我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即
学术分析报告:ResearchFlow — 奇绩F23校友的开发的深度研究产品,PC端进入RFlow的分析报告,可直接点击节点右侧的小数字展开节点,登录后可在节点上直接“询问AI”,进一步探索深度信息 如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢 迎 大 家 一 起 交 流 !
潜空间活动报名
本期活动将在11月9日 10:00开始,我们邀请到的嘉宾是鱼哲,Lepton AI 创始成员,曾在阿里云担任高性能 AI 平台产品负责人,专注于 AI 在多个行业的落地及应用。Lepton AI 致力于建立高效可用的AI 基础设施,让团队更关注于应用构建及落地。在本次分享中鱼哲将带来关于不同AI产品形态对团队的挑战相关的思考,分享主题《Beyond Infra,What matters?—— 不同AI产品形态对团队的挑战》。除嘉宾分享外,每期设置了【匹配合伙人 Cofounder Matching】环节。你可以和 GenAI 时代最有活力的创业者和研究者线下面对面交流,将有机会找到志同道合、有共同创业梦想的小伙伴。报名通道已开启,欢迎扫描下方二维码报名。
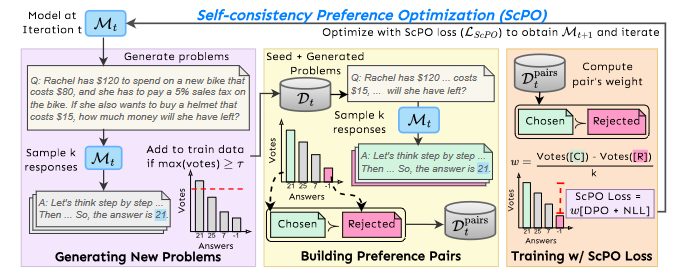
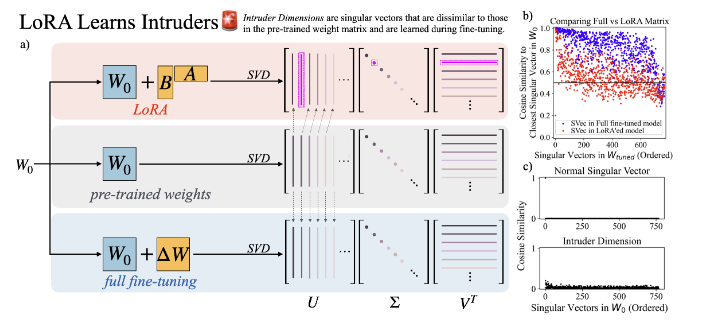
信号 From Decoding to Meta-Generation: Inference-time Algorithms for Large Language Models 现代大型语言模型 (LLM) 研究中最引人注目的发现之一是,在训练过程中扩大计算规模可以带来更好的结果。然而,很少有人关注推理过程中扩展计算的好处。本次调查重点关注这些推理时间方法。我们在统一的数学形式主义下探索三个领域:令牌级生成算法、元生成算法和高效生成。令牌级生成算法(通常称为解码算法)通过一次采样单个令牌或构建令牌级搜索空间然后选择输出来进行操作。这些方法通常假设可以访问语言模型的逻辑、下一个标记分布或概率分数。元生成算法适用于部分或完整序列,结合领域知识,实现回溯并集成外部信息。高效的生成方法旨在降低代币成本并提高生成速度。我们的调查统一了三个研究团体的观点:传统自然语言处理、现代法学硕士和机器学习系统。 https://x.com/srush_nlp/status/1854541184133480590 ResearchFlow:https://rflow.ai/flow/c4c978f8-fbcc-43e5-8375-31a7d926dfb5(PC端食用更佳) Self-Consistency Preference Optimization 自对准是一个快速发展的研究领域,模型可以在没有人工注释的情况下学习自我改进。然而,由于难以分配正确的奖励,现有技术往往无法改善复杂的推理任务。已知可以提高正确性的正交方法是自一致性,这是一种在基于多重采样的推理时应用的方法,以便找到最一致的答案。在这项工作中,我们扩展了自我一致性概念来帮助训练模型。因此,我们引入了自一致性偏好优化(ScPO),它迭代地训练一致的答案,在无监督的新问题上优先于不一致的答案。我们表明,ScPO 在推理任务(例如 GSM8K 和 MATH)上比传统奖励模型训练有很大改进,缩小了与黄金答案或偏好的监督训练的差距,并且将 ScPO 与标准监督学习相结合可以进一步改善结果。在 ZebraLogic 上,ScPO 对 Llama-3 8B 进行了微调,使其优于 Llama-3 70B、Gemma-2 27B 和 Claude-3 Haiku。 https://x.com/jaseweston/status/1854532624116547710 ResearchFlow:https://rflow.ai/flow/9eb6909e-3e1f-4d3c-bb15-7602941d9086(PC端食用更佳) LoRA vs Full Fine-tuning: An Illusion of Equivalence 微调是使预训练的大型语言模型适应下游任务的关键范例。最近,低秩适应(LoRA)等方法已被证明可以与各种任务上完全微调的模型的性能相匹配,同时大大减少可训练参数的数量。我们通过从模型的光谱属性角度分析模型的权重矩阵,研究不同的微调方法如何改变预训练的模型。我们发现完全微调和 LoRA 产生的权重矩阵的奇异值分解表现出非常不同的结构;此外,在适应任务分布之外进行测试时,微调模型本身表现出明显的泛化行为。更具体地说,我们首先证明用 LoRA 训练的权重矩阵具有新的、高阶奇异向量,我们称之为{入侵者维度}。在完全微调期间不会出现入侵者尺寸。其次,我们表明,具有入侵者维度的 LoRA 模型尽管在目标任务上实现了与完全微调相似的性能,但预训练分布的模型变得更差,并且对顺序的多个任务的适应能力较差。即使在相同任务上的性能与较低等级的 LoRA 模型相当,较高等级、等级稳定的 LoRA 模型也能紧密反映完整的微调。这些结果表明,使用 LoRA 和完全微调更新的模型可以访问参数空间的不同部分,即使它们在微调分布上表现相同。我们通过研究为什么入侵维度出现在 LoRA 微调模型中、为什么它们是不受欢迎的以及如何将其影响最小化来得出结论。 https://x.com/emollick/status/1854648003715551641 ResearchFlow:https://rflow.ai/flow/6c475c2a-5c20-4b9f-bb86-0ce9e6d60346(PC端食用更佳) LLM-engineer-handbook 这个项目是一个关于大型语言模型(LLM)的综合资源库,涵盖模型训练、部署、微调和应用开发等方面。它提供多种 LLM 应用开发框架,如聊天机器人和智能代理,收集大量相关数据集、基准测试和论文资源,并整理训练和部署的最佳实践。 https://github.com/SylphAI-Inc/LLM-engineer-handbook askrepo 这个项目是一个源代码阅读助手,使用谷歌生成式 AI 模型,能够从 Git 管理的文本文件中提取信息并根据用户问题生成答案。主要功能包括从指定目录获取 Git 跟踪的文本文件、使用谷歌生成式 AI 模型回答问题,并提供命令行界面供用户指定目录、模型和问题。 https://github.com/laiso/askrepo
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/11/21686.html