
当AI开始“多检查几遍作业”
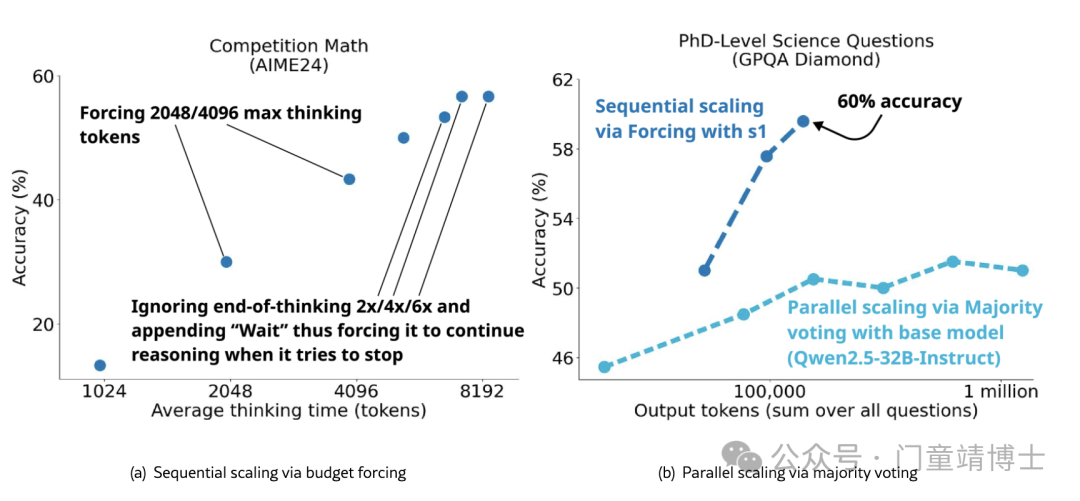
想象一下,如果一个学生每次做题时,老师都要求他“先写满三页草稿纸再交卷”,或者“想太快了,再回去检查两遍”——这种“强制思考”的方法,竟然让一个AI在数学竞赛中的正确率从50%飙升到57%!
斯坦福李飞飞团队的最新研究s1,正是用这种看似简单的策略,以仅1000道题的数据量,击败了OpenAI的明星模型o1-preview。今天,我们就来揭开这个“小模型逆袭”的奥秘。


一、AI解题的“致命弱点”:想太快,错太多
1.1 传统模型的“秒答陷阱
现有语言模型(如ChatGPT)解题时往往“一步到位”,就像学霸不写过程直接报答案。
虽然速度惊人,但在复杂数学题上,这种习惯会导致低级错误频发。例如,面对几何证明题时,模型可能跳过关键推导步骤,直接给出错误结论。
1.2 OpenAI的昂贵解法
为提升准确性,OpenAI的o1模型曾用百万级练习题+强化学习训练模型,效果虽好但成本极高(相当于数千张顶级显卡日夜运算)。
更关键的是,其核心技术至今未公开,学界只能“盲人摸象”般尝试复现。
二、斯坦福的“极简主义革命”:1000题+两招控制法
2.1 数据筛选的“黄金三原则
-
难度过滤:用两个AI模型(7B和32B参数)当“陪练”,剔除它们能轻松解决的题目
-
质量把控:剔除含乱码、图片引用的“脏数据”
-
学科平衡:像高考命题组般分配几何、数论、概率等50个领域的题目
-
效果验证:随机选1000题的正确率比精选版低30%,证明“题海战术不如精挑细选”。
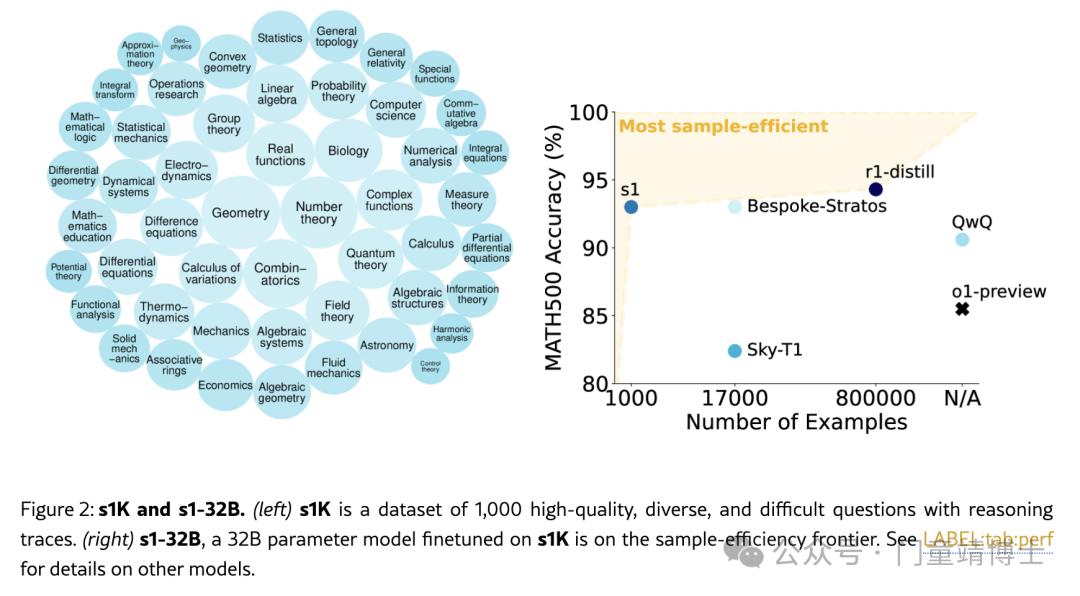

通过使用s1K数据集,结合简单有效的预算控制方法(例如预算强制),可以在大大减少训练样本的情况下,实现高效的推理模型,并在多个数学推理任务中表现出色。
2.2 预算强制:AI的“定时器”与“延长术
-
紧急刹车:当模型想用1000个token“速战速决”时,强行插入终止符逼它交卷
-
思考续杯:若模型过早想结束,就不断追加“等一下!”提示,诱导深入检查
-
生动案例(如图3):模型最初算出答案2,被强制延长思考后,通过验算发现应为3。这像极了人类解方程时“代回检验”的过程。
三、结果震撼:小模型的“四两拨千斤”
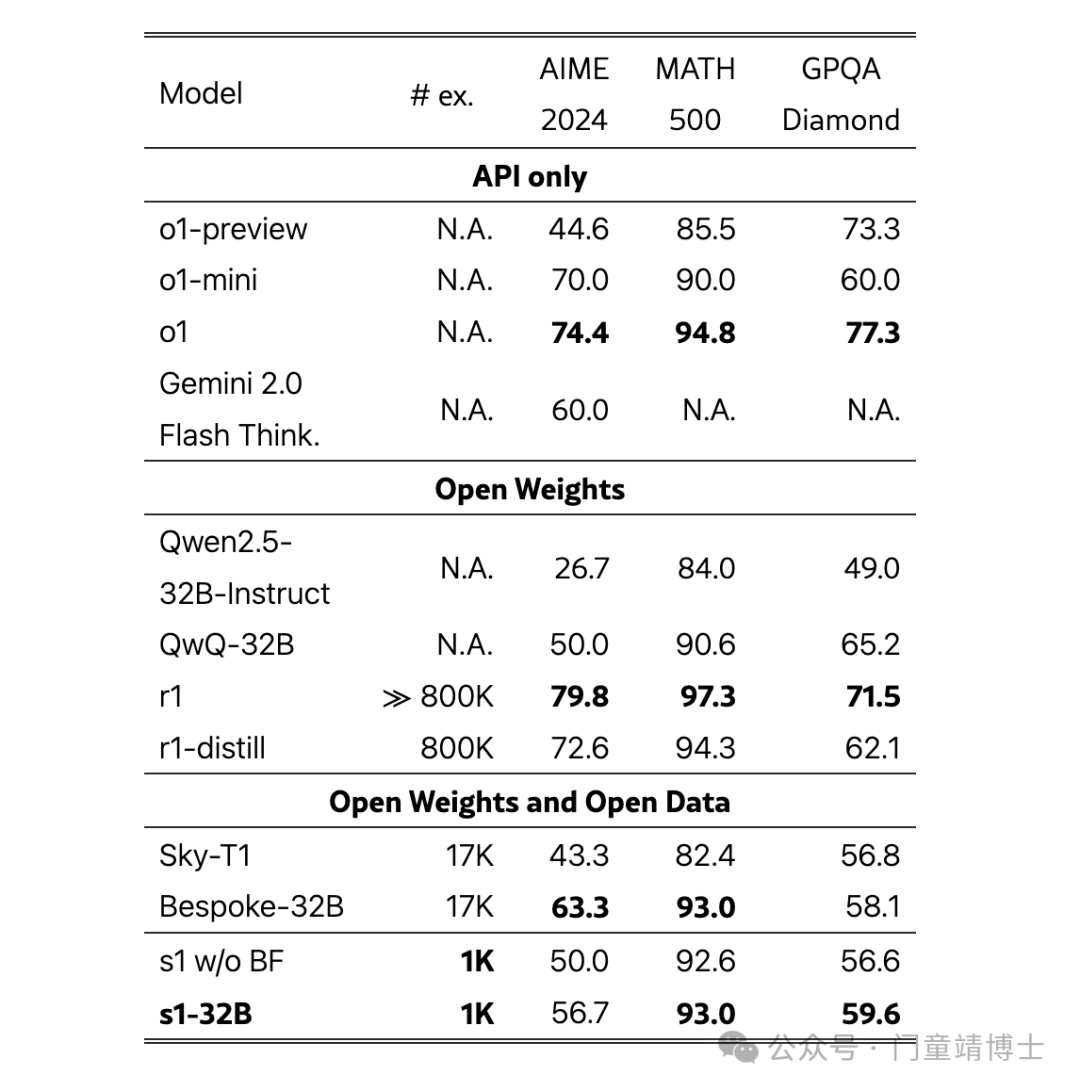
3.1 性能对比
|
|
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
| s1-32B | 1000题 | 56.7% |
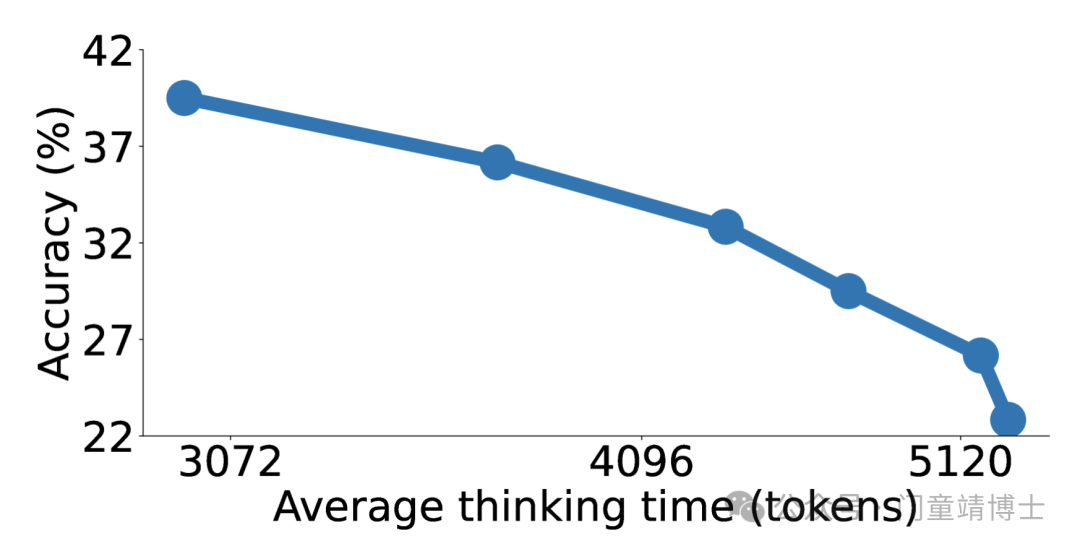
3.2 计算扩展的“神奇曲线
通过调整思考时长,模型表现呈明显上升趋势:
-
基础模式:消耗2000个token,正确率50%
-
深度模式:消耗7000+个token,正确率57%
这证明AI像人类一样,投入更多思考时间确实能提升准确率——尽管边际效益会递减。
四、启示录:AI推理的“少即是多”
4.1 反直觉的发现
-
数据质量 > 数据数量:1千题精训胜过59万题粗放训练
-
激活潜能:大模型预训练时已掌握推理能力,只需少量优质数据“唤醒”,这类似于教育中的“题海战术vs错题本”之争:盲目刷题不如针对性突破薄弱点。
4.2 开源的力量
团队公开了模型、数据和代码(GitHub链接),任何开发者都能复现实验。这种开放性,或将终结大厂用“黑箱模型”垄断AI能力的时代。

五. 论文结尾: “透明度”推进研究进展
具有强大推理能力的语言模型有可能极大地提高人类的生产力,从协助复杂的决策到推动科学突破。
然而,推理领域的最新进展,例如 OpenAI 的 o1 和 DeepSeek 的 r1,缺乏透明度,限制了更广泛的研究进展。未来的工作旨在以完全开放的方式推动推理领域的发展,促进创新和协作,以加速最终造福社会的进步。
结语:一场优雅的智力逆袭
s1模型的故事,就像《射雕英雄传》中郭靖练降龙十八掌——不在于招式复杂,而在于精准发力。
当整个AI界沉迷于“更大更多”时,这项研究证明:精心设计的小数据+巧妙的计算控制,同样能创造奇迹。
或许在不远的未来,我们手机上的AI助手,就能用这种“多想两步”的智慧,轻松解决孩子的奥数难题。
参考文献:
[1] https://arxiv.org/html/2501.19393v2
[2] https://github.com/simplescaling/s1
关注我,了解学术研究之路中关于AI的一切~
原创文章,作者:门童靖博士,如若转载,请注明出处:https://www.agent-universe.cn/2025/02/37715.html