
MOLAR NEWS
2020年第26期
MolarData人工智能每周见闻分享,每周一更新。
AI新海诚就是在下,不信来玩


这样的东京街景,是不是有点日系纪实动漫那种feel了?
现在,不需要人类画师一帧帧描画,把你拍下的视频喂给AI,就能让现实世界分分钟掉进二次元世界。
布景:

美食:

甚至复仇者联盟,也能瞬间打破电影宇宙和漫画宇宙的界限。

这项研究名为White-box-Cartoonization,来自字节跳动、东京大学和Style2Paints研究所。论文已收录于CVPR 2020。
如此AI「魔法」的关键,还是生成对抗网络(GAN)。
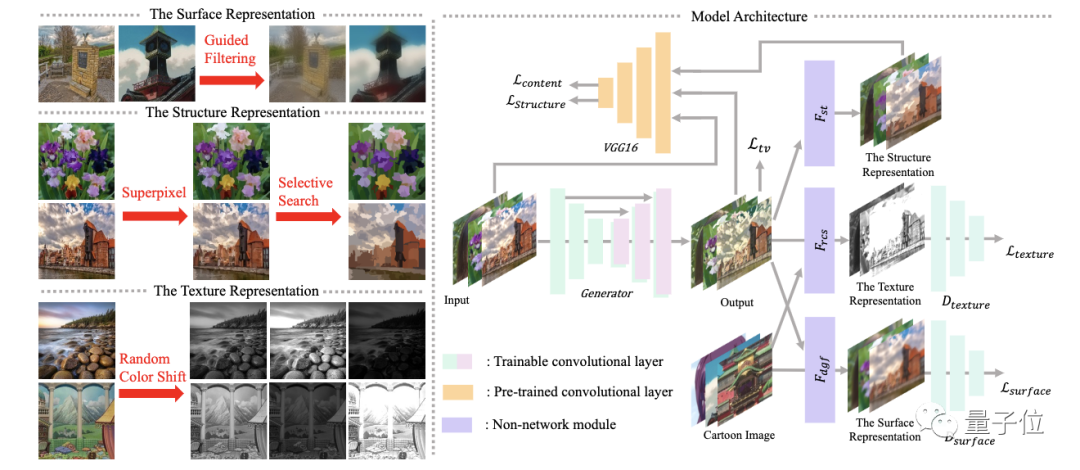
并且,研究人员提出了三个白盒表示方法,分别用来表示平滑表面、结构和纹理。
表面表示:表示动漫图像的光滑表面。
使用导向滤波器对图像进行处理,在保持图像边缘的同时平滑图像,去除图像的纹理和细节信息。
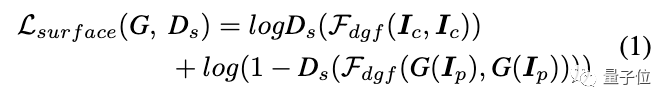
结构表示:获取全局结构信息和稀疏色块。
首先使用felzenszwalb算法将图像分割成不同的区域。
由于超像素算法只考虑像素的相似性而忽略语义信息,研究人员进一步引入选择性搜索来合并分割区域,提取稀疏分割图。

另外,标准的超像素算法会使全局对比度降低,导致图像变暗。
为此,研究人员提出了一种自适应着色算法,以增强图像对比度,减少朦胧效果。
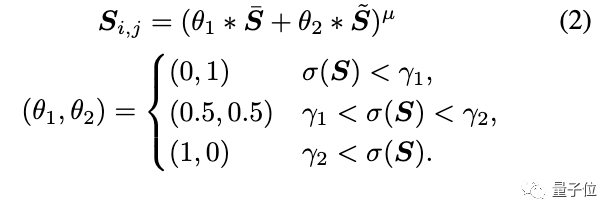
然后,用预训练的VGG16网络提取生成器生成的图像和抽取的结构表示的高级特征,限制空间结构。

纹理表示:反映卡通图像中的高频纹理、轮廓和细节。
研究人员提出了一种从色彩图像中提取单通道纹理表示的随机颜色偏移算法,以保留高频纹理,减少色彩和亮度的影响。
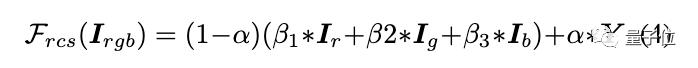
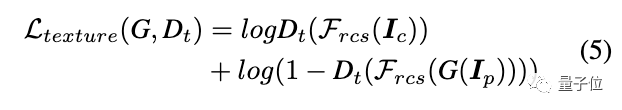
整个GAN框架带有一个生成器G,以及两个判别器Ds和Dt。其中Ds旨在区分模型输出的表面表示和真正的动漫图像。Dt用于区分模型输出的纹理表示和真正的动漫图像。
具体而言,生成器网络是一个类似U-Net的全卷积网络。
研究人员使用 stride=2 的卷积层进行下采样,以双线性插值层作为上采样,以避免棋盘式伪影。
该网络只由3种层组成:卷积层、Leaky ReLU(LReLU)和双线性调整层。这使得该网络能轻松嵌入到手机等边缘设备中。

判别器网络则基于PatchGAN进行了调整,其最后一层为卷积层。
输出特征图中的每个像素对应输入图像中的一个图像块(patch),用于判断图像块属于真正的动漫图像还是生成图像。
训练数据集方面,风景图像采集自新海诚、宫崎骏和细田守的动漫作品,人像图像则来自京都动画和PA Works。影片都被剪辑成帧并随机剪裁,大小为256×256。
所以,这种图像卡通化方法的效果究竟如何。
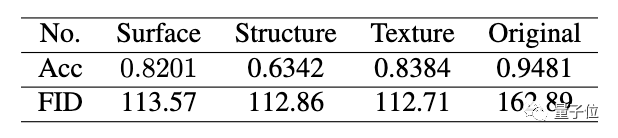
在定量实验中,研究人员发现,AI提取的表示成功愚弄了训练好的分类器。
与原始图像相比,分类器在三个提取的卡通表示中准确率都比较低。
另外,计算出的FID指标也显示,卡通表征有助于缩小真实世界照片和卡通图像之间的差距。
再来看一组直观的对比。

与之前的方法相比,白盒框架能生成更为清晰的边界轮廓,并有助于保持色彩的和谐。
比如,图中(f)-(g)所展示的CartoonGAN的某些风格就存在色彩失真的问题,而白盒框架色彩更为自然。
另外,白盒框架也有效地减少了伪影,效果超越CartoonGAN。
现在,研究人员还放出了在线Demo,如果你感兴趣,可以亲自上手试试~

最后,左边出自人类的画笔,右边是AI的大作,你pick哪一个?


 来源:亿欧网
来源:亿欧网
清华构建新一代数据集NICO,定义图像分类新标准
 每件事物的出现都有它各自的使命,我们今天提数据集就不得不提到ImageNet,ImageNet数据集及其它推动的大规模视觉比赛对人工智能特别是计算机视觉领域的巨大贡献是毋庸置疑的。
每件事物的出现都有它各自的使命,我们今天提数据集就不得不提到ImageNet,ImageNet数据集及其它推动的大规模视觉比赛对人工智能特别是计算机视觉领域的巨大贡献是毋庸置疑的。
正如李飞飞所言,ImageNet已经完成了它的历史使命,然而数据集的发展和变革却不能停下脚步。但是目前绝大部分的数据集都是基于独立同分布的实验场景设定,并没有考虑到数据本身的特性,也没有更多因果关系可言,这对于模型的泛化帮助甚微,也很难看到新一代数据集的萌芽。针对这些问题,近日,清华大学计算机系长聘副教授崔鹏团队构建了一个新型的具有跨数据集泛化性指标的数据集NICO,该数据集的发布旨在引起大家对新型数据集的更多关注,并促进对人工智能内在学习机制的研究。
NICO数据集我们都知道视觉模型的性能会随着测试环境的差异而发生变化,那么这种泛化性能的改变应该如何归因、又该如何提升呢?现在我们有了一个可以“控制”环境偏差并定量研究的图像数据集。近年来,深度学习技术使得视觉模型的性能得到了突飞猛进的发展,甚至在一些任务上超越了人类的平均水平,但这些结果背后的根基是海量的训练数据和独立同分布的实验场景设定。独立同分布(I.I.D.:训练环境和测试环境有相同的数据分布)是机器学习问题中最普遍的假设之一。I.I.D.假设的存在使得我们在最小化模型训练环境的风险损失的条件下,也能保证其在测试环境中也有好的表现。理想很美好,但现实呢?我们认为结论显然是否定的,在真实场景下由于时空的约束性,训练数据“一旦采集,就已落后”,时空维度上的跨度不可避免地会带来数据分布上的异质性,从而打破I.I.D.假设。例如对于自动驾驶而言,最大的考验就是不可预测的驾驶场景:更新换代的模型、不曾见过的街景、甚至是行人潮流穿搭上的变化都可能成为危险的诱因。那么为什么机器学习模型容易在数据分布变化时出现决策失误呢?因为它可能学到了不具备泛化性能的关联性。例如下图展示的例子,分类器训练时看到的狗大多在草地上、而猫大多在雪地上,为了最小化训练的风险损失,就可能把草地当作判断狗的要素;当测试时看到草地上的猫,它就会“指猫为狗”。

相对I.I.D.假设下的模型学习,这种训练环境和测试环境的数据分布不同的问题称为Non-I.I.D.或者OOD(Out-of-Distribution)。其实在视觉学习的领域,早在2011年MIT的研究者Antonio Torralba就在《Unbiased Look at Dataset Bias》一文中对于视觉任务中不同的标杆数据集之间存在偏差的现象作了初步的探索。该文提出已有视觉数据集的不断推出无非给视觉模型和算法一个单纯的”跑分“而已,对于深入理解视觉研究问题,“量变”似乎还无法引发“质变”。为此,该论文提出了一种“跨数据集泛化性”(Cross-dataset generalization)指标,即用来自不同数据集的图像分别构成训练集和测试集,通过模型性能的下降幅度来评估数据集之间的偏差,这种评估策略也逐渐成为日后领域自适应学习 (Domain Adaptation)中用于评价模型泛化性能的核心指标。由此,我们发现Non-I.I.D.远比想象的更加常见,甚至可以在最有公信力的I.I.D.图像数据集ImageNet上找到Non-I.I.D.的影子。ImageNet本身是一个树状结构,如动物类别“猫”下面还有更细化的子类“波斯猫”等。如果用不同的子类构成分类10种动物类别(“猫”、“狗”、“鸟”等)的训练和测试数据,数据环境会有什么变化呢?我们以特征空间上的分布差异指标NI(C)来描述单个类别C在训练和测试时的分布差异,用NI(C)在所有类别上的均值来衡量训练集和测试集的分布差异。

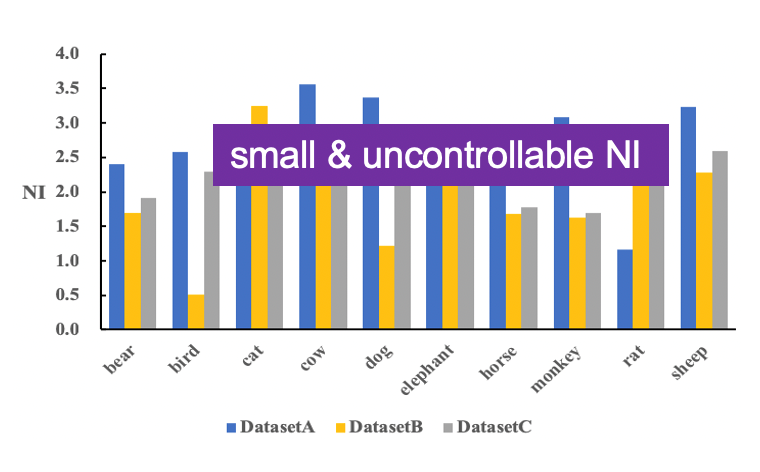
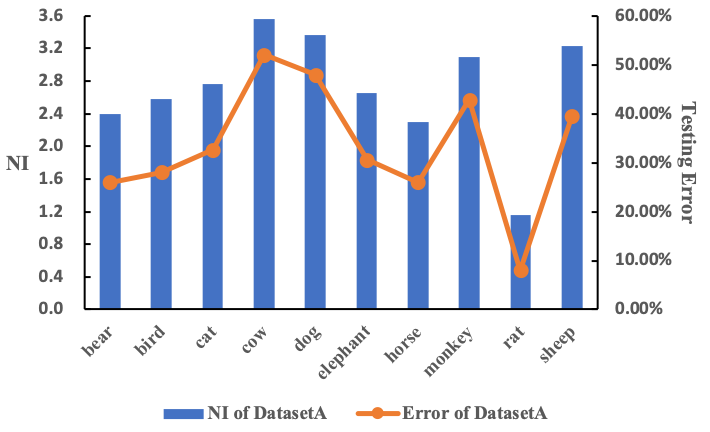
考察随机选择子类并构成的三个数据集A、B、C,可以看到:1)Non-I.I.D.普遍存在于各训练集的各种类别中;2)不同训练集的组成会带来数据分布差异的不同。然而,ImageNet等数据集并非为Non-I.I.D.问题而设计,它们能造成的数据偏差都不明显,偏差程度也很难调控,不足以支持充分的研究。我们还发现,数据分布的差异大小将直接影响模型学习的好坏。
区别于I.I.D.下传统图像任务的定义,Non-I.I.D.把“跨数据集泛化性”作为主要的评价标准。以基本的图像分类任务为例,Non-I.I.D.下的图像分类分为Targeted类和General类。两类任务的区别在于是否已知测试环境的信息,目标都是从训练环境中学习可以泛化到有数据分布偏差的测试环境的模型。显然,随着不同类型、任务、规模的数据集不断提出,单单通过排列组合来考察“跨数据集泛化性”带来的边际效应越来越低,从实际研究的⻆度出发,整个研究社区亟需⼀个可以系统、定量地研究数据分布偏差与模型泛化性能的标杆数据集。

在《面向分独立同分布图像分类:数据集和基线模型》(Towards Non-IID Image Classification: A Dataset and Baseline) 一文中,我们提出了一个带有“调节杆”的多分类图像数据集 (NICO),用于模拟训练和测试集分布不同条件下的图像分类任务场景,辅以定量刻画数据分布偏差的指标”Non-I.I.D. Index“ (NI)。通过“调节杆”,我们可以手动调节不同档位的NI,从而模拟一连串不同难度的场景,从接近经典数据集下的“无偏”环境平滑过渡到加入对抗信息的“极偏”环境中。

区别于其它标准数据集,构建NICO数据集的核心思想是以(主体对象,上下文)的组合为单位收集数据。同一个类别(主体对象),有多个上下文与之对应,描述主体内的属性,如颜色、形状等,或主体外的背景,如草地、日落等。为了实用性和适用性,我们从搜索引擎上与主体最密切的联想词中筛选出丰富多样的上下文,并保证不同主体的上下文有足够的重叠度。上下文实际上提供了围绕主体的有偏数据分布,通过在训练环境和测试环境组合不同的(主体对象,上下文),我们就能构建不同的Non-I.I.D.场景。可以构建的场景包括但不限于:1、最小偏差:NICO可达到的近似“I.I.D.”,通过随机采样使训练和测试环境的所有(主体对象,上下文)单元的数据比例相同。最小偏差描述了数据集本身的学习难度和数据噪声,此时的实验指标(如分类准确率)一般可作为best score。2、比例偏差:虽然训练和测试环境中出现(主体对象,上下文)的组合相同,但是不同单元之间的比例不同。比如,我们可以选择从指定上下文中收集某个类别的大部分训练数据,不同对象由不同上下文主导,就容易造成模型的参数偏差。实验表明,主导的上下文的比例越大,数据分布的差异也就越大。
原创文章,作者:整数智能,如若转载,请注明出处:https://www.agent-universe.cn/2020/08/8507.html