

继上篇拳打Google,脚踢Perplexity,Genspark要做美女给你打好饭还喂进嘴!的新物种之后,景鲲带领的天才产品团队又推出了令人惊艳的新产品:Autopilot。
这篇文章不长,通过5个问题,黄叔快速的和大家一起来过一下这款产品,以及背后的一种新范式:
-
GenSpark的Autopilot是什么? -
每次搜索都会走多轮反思么? -
最终答案有没有明显提升?全网首个深度评测 -
提升的背后成本值当么? -
新范式和OpenAI的o1有没有相同之处?
01 Autopilot是什么?
Autopilot通过多轮反思和交叉验证,实现了更深入、全面的搜索结果。
之前GenSpark不是就上了AI搜索能力嘛,现在相当于在搜索里再增加一个小型的“思考加强器”,这样让搜索根据结果的质量进行多轮反思和交叉检查,相当于给AI安排了一个内部研讨会,目的就是让它的回答变得更加靠谱和全面。
我们具体来看下产品形态:
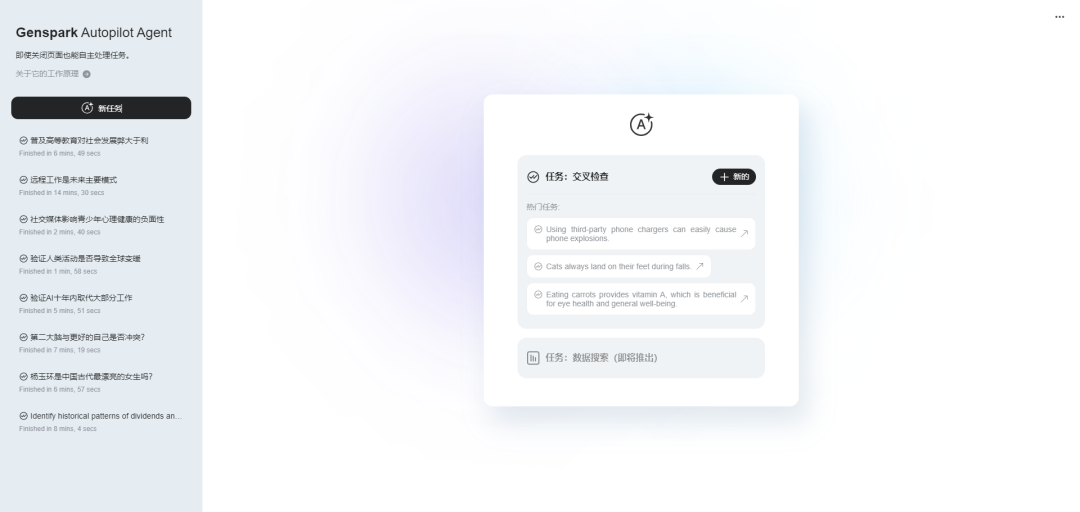
这是整个Autopilot产品的首页,可以看到由左侧边栏和右侧主体两部分构成
左侧是任务相关的列表,右侧显示的是任务界面。
可以看到当前第一阶段的功能是:交叉检查,也就是Cross Check
我们来看其中一个耗时最长的任务:“远程工作将成为未来的主要工作模式”,看看它会生成什么结果:
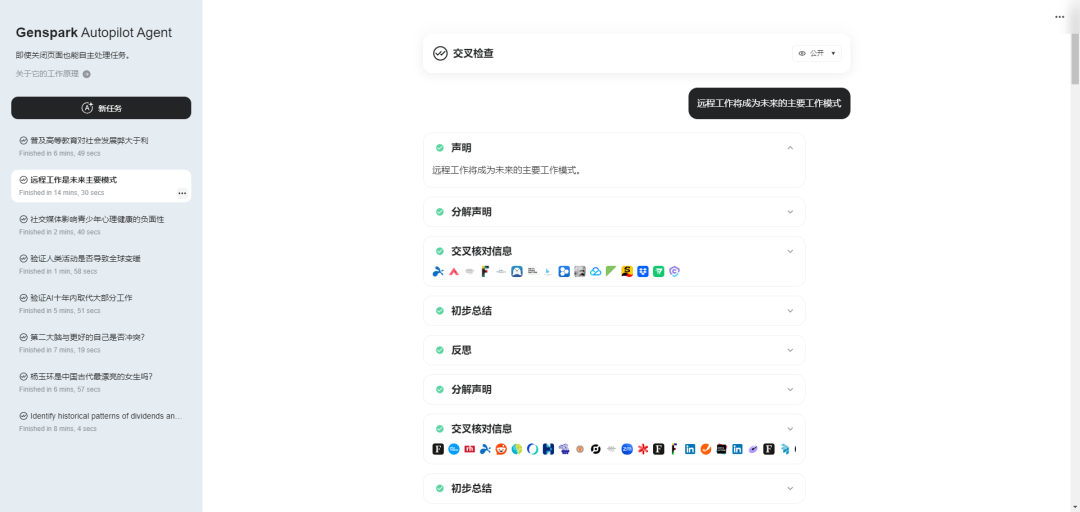
可以看到,主体部分是有非常多的内容,我们挨个来看一下,它分为多轮:
第一轮,正常进行拆词和搜索,并对信息进行总结:
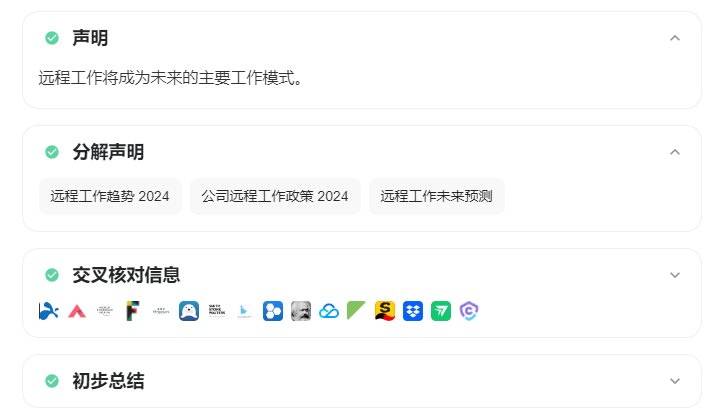
然后是第二轮,这一轮针对第一轮的总结,进行反思,找到新的探索角度,继续去检索,然后再次总结:
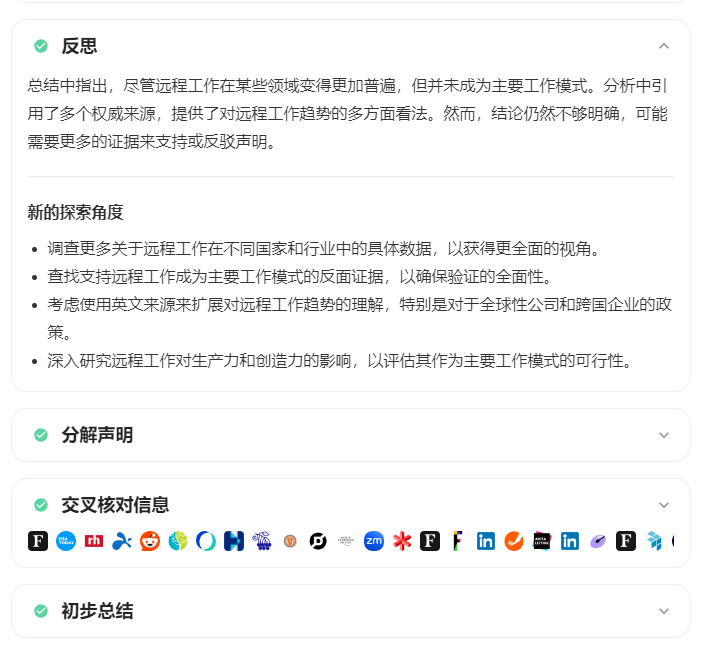
接着是第三轮,再来一次反思、检索、总结
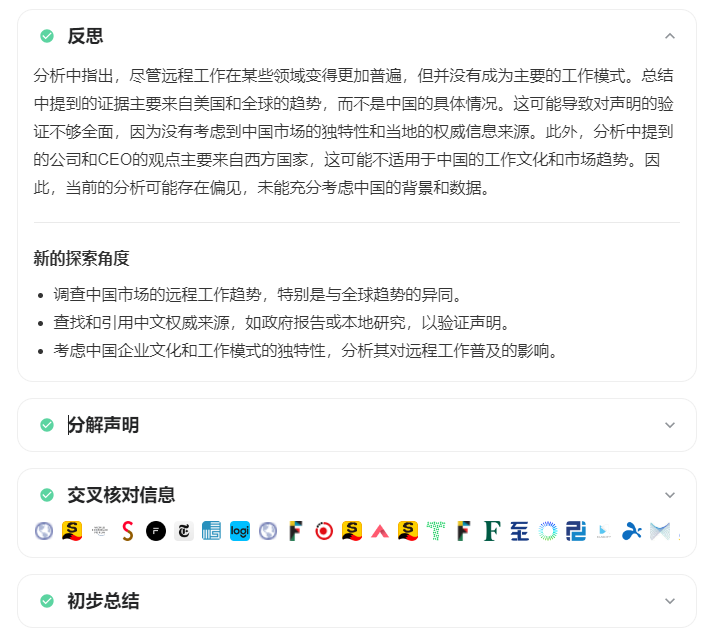
然后是第四轮:
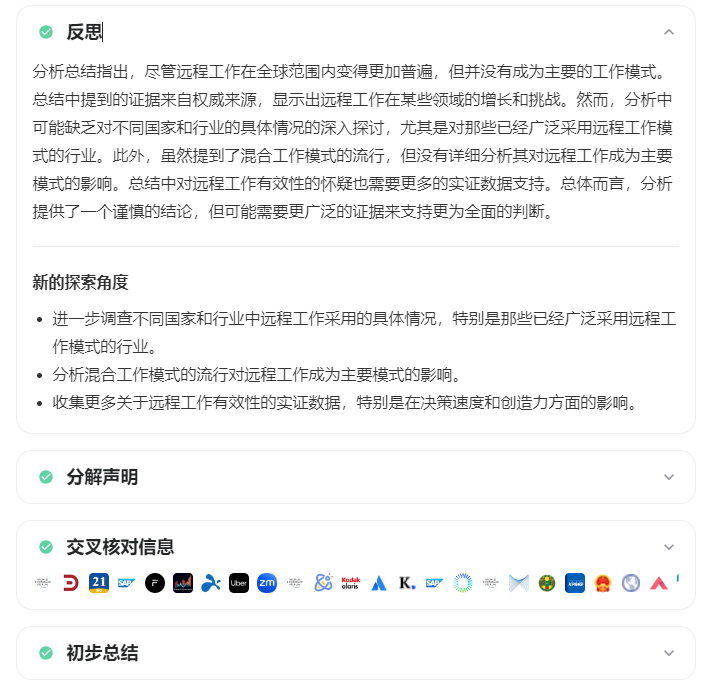
最后第五轮进行再一次反思后,形成最终结论,并给出详细分析:

在最终总结的详细分析里面,会给出Smart Inline Screenshots,自动找到相关度高的文本内容,并用高亮背景色标注出来,非常清晰:

可以看到,整个Autopilot的工作流程,有点这种感觉:
-
先让同行评议(交叉核对信息),然后先来生成一个初始回答。 -
然后开始自我反省,就像一个对自己要求贼高的演员,对着答案琢磨怎样才是更好的,遗漏哪些角度了? -
反复上面两个动作,直到觉得差不多了,对最后的答案润色,准备登台!
那么,接下来的问题是:
02 每次搜索都会这么多轮反思么?
Autopilot的反思轮数是动态的,根据反思质量可能是0轮、1轮或多轮,以达到最佳效果。
我们稍微抽象一下,上面说的case里,总共做了这么多个动作,看着都吓死你:
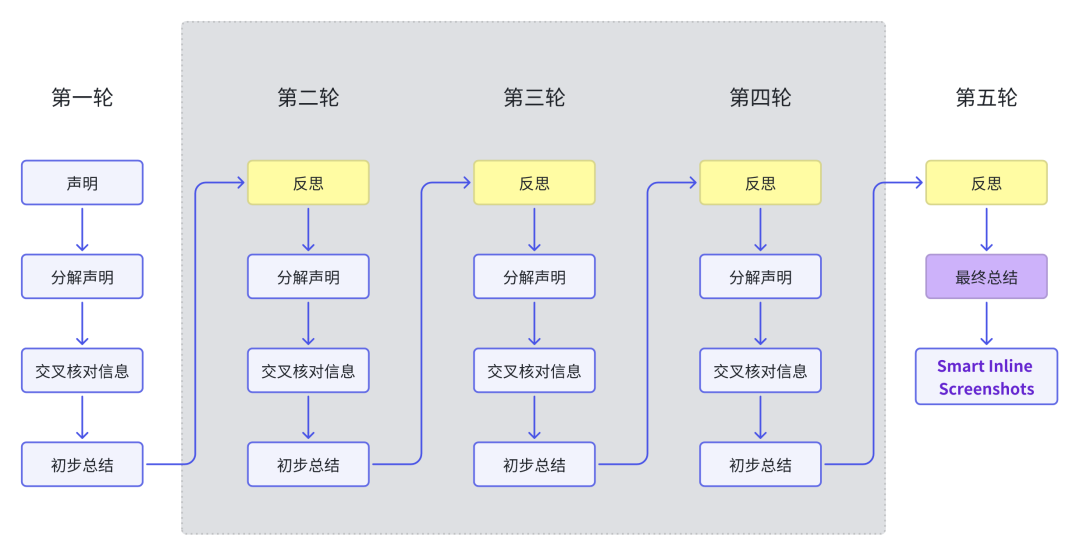
根据我测试的几个用例来看,这里面灰色部分是不一定会执行的,根据反思的质量,可能是0轮,也可能是3轮,对应消耗的时长也会有很大不同。
这里面黄叔猜测应该是对问题的复杂度,答案的精准性有一定的衡量标准:
03 增加了多轮反思,答案有明显提升么?
多轮反思确实能提升答案质量,尤其在复杂问题上效果更为明显。
OK,不光看花里胡哨,具体的效果,我们直接看第一次的初步总结,和最终总结的差异,这样来做比对。
(想节约时间的话,可以忽略初步总结和最终总结的文字部分,直接看Claude分析的结论部分)
先看一个上面耗时最长,花了14分钟的“远程工作将成为未来的主要工作模式”这个问题:
初步总结:
在审查了27个来源后,我们可以得出一个谨慎的结论,即“远程工作将成为未来的主要工作模式”这一声明并不完全准确。虽然远程工作在过去几年中变得更加普遍,尤其是在COVID-19大流行期间,许多公司被迫采用远程工作模式以维持运营,但它并没有成为大多数公司的主要工作模式。许多公司仍然倾向于混合模式,允许员工在家和办公室之间灵活切换。部分证据还表明,远程工作的比例在某些领域有所下降,尤其是在高薪职位中,这表明远程工作并未成为主导模式。此外,一些公司和高管对远程工作的有效性持怀疑态度,认为它在某些方面存在弱点,如决策速度和创造力的缺乏。因此,尽管远程工作在未来可能会继续增长,但目前的证据并不支持它将成为主要工作模式的结论。我们在分析中优先考虑了来自权威来源的证据,并注意到了时间线,以确保结论的准确性和可靠性。
最终总结:
在审查了161个来源后,我们可以得出一个谨慎的结论,即“远程工作将成为未来的主要工作模式”这一声明并不完全准确。尽管远程工作在过去几年中变得更加普遍,尤其是在COVID-19大流行期间,许多公司被迫采用远程工作模式以维持运营,但它并没有成为大多数公司的主要工作模式。许多公司仍然倾向于混合模式,允许员工在家和办公室之间灵活切换。部分证据还表明,远程工作的比例在某些领域有所下降,尤其是在高薪职位中,这表明远程工作并未成为主导模式。此外,一些公司和高管对远程工作的有效性持怀疑态度,认为它在某些方面存在弱点,如决策速度和创造力的缺乏。因此,尽管远程工作在未来可能会继续增长,但目前的证据并不支持它将成为主要工作模式的结论。我们在分析中优先考虑了来自权威来源的证据,并注意到了时间线,以确保结论的准确性和可靠性。
我们让Claude3.5来分析两次总结的异同:
在比较这两段文字后,我们可以发现,尽管信息源的数量从27个增加到161个,但最终的结论和主要论点基本保持一致。这两段文字几乎完全相同,只有开头的信息源数量有所不同。这种情况表明,增加信息源的数量并没有显著改变结论的质量或内容。
再来一个Case:第二大脑和更好的自己,是不是冲突的?
初步总结:
在分析了24个来源后,我们发现没有直接证据表明“第二大脑”和“更好的自己”之间存在冲突。大多数证据描述了“第二大脑”作为一种知识管理系统的功能,旨在通过组织和利用信息来增强个人的创造力和生产力。另一方面,“更好的自己”通常与个人成长和自我提升相关。虽然这两个概念在功能和目的上有所不同,但现有证据并未显示它们之间存在直接冲突。相反,“第二大脑”可能被视为一种工具,帮助个人更有效地实现“更好的自己”。因此,尽管没有直接证据表明这两个概念之间存在冲突,但它们可以被视为互补的关系。请注意,这一结论是基于现有证据的推论,可能存在局限性和不确定性。
最终总结:
在分析了156个来源后,我们得出谨慎的结论:没有直接证据表明“第二大脑”和“更好的自己”之间存在冲突。大多数证据描述了“第二大脑”作为一种知识管理系统的功能,旨在通过组织和利用信息来增强个人的创造力和生产力。然而,有证据表明,过度依赖这种系统可能会与个人成长或自我提升的目标产生冲突。尽管如此,“第二大脑”仍然可以被视为一种工具,帮助个人更有效地实现“更好的自己”。在本轮分析中,我们发现了一些关于AI工具作为第二大脑形式的潜在冲突的新证据,这些证据表明,尽管第二大脑可以支持个人发展,但也可能存在对个人价值和理解的威胁。这些新信息为我们提供了更全面的视角,帮助我们更好地理解第二大脑和更好的自己之间的关系。
Claude的分析:
-
基本结论保持不变 -
初步总结没有提到潜在冲突,最终总结提到了过度依赖“第二大脑”可能会和自我提升产生冲突 -
最终总结额外提到了AI工具作为第二大脑形式可能带来的潜在冲突,包括对个人价值和理解的威胁。
可以看到,最终总结变得更加谨慎,对于基本结论之外的复杂情况有了更多挖掘。
再来官方使用的第一个例子:在正式电影系列中扮演詹姆斯·邦德的每位演员都至少出演过一部莎士比亚改编作品。
初步总结:
在检查了22个来源后,支持每位在官方电影系列中扮演詹姆斯·邦德的演员至少出现在一部莎翁改编作品的声明仅受到部分支持。证据证实丹尼尔·克雷格和蒂莫西·道尔顿参与了莎士比亚改编作品。然而,对于其他演员如肖恩·康纳利、罗杰·摩尔、皮尔斯·布鲁斯南和乔治·雷辛比等人,没有全面的证据。对这些演员信息的缺乏意味着无法完全验证该声明。分析突出了支持这种说法所需的全面数据的重要性,以及需要考虑来源的可靠性和完整性。虽然确认有些演员具有莎士比亚背景,但该声明仍未经证实适用于整个邦德演员组。这个结论是基于现有证据,并应谨慎解释,因为所提供数据存在局限性。
最终总结:
在检查了142个来源之后,尚无充分证据支持每位出演过詹姆斯邦德的演员至少出演过一部莎士比亚改编作品的说法。证据证实,丹尼尔·克雷格、蒂莫西·道尔顿、肖恩·康纳利和罗杰·摩尔参与了莎士比亚改编作品,证实了对他们的说法。然而,证据表明乔治·莱泽比没有参与莎士比亚改编作品,对他的说法进行了反驳。对皮尔斯·布鲁斯南是否参与莎士比亚改编作品没有确凿证据。分析突出了支持此类说法的全面数据的重要性,以及考虑来源的可信度和完整性的需要。尽管有些演员被证实拥有莎士比亚背景,但对邦德演员群体的整体说法仍未经验证。这一结论是基于现有证据,并由于所提供数据的限制应谨慎解释。这一说法部分得到支持,但并非所有出演过詹姆斯邦德角色的演员已被证实出演过莎士比亚改编作品。
Claude3.5分析:
确认参与莎士比亚改编作品的演员:
第一次回答:只确认了丹尼尔·克雷格和蒂莫西·道尔顿
第二次回答:确认了丹尼尔·克雷格、蒂莫西·道尔顿、肖恩·康纳利和罗杰·摩尔
对乔治·莱泽比的结论:
第一次回答:没有提供具体信息
第二次回答:明确指出证据表明他没有参与莎士比亚改编作品
结论的确定性:
第一次回答:相对模糊,更多强调信息不足
第二次回答:更加明确,指出部分演员已确认,部分未确认,一位被反驳
可以看出,最终结论在多轮反思和扩大了信息源后,有了更加明确的结论,答案的质量明显增加了。
做个总结,我自己测了几个case,加上官方的4个case,发现整体来说,有一半多的case答案的质量会有比较明显的差别,但也有一小半的case前后几乎保持一致。
这背后代表了什么?
04 交叉检查消耗的Token值当么?
交叉检查虽然消耗更多Token,但能显著提高答案准确性,对于重要决策很有价值
可以很明显的发现,交叉检查通过多轮的反思,不断的扩大信息源,最终希望实现更大范围的检索,以及做更全面的总结,保证最终的答案质量能够得到提高(保平争胜的感觉)。
在GenSpark官方的宣传blog里,也是这么说的:
事实调查或事实核对是人们使用互联网的最常见原因之一,但传统的搜索引擎会让了解真相成为一件费时费力的苦差事。这往往需要多次重复原始查询的措辞,并煞费苦心地交叉检查所提供的链接,但这些都不能保证内容的准确性。
也就是说,大家有一种担心,要么是大模型乱说(AI搜索),要么是网页内容乱说(传统搜索),GenSpark希望通过更长的时间,更多的反思,更多的信息源,来换取最终答案的更高质量。
这是一种选择:
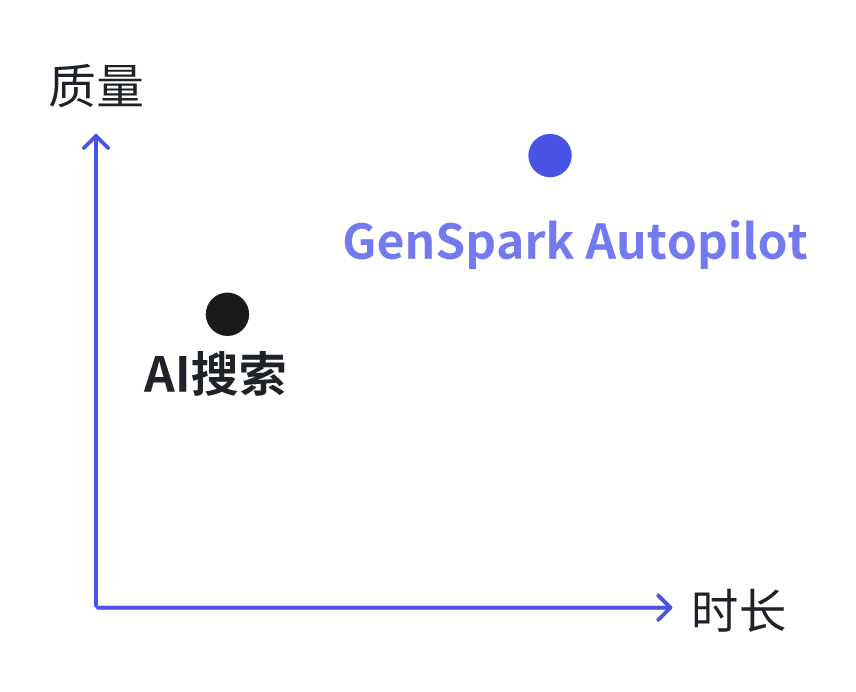
上图是一个示意版本,并不是真实量化。我们可以发现,GenSpark的Autopilot通过消耗更多的时长及Token,换取了更高的质量。
是否值当,就要看用户对问题质量的即时性要求及质量的关注度了。
GenSpark用自动、邮件提醒、Smart Inline Screenshots这些策略,希望尽可能弥补时长带来的影响。
05 背后的范式和o1有何异同?
Autopilot和o1都追求更高质量的输出
某种程度上,Autopilot有点点类似OpenAI新模型o1的理念:用更多算力和时间,换取更高质量的答案。
当然本质上又确实不同,Autopilot看起来更多只能是把质量提高一些,原本是60分的答案,提到80分。但o1可以把过去0分的题,现在能做到100分。
抛开这个不谈,都是时间换质量,那么,还有哪些场景,用户对于质量的需求要高于时间呢?
比如学术研究报告、医疗诊断、法律咨询、战略规划、代码开发都可以的。
举个例子,我用Cursor基于Claude3.5做AI编程的过程中,经常遇到的问题是,让改一个需求,结果AI把其他地方的正确代码也给改错了,导致出现bug,然后反复不停的改,这样算下来整体的时间就很长,但如果一次就能生成正确的代码,我是愿意多花一些时间等待的,只要总时长减少就是划算的。
ok,以上就是对GenSpark的Autopilot简要的分析,希望对你有启发。
对了,黄叔持续寻找和深聊AI从业者,希望能够为AI浪潮贡献更多的干货价值,欢迎AI从业者添加我的微信预约CoffeeChat:lookforward
原创文章,作者:Super黄,如若转载,请注明出处:https://www.agent-universe.cn/2024/09/21120.html