续完善中,未来版本可能会导致排名变化。
AidanBench专注于评估模型在**超出训练数据范围(OOD)**的表现,尤其是与数学、代码和学术测试无关的领域。因此,即使某些实验室的模型在这些领域表现突出,但在AidanBench中未必能够取得同样的成绩。
Gemini-2.0-Flash-Thinking的表现提升:
经过对Gemini-2.0-Flash-Thinking的更新,它的排名从之前的较低位置跃升至第二名。
该改进源于对其推理过程的调整,以便更好地解析最终输出,而非仅仅处理Chain of Thought (CoT)和中间响应,避免了以往将不一致的答案纳入考量。
尽管DeepSeek v3在多个基准测试中表现出色,但在AidanBench上的低排名(第22位)可能反映了其在处理OOD任务时的局限性。这也提醒我们,即使是性能强大的模型,若其训练数据和实际测试场景不匹配,仍然可能无法充分发挥优势。
https://x.com/aidan_mclau/status/1872444303974543859
vLLM 新版本发布 vLLM 发布了最新版本,用户可以通过 pip install -U vLLM 更新到最新版。在此版本中,DeepSeek-V3 支持了多种方式的并行处理和硬件加速,提升了模型训练和推理的效率。
张量并行:对于支持的硬件,如 8xH200 或 MI300x 芯片,用户可以通过 --tensor-parallel-size 参数启用张量并行。对于使用 IB 连接节点的 TP16 配置,也支持相应的并行处理。
管道并行:新版 vLLM 支持管道并行,适用于多机配置,不依赖高速互连,用户只需要配置 --pipeline-parallel-size ,就可以实现跨两台 8xH100 或其他机器的分布式训练。
CPU卸载:vLLM 还支持将部分模型层通过 --cpu-offload-gb 参数卸载到 CPU,减少 GPU 的负担,优化硬件资源的使用。
此外,vLLM 提供了详细的分布式部署指南,帮助用户更好地理解如何在大规模集群环境中使用 DeepSeek-V3 模型进行分布式推理和训练。更多的优化计划也在持续进行中,用户可以查看 vLLM 的分布式服务文档 和 增强计划 获取最新进展。 https://x.com/vllm_project/status/1872453508127130017 CVPR2025 报名现已开放 CVPR 是计算机视觉领域的顶级年度会议,包含主会议和多个协办的研讨会和短期课程。凭借其高质量和低成本,CVPR为学生、学术界和工业界研究人员提供了卓越的价值。
每篇论文(无论是主会议论文还是研讨会论文)必须以作者注册类型进行注册(学生注册可以作为此类型的选项)。一次注册可以覆盖多篇论文。
虚拟注册无法覆盖论文提交,即使是研讨会论文也不例外。如果因特殊情况无法亲自出席并展示论文,您仍然可以选择虚拟参会,但必须进行现场注册并支付相关费用,同时选择虚拟参会。
支付方式:仅接受通过注册网站使用信用卡支付。我们不接受电汇、支票或采购订单。完成支付后会发放收据。请在注册过程中提供需要用于收据的地址。如需更改收据信息,您可以自行修改。
https://na.eventscloud.com/ereg/index.php?eventid=823364& https://x.com/CVPR/status/1872341053342384388 产品 PopShort.AI 人工智能故事创作工具 PopShort.AI 是一款人工智能故事创作工具,能够将您的灵感迅速转化为引人入胜的短片,仅需几分钟即可完成。它通过先进的 AI 技术,让每个人都能成为自己的短片导演,无论是没有任何影视制作经验的人,还是有创作经验的专业人士,都能轻松实现创意的视觉呈现。PopShort.AI 提供直观的操作界面和强大的创作功能,帮助用户快速生成高质量的短片,激发无限创意,轻松打造属于自己的视觉故事。
https://popshort.ai/?ref=producthunt
Lambda AI 驱动的投资助手 Lambda 是一款由 AI 驱动的投资助手,旨在通过专业级的分析帮助提升您的投资体验。它让您轻松追踪持仓和股息,智能管理投资风险,同时还可以利用内置的智能聊天机器人获得实时的市场洞察。Lambda 结合强大的数据分析能力和人工智能技术,帮助投资者做出更加精准和明智的决策,简化投资过程,实现更高效的财富增值。无论是新手还是资深投资者,都能通过 Lambda 提升自己的投资管理水平,掌控市场动态。 https://lambdafinance.ai/en?ref=producthunt — END — 快速获得3Blue1Brown教学动画?Archie分享:使用 Manim 引擎和 GPT-4o 将自然语言转换为数学动画
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/12/29136.html