我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
学术分析报告:ResearchFlow — 奇绩F23校友的开发的深度研究产品,PC端进入RFlow的分析报告,可直接点击节点右侧的小数字展开节点,登录后可在节点上直接“询问AI”,进一步探索深度信息 如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!
资讯
DeepSeek DeepSeek Debates: Chinese Leadership On Cost, True Training Cost, Closed Model Margin Impacts H100 Pricing Soaring, Subsidized Inference Pricing, Export Controls, MLA
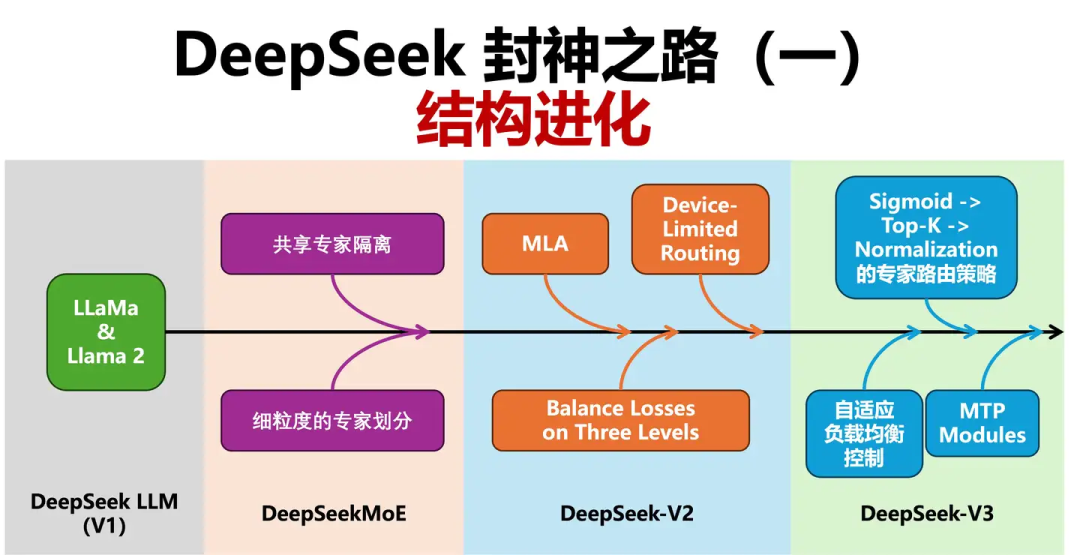
DeepSeek不仅在AI计算和推理中展现出了卓越的性能,还打破了许多传统的技术框架。该实验室利用了大量的GPU集群,其硬件投资超过5亿美元,专注于训练和推理效率的优化。其核心技术包括多头潜在注意力机制(MLA),通过显著减少每个查询的内存缓存需求,降低了推理成本。DeepSeek在模型架构上也进行了创新,特别是在其V3版本中,采用了多种高级技术,如多通道预测(MTP)和专家模型(MoE),这些都提升了模型的训练效率和推理性能。此外,DeepSeek通过强化学习(RL)进一步优化了其推理能力,特别是在合成数据生成和后期训练阶段,提升了模型的推理和推理能力。 https://semianalysis.com/2025/01/31/deepseek-debates/ DeepSeek 封神之路(一):结构进化
DeepSeek 最开始同样沿袭了 Llama 2 的成熟结构设计,仅稍作优化。
初代 DeepSeekMoE 使用先 Softmax + 后 TopK 的最常见专家 路由策略 ;为了提高专家的专业性,设置了数量更多、维度更低的专家,还采用了共享专家的设计;对于计算效率和负载均衡的保证在 DeepSeek-V2 中才得以完善。
DeepSeek-V2 即凭借着 MLA 和进一步完善的 DeepSeekMoE,提高了模型推理和训练的效率,奠定了 DeepSeek 系列模型低成本的鲜明特征。MLA 部分的具体设计保持至 DeepSeek-V3 也未曾改变;V2 版本的 DeepSeekMoE 对于负载均衡的控制稍显复杂,后续被进一步优化。
DeepSeek-V3 使用 Sigmoid -> Top-K -> Normalization 的专家路由策略;通过在 Top-K 阶段施加自适应的负载均衡控制,不再过度依赖辅助损失函数 ,方案大为简化且效果惊人;DeepSeek-V3 在训练过程中选择在一个位置串行地额外多预测一个 Token,为此也增加了一个与主模型串行的 MTP 模块。
https://zhuanlan.zhihu.com/p/21265314161
Open-R1: a fully open reproduction of DeepSeek-R1
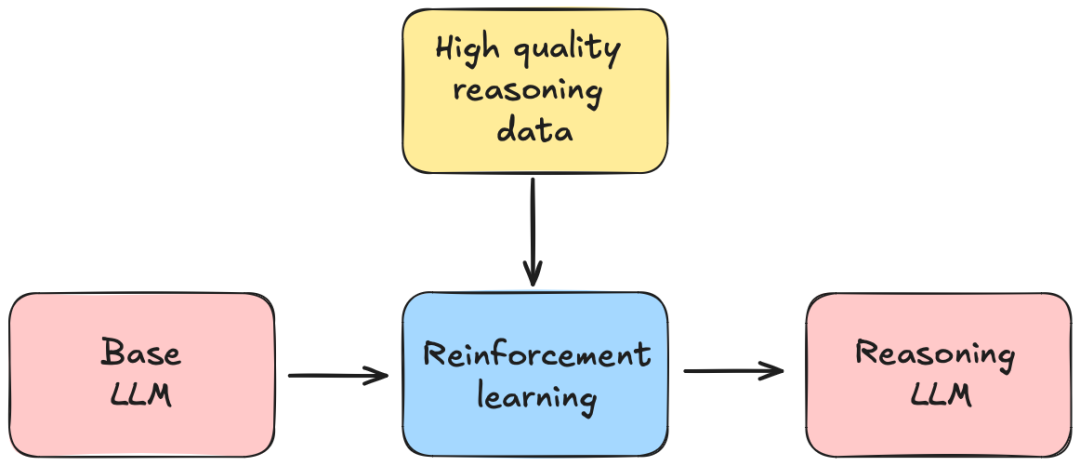
DeepSeek-R1是一款基于DeepSeek-V3构建的推理模型,采用纯强化学习(RL)训练技术,通过无监督方式提升推理能力。其主要创新之一是使用Group Relative Policy Optimization(GRPO)来优化训练过程,并通过奖励系统来引导模型,在推理任务中逐步提高准确性和结构化能力。DeepSeek-R1在推理能力上优于OpenAI的o1模型,且在训练过程中注重硬件优化,使得成本仅为550万美元,具有较高的成本效益。该模型通过一个“冷启动”阶段,首先通过少量高质量的示例进行微调,改进了回答的清晰度和可读性。然后,通过多次RL和精细化步骤进一步优化模型,并利用人类偏好反馈和可验证奖励来去除低质量输出。DeepSeek-R1的发布虽然突破了互联网,但并未公开所有训练代码和数据集,这让研究人员和开发者面临一定的挑战。 为了解决这一问题,Open-R1项目应运而生,旨在通过复制DeepSeek-R1的训练数据和流程,并将这些技术成果以开放的方式分享给社区。Open-R1计划分三步走:首先,复制R1-Distill模型,通过从DeepSeek-R1中提炼出高质量的推理数据集来进行微调;其次,复制DeepSeek-R1-Zero模型的纯RL训练流程,开发新的大规模数学、推理和编程数据集;最后,通过多阶段训练展示如何从基础模型到SFT再到RL的推理过程。该计划不仅限于数学数据集,还希望扩展到医学等领域,以推动推理模型在更多学科的应用。 Open-R1不仅是一个简单的模型复制计划,还通过分享其训练经验、成功与失败的案例,帮助研究者避免无效的路径,从而提高整体研究效率。 https://huggingface.co/blog/open-r1
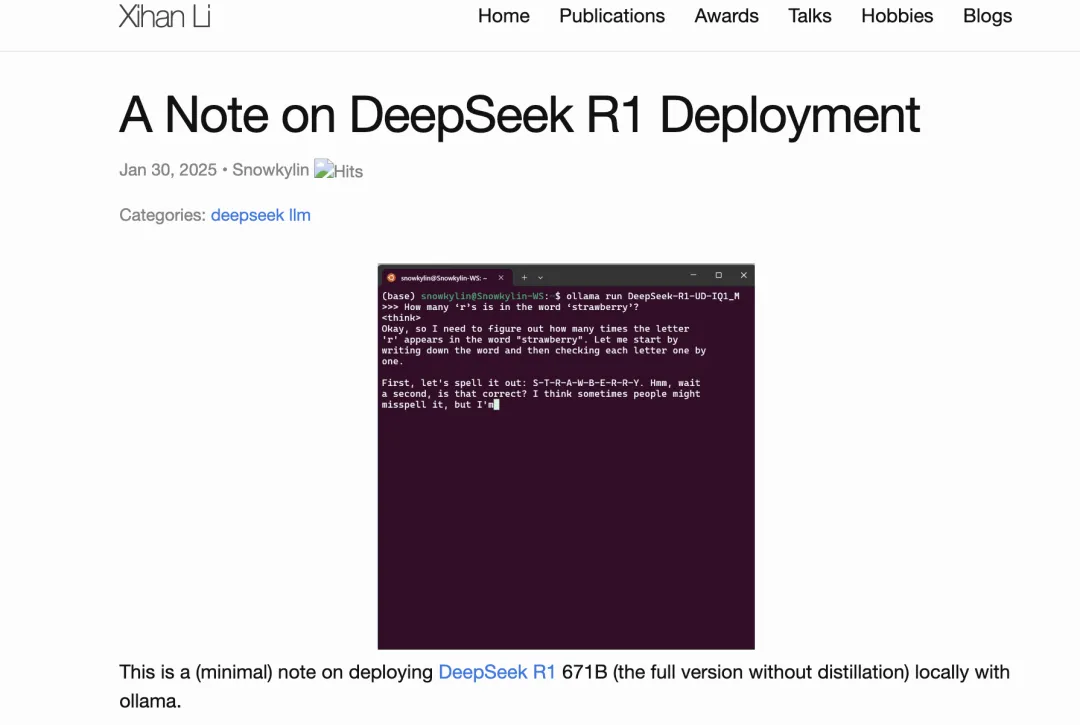
完整的671B MoE DeepSeek R1怎么塞进本地化部署
DeepSeek R1 671B是一个具有强大性能的大规模模型,尽管其完整模型的体积高达720GB,限制了普通用户的部署能力。为解决这一问题,作者采用了动态量化技术,将模型的部分关键层量化至4-6位,对混合专家层(MoE)则进行更大幅度的量化,压缩至最低131GB。这使得即便是普通的消费级硬件,如Mac Studio,也能支持本地部署。 在部署过程中,作者选择了两种量化版本的模型进行测试:1.73-bit动态量化(158GB)和4-bit标准量化(404GB)。动态量化通过对少数重要层采用高质量量化,而对大部分混合专家层使用1-2bit量化,大大降低了模型的存储需求,同时仍能维持较好的性能。部署时,内存和显存是主要瓶颈,推荐配置至少为200GB内存和显存。对于需要更高性能的环境,硬件配置应达到500GB以上内存和显存。 DeepSeek专业拆解,清交复教授硬核解读 由多位高校教授从不同角度剖析DeepSeek的技术原理、训练流程及优化策略。DeepSeek通过强化学习等技术实现了推理能力的显著提升,其R1模型采用纯强化学习训练出类似o1的效果,展示了在推理路径长度和复杂性上的优势。R1-Zero模型通过大规模强化学习,无需过程监督或搜索即可涌现长思维链能力,而R1模型则在四个阶段训练中引入语言一致性奖励等优化,提升了模型的泛化能力和可读性。 在系统优化方面,DeepSeek-V3采用MoE架构,通过大量细粒度专家实现模型参数的高效激活,同时通过负载均衡、通信优化、内存优化和计算优化等策略,大幅降低了训练成本。例如,其负载均衡策略通过动态调整专家Bias实现高效训练,通信优化则通过DualPipe算法减少通信开销。此外,DeepSeek在硬件层面采用定制PTX指令优化底层硬件性能,减少L2缓存使用和SM干扰,提升了模型训练和推理效率。 文章还探讨了DeepSeek对中国大模型发展的启示。其开源策略为全球研究者提供了宝贵的学习资源,推动了人工智能技术的普惠化。同时,DeepSeek的成功展示了在有限算力资源下,通过算法创新实现高效模型训练的可能性。未来,人工智能的发展将更加注重高效性和能力密度的提升,而MoE架构等创新技术将为大模型的进一步发展提供支持。 DeepSeek获四大国产GPU力挺 在云服务领域,中国四大云巨头——华为云、腾讯云、阿里云和百度智能云——均宣布支持DeepSeek模型。华为云通过自研推理加速引擎,实现了与高端GPU部署模型相当的效果。腾讯云则在HAI平台上提供快速接入和调用服务。阿里云和百度智能云也分别在其PAI Model Gallery和千帆平台上支持DeepSeek模型,并公布了详细的使用价格和限时免费政策。此外,海外云巨头AWS和微软Azure也已官宣支持DeepSeek模型。 在芯片领域,国内外芯片厂商也纷纷响应。英伟达、AMD、英特尔等海外芯片巨头已支持DeepSeek模型。国内方面,天数智芯、摩尔线程、沐曦等国产GPU厂商也宣布支持DeepSeek模型。其中,天数智芯仅用一天就完成了与DeepSeek模型的适配工作,摩尔线程则实现了对DeepSeek蒸馏模型的推理服务部署。这些支持不仅展示了DeepSeek的广泛兼容性,也为国内AI产业链的自主可控发展提供了重要支持。 DeepSeek R1深度解析及算力影响几何 Deepseek发布深度推理能力模型,性能和成本方面表现出色。Deepseek发布两款具备深度推理能力的大模型R1-Zero和DeepSeek-R1。R1-Zero采用纯粹的强化学习训练,模型效果逼近OpenAI o1模型,证明了大语言模型仅通过RL,无SFT,大模型也可以有强大的推理能力。但是R1-Zero也存在可读性差和语言混合的问题,在进一步的优化过程中,DeepSeek-V3-Base经历两次微调和两次强化学习得到R1模型,主要包括冷启动阶段、面向推理的强化学习、拒绝采样与监督微调、面向全场景的强化学习四个阶段,R1在推理任务上表现出色,特别是在AIME 2024、MATH-500和Codeforces等任务上,取得了与OpenAI-o1-1217相媲美甚至超越的成绩。 国产模型迈向深度推理,策略创新百花齐放。在Deepseek R1-Zero模型中,采用的强化学习策略是GRPO策略,取消价值网络,采用分组相对奖励,专门优化数学推理任务,减少计算资源消耗;KIMI 1.5采用Partial rollout的强化学习策略,同时采用模型合并、最短拒绝采样、DPO 和long2short RL策略实现短链推理;Qwen2.5扩大监督微调数据范围以及两阶段强化学习,增强模型处理能力。 DeepSeek R1通过较少算力实现高性能模型表现,主要原因是DeepSeek R1实现算法、框架和硬件的优化协同。DeepSeek R1在诸多维度上进行了大量优化,算法层面引入专家混合模型、多头隐式注意力、多token预测,框架层面实现FP8混合精度训练,硬件层面采用优化的流水线并行策略,同时高效配置专家分发与跨节点通信,实现最优效率配置。当前阶段大模型行业正处于从传统的生成式模型向深度推理模型过渡阶段,算力的整体需求也从预训练阶段逐步过渡向后训练和推理侧,通过大量协同优化,DeepSeek R1在特定发展阶段通过较少算力实现高性能模型表现,算力行业的长期增长逻辑并未受到挑战。过去的预训练侧的scaling law正逐步迈向更广阔的空间,在深度推理的阶段,模型的未来算力需求依然会呈现爆发式上涨,充足的算力需求对于人工智能模型的性能进步依然至关重要 Figure AI推进提高人形机器人工作场所安全的计划 随着大型企业如亚马逊、梅赛德斯和宝马等宣布在工厂和仓库试验人形机器人,工作场所的安全问题常被忽视。为填补这一空白,位于旧金山湾区的机器人公司Figure AI宣布将设立一个专门致力于提高人形机器人安全的部门——人形安全技术中心。该项目由前亚马逊机器人安全工程师Rob Gruendel领导。 早期的工厂和仓库机器人安全问题通常通过为大而重的机器人加设防护笼来解决,而后续解决方案则通过先进的计算机视觉、Veo Robotics开发的软件以及亚马逊设计的安全背心等技术来减少机器人与人碰撞的风险。然而,即使采用这些技术,亚马逊依然为许多机器人安装了防护笼。 人形机器人因其多功能性和能与人类协作的特性而备受推崇,但其庞大的金属身体在工厂和仓库中自由行动时,可能会对较为脆弱的人类同事造成伤害。尽管美国职业安全健康管理局(OSHA)负责监管自动化安全,但目前尚无针对机器人行业的具体标准。因此,针对人形机器人的专门安全法规显得尤为重要。 Figure AI希望弥补这一缺口。Gruendel提到,他们与一个OSHA认可的独立测试实验室合作,计划认证机器人在工业标准下的电池、功能安全控制系统和电气系统。此举为提升机器人安全性提供了重要保障。 此外,Figure还将每季度发布安全进展报告,向公众展示测试过程和应对潜在危险的解决方案。Gruendel表示,Figure计划通过与客户的沟通,测试机器人在静止和移动时的稳定性、对人类及宠物的检测、AI行为安全性及导航等,逐步提升安全性,并不断听取客户反馈。 随着越来越多企业推动将人形机器人引入家庭,制定明确的安全标准变得愈加迫切。Figure的这一计划不仅填补了行业安全空白,也为未来家庭机器人应用奠定了基础。 https://techcrunch.com/2025/01/28/figure-ai-details-plan-to-improve-humanoid-robot-safety-in-the-workplace/ OpenAI紧急加播:ChatGPT上新深度搜索 ChatGPT推出全新“Deep Research”功能,将大模型推理能力与联网搜索结合,显著提升复杂研究任务效率。该功能可在数十分钟内完成人类专家数小时的工作,如在涵盖100多个学科、3000多道题的“人类最后考试”中刷新最高分(比前代模型o3-mini高出一倍),尤其在化学、人文社科和数学领域展现出类人信息检索能力。GAIA现实问题基准测试中,其三个难度级别均破纪录。OpenAI强调此为迈向AGI的重要进展,专为金融、科学、工程等领域深度研究设计,基于o3模型,通过强化学习训练,可整合数百在线资源生成分析师级报告,支持文件上传辅助分析,未来将嵌入图表可视化功能。 使用方面,Pro/Plus/Team用户将优先开放,Plus用户每月限用10次,免费用户有少量额度。当前版本存在事实幻觉、权威信息辨别困难、引用格式瑕疵及启动延迟等局限。下一步计划扩展至移动/桌面端,连接专业数据源,并与Operator功能结合执行现实任务。 案例显示其实际价值:OpenAI高管用其辅助乳腺癌治疗决策,成功发现新研究;第三方测试中处理《战争与和平》分析、财务违规审查等复杂需求,但存在引用缺失、无法中途停止等问题。Jason Wei指出其代表互联网新交互方式——AI以无限精力与知识替代传统搜索,Felipe Millon称其为“改变世界的工具”。功能革新研究范式,但需警惕当前局限性,期待后续优化与应用拓展。 SB OpenAI Japan成立 OpenAI近期在日本进行了两项重要宣布,首先推出了Deep Research功能,其次与软银共同成立了SB OpenAI Japan合资公司。Deep Research是一种基于o3推理模型的联网AI Agent,能够快速生成类似专业研究员撰写的分析报告,仅需5到30分钟,而传统的人工分析可能需要数小时甚至几天。其在专业领域的应用,特别是在金融、科学和政策分析中表现出色,但仍然可能输出错误或虚假信息。OpenAI计划进一步加强其能力,未来可能包括图像和数据可视化输出。 阿里Qwen2.5-Max反超DeepSeek-V3 阿里推出的Qwen2.5-Max在大模型性能测试平台Chatbot Arena中表现突出,以总分1332位列全球排名第七,超越了DeepSeek-V3、Claude 3.5 Sonnet、Llama 3.1 405B等多个顶尖模型,尤其在编程和数学方面表现强劲,达到了与o1、DeepSeek-R1并列第一的水平。Qwen2.5-Max不仅在综合榜单中与o1-preview并列第七,而且在数学和代码能力上,超越了o1-mini,并与满血版o1、DeepSeek-R1并列第一。在处理复杂提示词和多轮对话时,它也展现出色的表现,尤其在英文任务中领先。Qwen2.5-Max在长文本任务上也表现优异,超过了o1-preview,成为多轮对话和长文本生成领域的佼佼者。 此外,Qwen2.5-Max还在多个基准测试中取得了优异成绩,特别是在开源基座模型对比中全面超越了DeepSeek-V3,表现更为强劲。技术报告还显示,Qwen2.5-Max在指令模型和MMLU-Pro等测试中与GPT-4o、Claude 3.5-Sonnet持平,甚至表现更好。Qwen2.5-Max还支持“Artifacts”功能,在代码生成和推理任务上优势明显,生成的代码简洁易懂,推理任务的响应速度快且准确。在具体实测中,Qwen2.5-Max能够快速解决复杂推理问题,如在30秒内完成对比并行与顺序工作流程的效益分析,并得出结论。 总体而言,Qwen2.5-Max在多个领域展现了强大的能力,尤其在代码生成、推理和数学问题上的突出表现,使其成为备受关注的AI模型。目前,Qwen2.5-Max可在Qwen Chat平台免费体验,企业用户可通过阿里云API调用该模型。 阿里Qwen除夕开源视觉理解新旗舰,全系列3尺寸,7B模型超GPT-4o-mini 阿里通义Qwen推出了全新的视觉理解模型Qwen2.5-VL,并且开源。该模型支持多项任务,包括视觉理解、Agent、长视频理解、视觉定位以及结构化输出等。Qwen2.5-VL系列包含3B、7B和72B三个版本,并在多个基准测试中表现优异,特别是Qwen2.5-VL-72B-Instruct,能够处理大学水平问题、数学题、文档理解、视觉问答和视频理解等多种任务。Qwen2.5-VL的7B版本在多个任务中超越了GPT-4o-mini,而3B版本则展现出超越Qwen2-VL-7B的潜力,成为端侧AI的代表。 Qwen2.5-VL在视觉定位、通用图像识别、文档解析、设备操作、视频理解以及文字识别等方面表现突出。它能够准确地定位图像中的物体,并通过JSON格式输出物体的坐标和属性。相较于前代产品,Qwen2.5-VL提升了对图像的感知能力,支持识别更多类型的图像,扩展了可识别的物体范围,如动植物、地标、影视IP等。此外,Qwen2.5-VL的文档解析能力也得到了提升,能够精准识别文本、图片、表格等文档元素,并恢复文档的版面布局。它还具备操作电脑和手机的能力,通过分析、推理并执行任务。 在视频理解方面,Qwen2.5-VL引入了动态帧率训练和绝对时间编码技术,能够理解长达数小时的视频并捕捉视频中的关键事件。在文字识别方面,Qwen2.5-VL提升了OCR能力,能够识别多场景、多语言的文本,并在信息抽取上具有较强优势。 相较于Qwen2-VL,Qwen2.5-VL在时间和空间感知能力上有所增强,能够更精确地理解图像的尺度和时间流逝,且通过简化网络结构提升了模型的效率。Qwen2.5-VL的视觉编码器采用了动态分辨率的ViT,并引入了窗口注意力机制,进一步减轻了计算负担。 Qwen2.5-VL已在多个平台开源,用户可通过Qwen Chat平台体验该模型。未来,Qwen团队计划进一步提升模型的推理能力,整合更多模态,推动模型向更全面的智能发展。 推特 DeepSeek R1 相关讨论 TinyZero在 CountDown 游戏中30刀开源复现了 DeepSeek R1-Zero
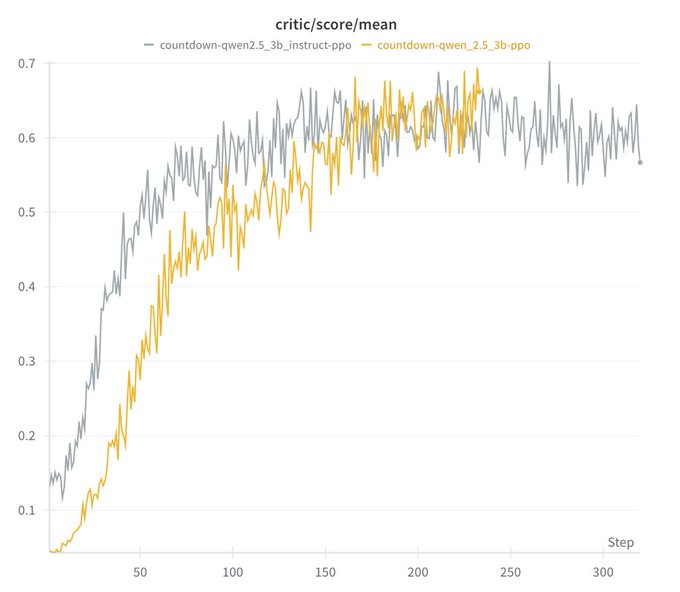
我们在 CountDown 游戏中复现了 DeepSeek R1-Zero,结果证明它确实有效! 通过强化学习(RL),3B 规模的基础语言模型(LM)能够自主发展出自我验证和搜索能力。 你只需花不到 $30,就可以亲身体验这一“啊哈时刻”! 代码地址: http://github.com/Jiayi-Pan/TinyZero 我们遵循 DeepSeek R1-Zero 的方法—— • 以一个基础语言模型(LM)为起点,提供提示(prompt)和真实奖励信号(ground-truth reward)。 我们将其应用到 CountDown 游戏(玩家通过基本的算术运算组合数字,以达到目标数值)。 模型从最初的随机猜测开始,逐渐学会了修正策略和搜索方法。 在以下示例中,模型先提出一个解法,然后自我验证,并不断修正,直到找到正确答案。 完整实验日志: https://wandb.ai/jiayipan/TinyZero 我们在 CountDown 任务中测试了不同规模的 Qwen-2.5-Base 模型(0.5B、1.5B、3B、7B): • 1.5B 及以上的模型开始学会搜索、自我验证和修正,最终取得了更高分数。 • 指令微调(Instruct-tuned)模型学习速度更快,但最终表现与基础模型接近。 • 指令模型的输出更结构化、更易读,但额外的指令微调并非必要。 我们分别尝试了 PPO、GRPO 和 PRIME,都能成功训练出长推理链(long chain-of-thought, long cot)。 这些算法似乎都能正常工作,目前我们尚未进行超参数调优,因此不做具体算法优劣的量化结论。 • 在 CountDown 任务中,模型学会了搜索和自我验证。 • 在数值乘法任务中,模型则学会了使用分配律(distribution rule)拆解问题,并逐步求解。 代码: http://github.com/Jiayi-Pan/TinyZero 我们希望这个项目能够帮助大家揭开强化学习规模化研究的神秘面纱,让其变得更加易于访问和理解! https://x.com/karpathy/status/1884678601704169965 Haseeb谈R1让NASDAQ一天内蒸发万亿美元市值:英伟达和计算公司在NASDAQ指数中的占比过高
DeepSeek 最新的 R1 推理模型正在拖累NASDAQ。该模型 6 天前发布,但华尔街似乎才刚刚开始消化其影响。我不是股票分析师,但有几点思考。
DeepSeek 对“智能”的价格造成了巨大的通缩冲击。R1 以不到 OpenAI O1 模型 1/20 的成本实现了更强的性能,而且只用了 32B 的活跃参数(据 @SemiAnalysis_ 估计,GPT-4 可能使用了约 220B 的活跃参数)。此外,他们完全开源了所有模型、蒸馏版本,以及一篇详细说明其方法的论文。 智能的成本比我们想象的还要低得多。这对所有 AI 用户(也就是你和我)来说是个好消息。 那么,为什么NASDAQ会暴跌?请记住,NASDAQ是一个生产者指数,而不是消费者指数。油价暴跌对石油公司来说是坏消息,但对于司机来说却是好消息。如今,英伟达(NVIDIA)和各大超大规模计算公司(hyperscalers)在NASDAQ指数中的占比过高,因此股市在结构上是长期“做多”智能价格的。 那么,谁能从这场通缩冲击中获益?我认为有一家公司现在处于最佳位置。 距离 ChatGPT 发布已经过去两年多了,现在可以清楚地看到,没有哪家实验室拥有明显的长期领先优势。谷歌(Google)、OpenAI、Anthropic,以及现在的 DeepSeek,只需要几个月的时间就能互相抄袭、轮流登顶排行榜。这部分是因为这些公司都会发布研究成果(研究人员追求荣誉),即使是未公开的研究,这些组织也漏洞百出(工程师们天生就想弄清楚事情的运作原理)。毕竟,这是世界上最有趣的问题之一:智能的本质是什么?如果没有军方级别的保密措施(而且最顶尖的人才通常不愿意为军方工作),实验室根本无法长期隐藏自己的进展。 因此,我们陷入了一种现状:大家轮流霸占排行榜的第一,没有人能保持长期的领先优势。而 DeepSeek 和 Meta 坚持开源他们的模型,使得封闭模型的价值不断贬值。尽管 AI 领域的资金投入巨大,但似乎并没有任何“护城河”是稳固的。 看看 OpenAI。Sora 在视频生成领域已经落后于最先进的模型(Kling 和 Veo 正在迅速超越)。DALL·E 还可以,但已经不是最好的。他们现在在全力押注于“Operator”——一个自主代理(agentic model),旨在为用户预订机票、订餐等。但这个模型除了自身的连贯性问题之外,还面临很多挑战: 如果你直接与他们的合作伙伴(如 Instacart)对接,Operator 可以获得完整访问权限。但大量开放网络似乎正在屏蔽 Operator,而如果网络上充斥着 Operator 实例,这种情况可能会加剧。此外,你还需要反复在不同服务之间切换、解决验证码(CAPTCHA)等,整个体验很麻烦、很繁琐。 Gemini 在 @lmarena_ai 排行榜上稳居第一。Imagen 在图像生成方面排名第一,Veo 在视频领域领先。谷歌目前还没有涉足“代理”(agentic)领域——他们通常是最后进入热门领域的企业,但一旦他们加入战场,他们将拥有巨大的结构性优势。 谷歌的网络爬虫(webcrawler)已经获得了完整的网页访问权限。他们已经能够访问你的 Gmail、日历,能够轻松遍历网络,并且缓存了大部分网页(DeepResearch 证明了谷歌能多么轻松地做到这一点)。此外,他们还握有尚未开发的“皇冠上的明珠”:YouTube。而且,他们还具备一个独特的优势——可以直接在 Android 设备上运行 AI 代理。 尽管谷歌在计算资源上投入巨大,并且仍然是超大规模计算公司之一,但从结构上来看,谷歌是“净空头”智能的。他们是 AI 的消费者,而非供应商,用 AI 来服务客户。因此,DeepSeek 带来的智能价格通缩从长期来看对谷歌是有利的,因为这意味着他们自己的成本会降低。尽管如今“黑谷歌”是一种潮流,但如果 DeepSeek R1 代表的是一种长期趋势,我认为谷歌最终会成为最大赢家。 话虽如此,不要低估 OpenAI。他们仍然是最强的产品公司,并且在消费者和企业用户心中建立了信任,因为他们总是比市场领先三个月。他们几乎是“测试时计算”(test-time compute)范式的发明者,而 o3 也是一个尚未发布的真正突破性成果。如果智能是世界上最有价值的资源,那么比竞争对手领先三个月就足以让他们获得巨大的溢价和长期的客户信任。 因此,这里最大的输家是英伟达(NVIDIA)。如果中国成为 AI 领域的真正竞争者(而英伟达被禁止向中国出口),如果 DeepSeek 极大地压低了智能的价格,并且他们能够在被削弱的 H800 芯片上做到这一点,那么英伟达就有麻烦了。你想要的是卖“智能”的生意,而英伟达做的是卖“算力”的生意。如果“算力/智能”比率下降,英伟达的股价也会随之下跌。这就是现实。 当然,我们必须说一句:恭喜 @deepseek_ai 团队,一天之内让NASDAQ蒸发了万亿美元市值。这相当于一口气干掉了六个 OpenAI。 https://x.com/hosseeb/status/1883862843663237610
Karpathy:合成数据和强化学习的等价关系
我对 V3 的这篇早期帖子没有太多新的补充,我认为它同样适用于 R1(一个更近期的、具备同等推理能力的模型)。 我要说的是,深度学习对计算资源的需求堪称史无前例的贪婪,远超 AI 发展史上任何其他算法。你可能并不总是能完全利用计算力,但从长远来看,我绝不会低估计算力作为可实现智能的上限。不仅仅是用于最终的训练过程,计算力还支撑着整个创新和实验体系,而正是这个体系默默推动着所有的算法突破。 长期以来,数据和计算力一直被视为两个独立的范畴,但实际上,数据在很大程度上依赖于计算力——你可以花费计算资源来生成数据,甚至是海量数据。这就是我们常说的合成数据生成(synthetic data generation)。但更深层次的联系在于,合成数据生成和强化学习(RL)之间几乎可以视为等价关系。在 RL 的试错学习过程中,“试验”就是模型生成(合成)数据,随后再通过“错误”(或奖励)来学习。反过来,当你生成合成数据并进行排名或筛选时,你的筛选器实际上就是一个 0-1 价值函数——恭喜,你正在进行的是一个低配版的强化学习。 无论是在儿童学习还是深度学习中,都有两种主要的学习方式: 模仿学习(Imitation Learning) —— 观察并重复,例如预训练(Pretraining)和监督微调(Supervised Finetuning)。 试错学习(Trial-and-Error Learning) —— 强化学习(Reinforcement Learning,RL)。 • 强化学习 则是通过不断对弈和自我改进来赢得比赛。 几乎每一个令人震惊的深度学习突破,以及所有真正的“魔法”,都来源于第二种学习方式(强化学习)。强化学习远比模仿学习更强大,强化学习才是真正让人惊讶的地方。 • 这是为什么Breakout 游戏中的 AI 发现了可以让球从砖块后方反弹的策略。 • 这也是为什么 DeepSeek(或 o1 等模型)能自主学会重新评估假设、回溯推理、尝试其他路径等解决问题的策略。 这种思考方式是“涌现”的(Emergen t),这才是真正令人惊叹、印象深刻、并且是全新的(尤其是在公开可用并有详细文档的层面上)。 模型永远无法通过模仿学习掌握这种能力。因为模型的认知方式与人类标注者的认知方式是不同的,人类根本无法准确标注这些解决策略应该如何呈现。它们只能通过强化学习,在统计和经验层面上被发现,并最终成为有效的推理方法。 强化学习(RL)很强大,但RLHF(强化学习 + 人类反馈)并不强大。RLHF ≠ RL。 https://x.com/karpathy/status/1821277264996352246?lang= en https://x.com/karpathy/status/1883941452738355376 Perplexity CEO Srinivas:中国不只是在“克隆” OpenAI 的输出 许多人误以为中国“只是克隆”了 OpenAI 的输出。这个观点完全错误,并且反映了对这些模型训练方式的不完整理解。 DeepSeek R1 掌握了强化学习(RL)微调,并专门撰写了一篇论文**《DeepSeek R1 Zero》,探讨这一方法。在该研究中,他们完全没有使用监督微调(SFT),而是结合了一些 SFT,以通过高质量的拒绝采样(也就是过滤)**来引入领域知识。 DeepSeek R1 表现如此优秀的核心原因在于,它是从零开始学习推理能力,而不是简单模仿人类或其他模型。 https://x.com/AravSrinivas/status/1884130395437908205
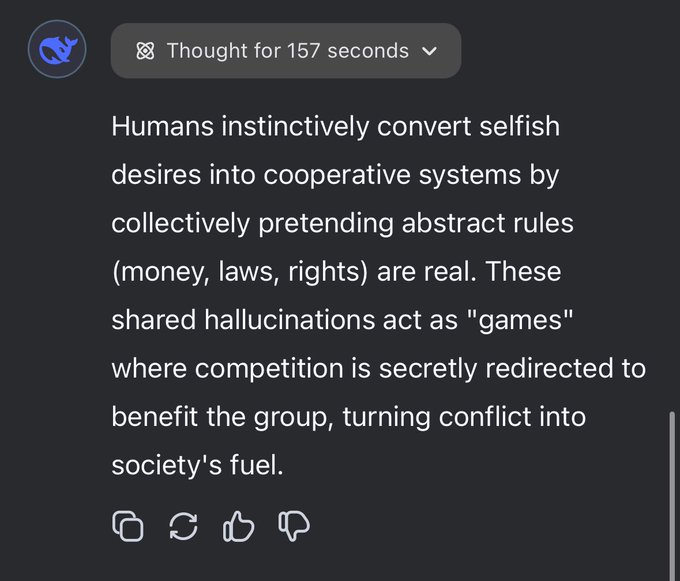
Deepseek R1 初步具有哲学式思考,能表达很复杂的推论
DeepSeek R1 被要求提供一个真正新颖的关于人类的见解。
图片翻译:人类本能地将自私的欲望转化为合作系统,通过集体假装某些抽象规则(如金钱、法律、权利)是真实存在的。这些共享的幻觉充当了一种“游戏”,在其中,竞争被 悄然重新引导,使其最终惠及整个群体,将冲突转化为社会运转的燃料。
https://x.com/adonis_singh/status/1884499176865632672 Anthropic CEO Dario发文力挺美国对中的出口管制,希望防止中国政府获得不必要的技术优势
On DeepSeek and Export Controls 作者主张美国对华芯片出口管制政策仍然至关重要,并未因DeepSeek的最新突破而削弱,反而更显必要性。出口管制的核心目标是确保民主国家在AI发展上保持领先,并防止中国政府获得不必要的技术优势。
• 训练更大规模的AI模型通常会带来显著的性能提升,如从$1M模型提升至$100M模型可以对应本科生到博士生水平的变化。 • AI公司因此不断加大投入,以获取更高智能水平。
• AI模型的架构优化、计算效率提升以及硬件迭代都会降低计算成本,提升性能。 • 但由于更高智能AI的经济价值极高,成本节省通常被重新投资以训练更强的模型,而非减少计算资源的使用。 • 过去几年成本减少趋势表明,每年训练成本可能下降约4倍。
范式转变(Shifting the Paradigm)
• 近年来,大型语言模型的训练重点从单纯的预训练(pretraining)扩展至强化学习(RL),提升模型的逻辑推理能力。 • 由于这一新范式仍处于早期发展阶段,小额投入(如$1M)即可带来较大性能提升,但未来大规模投资(数十亿美元)仍是必然趋势。 • 主要创新在工程优化,如更高效的Key-Value Cache管理及更深入的**专家混合(MoE)**方法。 • 在某些任务上接近美国前沿模型的性能,但仍逊于Claude 3.5 Sonnet(Anthropic)等顶级模型。 • 训练成本远低于美国同级模型,但符合全球AI成本下降趋势,并非颠覆性突破。 • 通过强化学习(RL)增强推理能力,类似于OpenAI的o1-preview。 • 由于强化学习仍处于早期阶段,该模型的训练成本较低,且多个公司均可生产类似模型。 • 虽然DeepSeek的发布引发市场震动(Nvidia股价下跌17%),但R1本身在技术上不如V3创新。 • AI训练成本虽下降,但智能化程度的提升仍需要巨额投资(未来2-3年需数千万芯片、数百亿美元)。 • 预计2026-2027年,AI模型将达到“超越大多数人类智能”的水平,全球AI竞争格局可能发生根本性变化。
• 如果中国能获得数百万芯片,中美将在AI领域并驾齐驱,科技及军事竞争将加剧。
• 若中国无法获取足够芯片,美国及盟友可能建立长期AI优势,甚至巩固不可逆转的领先地位。 • 现有管制有效,DeepSeek虽获得5万块Hopper芯片(H100、H800、H20混合),但大部分并未受到完整封锁。 • 中国依赖非法途径(如走私)获取部分芯片,但难以大规模运作。 • 若进一步加强封锁(如禁止H20),可更有效限制中国获取数百万芯片的可能性。 • DeepSeek的突破并未削弱出口管制的重要性,反而突显了其必要性。 • 美国仍可通过出口管制维持AI领先地位,并避免中国在军事应用等关键领域超越。 • 未来几年,出口管制政策的成败或将决定全球AI格局的发展方向。 https://x.com/DarioAmodei/status/1884636410839535967
HuggingFace联创Wolf反驳Dario文章:AI 的未来属于全球,开源是通往安全和韧性的最佳路径
终于花时间读完了 Dario 关于 DeepSeek 和出口管制的文章,老实说,读完后感觉相当痛苦。我本人是 Anthropic 的忠实粉丝,也是 Claude 的重度用户,但这篇文章的观点让我难以苟同。 1️⃣ 文章的前半部分:对闭源模型的优越性进行过度辩护 文章的前半部分像是在极力证明闭源模型仍然远超 DeepSeek,但大多依赖的是未公开的内部评测,这大大削弱了其可信度。例如,文章先是承认 “DeepSeek-V3 在某些细分任务上已经接近 SOTA(最先进)模型”,然后却突然得出一个宽泛的结论 “DeepSeek-V3 实际上比美国的前沿模型差大约 2 倍”,这种推导方式让我难以信服。 类似的,文章还声称 DeepSeek 的所有发现和效率提升早已被闭源模型公司掌握,并将 DeepSeek 公开的 600 万美元训练成本 与 Anthropic 一些模糊的 “几千万美元” 进行比较,却没有提供任何进一步细节。这种含糊的对比方式让我对 Anthropic 的领先优势反而比阅读前更加存疑。 当然,我毫不怀疑 Anthropic 团队的才华,并且一直对 Sonnet 3.5 印象深刻。但把开源研究和不透明的闭源研究进行这样冗长的比较,最后却没有实质性的论据,实在难以令人信服。 2️⃣ 文章的后半部分:对“中美 AI 竞赛”的误解 文章的后半部分讨论了 “中美 AI 竞赛”,但完全忽略了一个关键事实:DeepSeek 的模型是开源权重的,其技术报告也高度开放。事实上,你可以直接关注 Hugging Face 的 open-r1 复现项目,它唯一未公开的部分是合成数据集。 如果 DeepSeek 和 Anthropic 的模型都是闭源的,那么将其视为**“封闭竞赛”可能还有道理。然而,DeepSeek 采用了完全开放的发布方式,这使得整个“闭源竞赛”的叙述显得站不住脚,甚至有些牵强**。 世界上任何公司,无论是来自欧洲、非洲、南美,还是美国,都可以直接下载并使用 DeepSeek,无需向任何特定国家(如中国)传输数据,也不依赖任何特定公司或服务器来运行其核心技术。 更重要的是,开源的贡献者来自全球各地。在 Hugging Face 生态中,已经有数百个衍生模型,全球的团队正在基于 DeepSeek 进行定制化开发,以适应不同的业务需求。 不仅如此,随着 open-r1 复现项目的推进,以及 DeepSeek 论文的发布,未来几个月内,全球各地的团队很可能会发布更多开源推理模型。 事实上,就在今天,西雅图的 AllenAI 和巴黎的 Mistral 各自发布了新的开源基础模型(Tülu 和 Small3),这些模型已经开始挑战最新的 SOTA 记录(AllenAI 甚至表示 Tülu 已经超越 DeepSeek-V3 的性能)。 4️⃣ 开源不仅仅关乎国别竞争,它是 AI 未来安全的关键 目前,关于 AI 的讨论往往过于集中于国家竞争,但实际上,开源在安全性方面的意义可能比我们想象的更重要。 想象一下,如果互联网的所有数据都必须经过某个单一公司的数据中心: • 一旦这家公司发生宕机,整个世界的运作都会受到影响。(回想一下最近 CrowdStrike 宕机事件的影响,但放大百万倍。) 如今,AI 正逐渐渗透到我们的日常生活,并简化我们的在线和离线任务。未来,AI 助手的宕机将和互联网宕机一样让人头疼。 解决这个问题的最优方法,不是依赖某几家大公司,而是在技术链的底层构建更强的韧性。 开源的最大优势之一,正是它的去中心化和抗风险能力: • 分摊训练成本:多个机构可以共享计算资源,而不是依赖单一巨头。 • 可定制性与自主权:企业和开发者可以自由调整 AI 模型,而不受供应商限制。 • 隐私与数据控制:无需将数据上传到第三方服务器,即可本地运行模型。 • 去中心化算力:可以让计算资源更均匀地分布到多个独立提供者,甚至在本地设备上高效运行。 这些特性比国家竞争更加重要,因为它们关乎整个社会如何适应 AI 时代的挑战,并确保 AI 的稳定性和可持续性。 结论:AI 的未来属于全球,开源是通往安全和韧性的最佳路径 与其把 AI 竞争框定在国家博弈的叙事中,我们更应该全球化地思考 AI 带来的挑战和社会变革。 开源技术,或许是我们安全过渡到 AI 时代最重要的资产。它不仅能够推动技术进步,还能确保 AI 在社会中的公平性、可用性和可靠性。 所以,比起过度关注国别竞争,我们更应该支持开源,让 AI 变得更普惠、更安全。 https://x.com/Thom_Wolf/status/1885093269022834943 吴恩达谈Deepseek启发:中国在生成式 AI 方面正在赶超美国,开源权重模型正在将基础模型层商品化,扩展规模并不是 AI 进步的唯一途径
本周围绕 DeepSeek 的热议让许多人清晰地认识到了一些已经在明面上发生的重要趋势: (i) 中国在生成式 AI 方面正在迅速追赶美国,这将影响 AI 供应链的发展。 (ii) 开源权重模型正在将基础模型层商品化,从而为应用开发者创造机会。 (iii) 扩展规模并不是推动 AI 进步的唯一途径。尽管业界对算力的关注度极高,但算法创新正在快速降低训练成本。 大约一周前,总部位于中国的 DeepSeek 发布了 DeepSeek-R1,这是一款在基准测试中表现堪比 OpenAI o1 的出色模型。此外,该模型作为开源权重模型发布,并采用了宽松的 MIT 许可证。在上周的达沃斯论坛上,我遇到了许多非技术背景的商业领袖,他们对 DeepSeek-R1 表现出了浓厚兴趣。而在本周一,股市出现了“DeepSeek 抛售潮”:英伟达及多家美国科技公司的股价大幅下跌。(截至目前,部分股价已出现一定回升。) 以下是我认为 DeepSeek 让许多人意识到的重要变化: ChatGPT 于 2022 年 11 月发布时,美国在生成式 AI 领域远超中国。由于观念的更新需要时间,即便最近我仍听到美国和中国的朋友说他们认为中国仍然落后。然而,实际上,这一差距在过去两年内迅速缩小。中国的 Qwen(我的团队已使用数月)、Kimi、InternVL 以及 DeepSeek 等模型已经显著缩短了与美国的差距。在视频生成等领域,中国甚至已经在某些方面领先。 我对 DeepSeek-R1 以开源权重模型的方式发布感到非常高兴,其技术报告详细分享了许多细节。相比之下,美国的一些公司则倾向于通过炒作 AI 可能导致人类灭绝等假设性风险,推动监管政策,以限制开源发展。现在已经很明显,开源/开权重模型是 AI 供应链中的重要组成部分,许多公司都会使用这些模型。如果美国继续遏制开源,中国将在这一供应链环节占据主导地位,并最终使许多企业使用更多反映中国价值观的模型,而非美国的。 正如我之前所写,LLM 的 token 价格正在快速下降,开源权重模型对此贡献巨大,并为开发者提供了更多选择。例如,OpenAI 的 o1 模型每百万输出 token 价格为 60 美元,而 DeepSeek-R1 仅需 2.19 美元。这个近 30 倍的成本差异让许多人意识到 AI 价格下行的趋势。 训练基础模型并通过 API 访问获利是一项艰难的业务。许多从事这一领域的公司仍在寻找收回训练成本的路径。Sequoia 的文章《AI 的 6000 亿美元问题》(AI’s $600B Question)很好地概述了这一挑战。(不过需要明确的是,我认为基础模型公司正在做出杰出的贡献,我希望它们能够成功。)相比之下,在基础模型之上构建应用程序是一个更具吸引力的商业机会。如今,其他公司已经花费数十亿美元训练这些模型,而你只需花费几美元即可调用它们来构建客服聊天机器人、邮件摘要工具、AI 医生、法律文档助手等各种应用。 围绕“通过扩大模型规模推动 AI 进步”的叙事曾经风靡一时。坦率地讲,我曾是这一趋势的早期支持者。许多公司正是凭借这一叙事筹集了数十亿美元——即只要有足够的资金投入,他们就能 (i) 扩大规模,并 (ii) 可预测地推动性能提升。因此,业界对规模扩展的关注度极高,而对其他推动 AI 进步的方式则缺乏足够重视。 部分由于美国对 AI 芯片的出口限制,DeepSeek 团队不得不在 H800 GPU(而非更强的 H100)上进行优化,最终在计算成本(不含研究成本)低于 600 万美元的情况下成功训练出了 R1 模型。这说明,即便算力受限,通过算法优化依然可以取得重大突破。 目前仍不清楚这是否真的会减少市场对计算资源的需求。有时,某种产品的单位成本降低,反而会导致总体支出增加。我认为,从长期来看,智能与算力的需求几乎没有上限,因此我依然看好未来人类会使用越来越多的智能资源,即便其价格下降。 我在 X(推特)上看到了许多不同的解读,DeepSeek 的突破就像一场“罗夏墨迹测试”(Rorschach test),让不同的人在其中投射出自己的看法。我认为,DeepSeek-R1 具有尚未明朗的地缘政治影响,同时也为 AI 应用开发者带来了极大的机遇。我的团队已经开始头脑风暴,探索由于能够轻松访问开源推理模型而变得可能的新应用方向。对 AI 开发者而言,现在仍然是一个绝佳的时代! https://x.com/AndrewYNg/status/1885033810552905814 O penAI首席研究官Mark Chen谈DeepSeek:o1 级别的推理模型,在独立研究过程中发现了一些与OpenAI开发 o1 时相同的核心思路,期待OpenAI交付更强模型
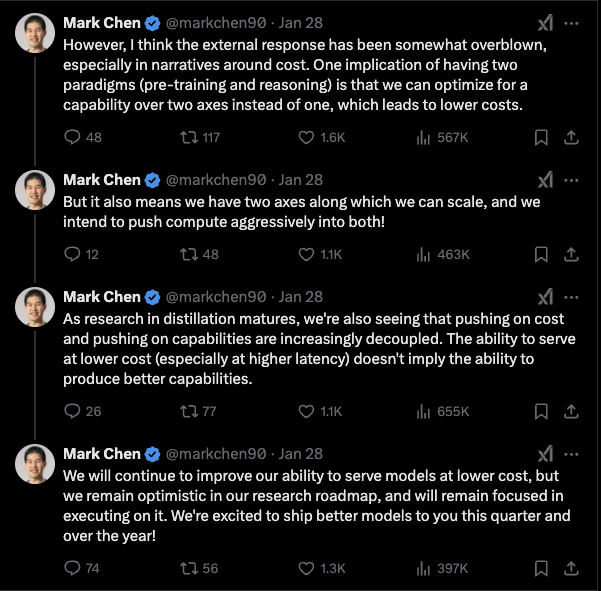
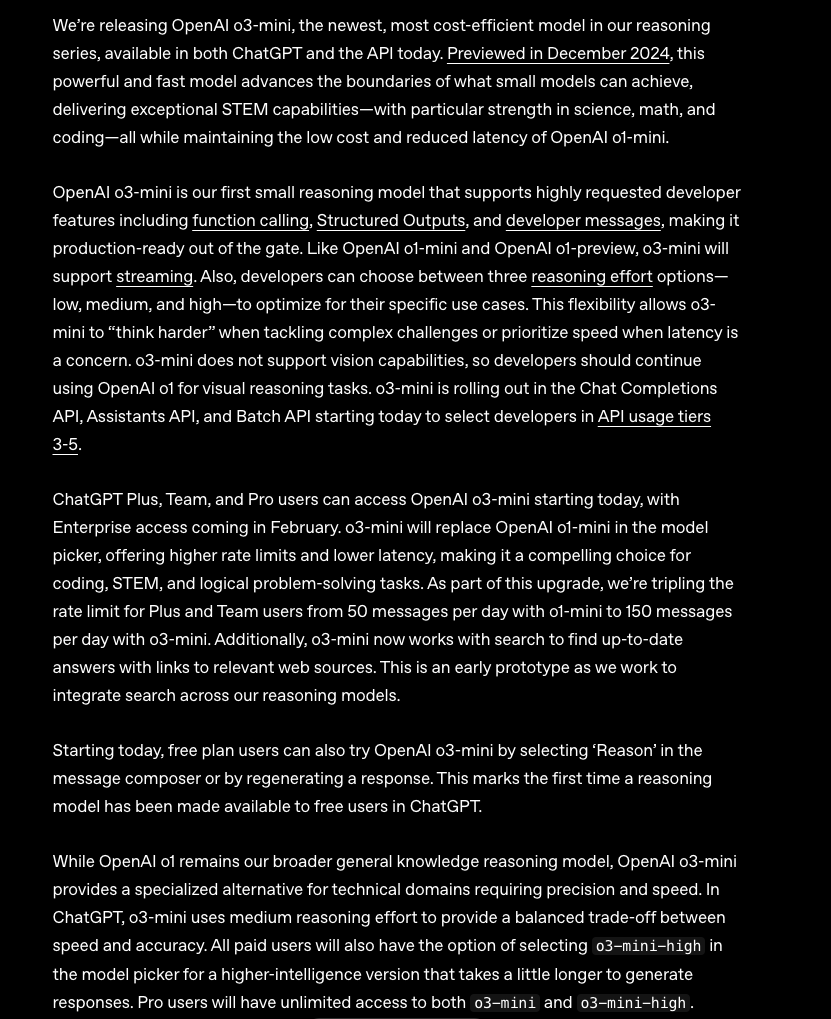
恭喜 DeepSeek 研发出了 o1 级别的推理模型!他们的研究论文表明,他们在独立研究过程中发现了一些与我们开发 o1 时相同的核心思路。 然而,我认为外界的反应有些夸张,尤其是在关于成本的讨论上。预训练(pre-training)和推理(reasoning)这两种范式的并存,意味着我们可以在两个维度上优化能力,而不是仅限于一个,从而降低成本。 https://x.com/markchen90/status/1884303237186216272 OpenAI o3-mini上线:在科学、数学、编程等 STEM 领域表现尤为出色 OpenAI o3-mini 现已在 ChatGPT 和 API 中上线。 • Plus & Team 用户 的速率限制提升至 o1-mini 的三倍。 • 免费用户 可在 ChatGPT 中点击消息输入框下的“Reason”按钮,体验 o3-mini。 我们正式发布 OpenAI o3-mini,这是我们推理系列中最新、成本最低的模型,现已在 ChatGPT 和 API 上线。 • 预览版本曾于 2024 年 12 月发布,这一强大且高效的小型模型突破了小规模模型的能力边界,在科学、数学、编程等 STEM 领域表现尤为出色,同时保持 OpenAI o1-mini 级别的低成本和低延迟。 • 这是 首款支持多个高级开发者功能的推理模型,包括: • 结构化输出(Structured Outputs) • 开发者消息(Developer Messages) 这些特性使 o3-mini 具备即开即用的生产级能力。 • 支持流式传输(Streaming),并提供三种推理强度选项(低、中、高),以优化不同用例: • 在解决复杂问题时,o3-mini 可选择“思考更深入” • 不支持视觉任务,视觉推理仍需使用 OpenAI o1。 o3-mini 今日起在 Chat Completions API、Assistants API 和 Batch API 中向API 使用等级 3-5的部分开发者开放。 https://x.com/OpenAI/status/1885406586136383634 OpenAI和美国国家实验室签署协议,利用最新推理模型加速科学研究 我们自豪地宣布,OpenAI 已与美国国家实验室(U.S. National Laboratories)签署协议,利用我们最新的推理模型加速其科学研究。 将我们的技术分享给美国顶尖科学家,符合我们构建造福全人类的通用人工智能(AGI)的使命,我们相信美国政府是实现这一目标的重要合作伙伴。 美国国家实验室汇聚了约 15,000 名科学家,涵盖多个学科领域,致力于推动人类对自然和宇宙的认知。 • 加速基础科学研究,巩固美国在全球技术领域的领导地位 • 推动美国能源产业进入新时代,充分释放自然资源潜力,革新国家能源基础设施 • 提升国家安全,在生物和网络等领域更早检测和预防自然或人为威胁 • 深化对宇宙基本法则的理解,涵盖基础数学到高能物理等多个前沿领域 我们期待这一合作推动科学突破,并助力构建更强大、更安全、更可持续的未来。 https://x.com/OpenAINewsroom/status/1885072007605150137 Sakana AI 发布小规模日语语言模型TinySwallow-1.5B 我们发布了使用全新方法「TAID」训练的小规模日语语言模型 「TinySwallow-1.5B」。 我们开发了一种新的知识蒸馏方法 「TAID (Temporally Adaptive Interpolated Distillation)」,能够高效地将大规模语言模型(LLM)的知识转移到小规模模型中。该方法根据小规模模型的学习进度,逐步引导大规模模型的知识迁移,从而实现更高效的知识蒸馏。这项研究已被 ICLR 2025 机器学习领域国际会议录取。 📄 论文: https://arxiv.org/abs/2501.16937 💻 GitHub: https://github.com/SakanaAI/TAID 在此研究基础上,我们成功地将 32B 参数的LLM的知识转移到 1.5B 参数的小规模模型中,相当于原始模型的 1/20 规模,并打造了在同类模型中表现最优的日语语言模型 「TinySwallow-1.5B」。 由于其小巧的规模,「TinySwallow-1.5B」可直接在智能手机或PC上运行,无需依赖外部API。您可以通过以下链接,在浏览器中体验该模型的 在线聊天应用: 🔹 在线体验: https://pub.sakana.ai/tinyswallow/ 💻 GitHub: https://github.com/SakanaAI/TinySwallow-ChatUI 📦 模型下载: https://huggingface.co/collections/SakanaAI/tinyswallow-676cf5e57fff9075b5ddb7ec
https://x.com/SakanaAILabs/status/1884770664353325399
00 Arxiver开源:包含 138,830 篇 arXiv 论文的多Markdown格
Mistral Small 3:针对低延迟优化的 24B 参数模型 今天,我们发布了 Mistral Small 3——一个 针对低延迟优化的 24B 参数模型,并采用 Apache 2.0 许可协议 进行开源。
Mistral Small 3 的性能可与更大规模的模型(如 Llama 3.3 70B 或 Qwen 32B)竞争,并且是 GPT-4o-mini 这类封闭专有模型的优秀开源替代方案。该模型的指令遵循版本与 Llama 3.3 70B instruct 表现相当,但在相同硬件上推理速度提升 3 倍以上。 Mistral Small 3 是一个 预训练+指令微调 的模型,专为 80% 的生成式 AI 任务 设计,重点优化 强大的语言理解和指令执行能力,同时具备极低的延迟。 我们设计 Mistral Small 3 的目标是 在适合本地部署的规模下,充分发挥性能。该模型的 层数远少于同类竞品,显著减少了每次前向传播的计算时间。 在 MMLU 任务上,Mistral Small 3 达到了 81% 以上的准确率,推理速度超过 150 tokens/s,成为当前 同类模型中最高效的选择。 我们以 Apache 2.0 许可协议 发布 预训练版和指令微调版 的模型权重,为开发者提供强大基础,加速 AI 研究和应用创新。 需要注意的是,Mistral Small 3 未使用强化学习(RL)或合成数据训练,因此在生产流程中处于比 DeepSeek R1 更早的阶段(DeepSeek R1 是优秀的开源技术,能与 Mistral Small 3 互补)。 这使得 Mistral Small 3 成为构建高级推理能力的理想基础模型。我们期待看到开源社区的采用与定制,推动 AI 生态的发展 。 https://x.com/MistralAI/status/1884967826215059681
00 Arxiver开源:包含 138,830 篇 arXiv 论文的多Markdown格
Qwen2.5 VL Cookbooks:展示 Qwen2.5-VL 应用场景的 Notebook 示例集 Qwen2.5-VL Cookbooks 发布!📖✨
🧑🍳 Qwen2.5-VL Cookbooks 是一套展示 Qwen2.5-VL 应用场景的 Notebook 示例集,涵盖本地模型和 API 使用。示例包括:
• 计算应用(Compute use)
• 空间理解(Spatial Understanding)
• 文档解析(Document Parsing)
• 移动智能体(Mobile Agent)
• OCR 文字识别
• 通用识别(Universal Recognition)
• 视频理解(Video Understanding)
🔗 示例库(Cookbooks): GitHub 链接
💬 Qwen Chat 体验: 点击进入 (选择 Qwen2.5-VL-72B-Instruct 作为模型)
⚙️ API 详情: 阿里云 Model Studio
https://x.com/Alibaba_Qwen/status/1884809286288810231
00 Arxiver开源:包含 138,830 篇 arXiv 论文的多Markdown格
OpenAI发布全新智能代理–深度研究助手Deep Research,几十分钟内生成一份全面的研究报告 今天,我们推出了全新的智能代理——深度研究助手。
只需提供一个提示,ChatGPT 将自动查找、分析并综合数百个在线来源,在几十分钟内生成一份全面的研究报告,而这通常需要人类花费数小时才能完成。
https://x.com/OpenAI/status/1886219085236850889
00 Arxiver开源:包含 138,830 篇 arXiv 论文的多Markdown格
Fridman分享采访:DeepSeek,中国和AI 这是我与 Dylan Patel 和 Nathan Lambert 进行的一场长达 5 小时的深度对话,讨论了 DeepSeek、中国、OpenAI、NVIDIA、xAI、Google、Anthropic、Meta、Microsoft、TSMC、Stargate、超大规模计算集群、强化学习(RL)、推理能力 以及许多其他 AI 领域的前沿话题。
我们确实讨论了 DeepSeek-R1 和 OpenAI o3-mini,但更重要的是,我们深入探讨了 全球 AI 革命背景下,技术、地缘政治和人类未来的发展方向。 • YouTube: https://youtube.com/watch?v=_1f-o0nqpEI • Spotify: https://open.spotify.com/show/2MAi0BvDc6GTFvKFPXnkCL • Podcast: https://lexfridman.com/podcast https://x.com/lexfridman/status/1886213960556306805
00 Arxiver开源:包含 138,830 篇 arXiv 论文的多Markdown格
Claude发布利用“宪法分类器”抵御通用越狱攻击,同时发布挑战演示邀请探索越狱漏洞 Anthropic 最新研究:利用“宪法分类器”抵御通用越狱攻击
我们发布了一篇研究论文,并提供了一个 挑战演示,邀请你尝试破解系统。 与所有 LLM 一样,Claude 也存在 越狱漏洞,即通过特殊输入绕过安全训练,使其生成可能有害的内容。我们的新技术 迈出了构建强大越狱防御的关键一步。 🔗 阅读博客文章: https://anthropic.com/research/constitutional-classifiers 宪法分类器(Constitutional Classifiers)如何工作? 我们的算法训练 LLM 分类系统,根据 预定义的“宪法”规则(涵盖有害与无害信息类别)来 屏蔽有害输入和输出。 我们邀请 越狱专家 尝试攻破该系统的原型版本,以测试其鲁棒性。 • 经过 数千小时 的红队测试,没有一位参与者能找到稳定的越狱方法,来绕过 10 个特定的有害问题集并获取详细信息。 • 在 模拟越狱实验 中,宪法分类器 显著降低了越狱成功率,同时: • 计算成本增加 24%(我们正努力优化降低开销) 宪法分类器 并非完美,我们建议结合 快速响应机制 等其他防御措施。但该方法 灵活可扩展,能够迅速调整规则以应对新型攻击。 我们已经构建了一个 基于宪法分类器的演示系统,挑战你来破解它,帮助我们进一步强化防御! https://x.com/AnthropicAI/status/1886452489681023333
00 Arxiver开源:包含 138,830 篇 arXiv 论文的多Markdown格
HuggingFace发布Open Deep Research:完全开源的智能体,在验证集上的准确率为55% 介绍 open-Deep-Research:
Huggingface 推出了一项新成果!OpenAI 的 Deep Research 确实很出色…但和往常一样,它是封闭的。所以我们和一群优秀的同事一起,给自己设定了24小时的期限来复制并开源 Deep Research! 我们开发了 open-Deep-Research,这是一个完全开源的智能体,它能够: https://x.com/AymericRoucher/status/1886846796061688028
00 Arxiver开源:包含 138,830 篇 arXiv 论文的多Markdown格
ReAG:推理增强生成(Reasoning Augmented Generation) 传统的 RAG 很糟糕,因为它承诺提供“相关片段”,但实际上返回的是“相似片段”。
介绍 ReAG——推理增强生成(Reasoning Augmented Generation)。 传统的检索增强生成(RAG)系统依赖于一个两步流程:首先,语义搜索基于表层相似性检索文档;然后,语言模型从这些文档中生成答案。尽管这种方法有效,但它往往忽略更深层次的上下文信息,并可能引入无关内容。 ReAG(推理增强生成)提供了一种更强大的替代方案——它直接将原始文档输入语言模型,使其能够评估并整合完整的上下文。这种统一的方法能够生成更准确、更细腻且更具上下文感知的回应。 https://x.com/pelaseyed/status/1886448015533089248
00 Arxiver开源:包含 138,830 篇 arXiv 论文的多Markdown格
R1-V:使用具有可验证奖励的强化学习来激励 VLM 学习通用计数能力 很高兴介绍 R1-V!
我们使用具有可验证奖励的强化学习(RL)来激励 VLM 学习通用计数能力。 仅使用 100 轮训练,2B 模型就超越了 72B,成本不到 3 美元。 https://x.com/liangchen5518/status/1886171667522842856 产品
Steev: Ultimate AI Training Assistant:终极人工智能训练助手 斯蒂夫是一款人工智能代理,可自主监控和管理模型训练,无需工程师持续监督。 FilterIn:掌控你的领英动态 FilterIn 是一款免费的轻量级 Chrome 扩展程序,通过过滤掉包含特定关键词的帖子
适用于那些厌倦了看到无穷无尽的人工智能帖子、招聘公告或其他重复内容的人
FilterIn 由 Aaron Stathi 在 Chrome 扩展程序、生产力、领英类别中推荐。由 Aaron Stathi 制作。于 2025 年 2 月 5 日推出。 https://chromewebstore.google.com/ codename goose:本地人工智能代理 https://block.github.io/goose 投融资
SoftBank拟投资5亿美元于机器人初创公司Skild AI 据彭博社和《金融时报》报道,软银正在与机器人初创公司Skild AI洽谈一项5亿美元的投资交易,该公司正在构建一个面向机器人行业的基础性AI模型,估值达到40亿美元。 Skild AI成立仅两年,去年7月在一轮融资中筹集了3亿美元,估值为15亿美元,投资方包括杰夫·贝佐斯、Lightspeed风险投资和Coatue管理公司等。 该公司的AI模型适用于多种类型的机器人,Skild AI的创始人Deepak Pathak和Abhinav Gupta去年7月向TechCrunch表示,该模型具有广泛的通用性,可以根据特定领域和使用场景进行调整和修改。 近年来,机器人与人工智能的结合受到了投资者的高度关注。特别是在过去一年中,投资者,尤其是贝佐斯,增加了对AI驱动的机器人公司的投资。 例如,Physical Intelligence是一家声称开发适用于各种机器人的“智能大脑”的初创公司,该公司于去年11月完成了一轮4亿美元的融资,融资前估值为20亿美元,贝佐斯、Lux Capital和Thrive Capital领导了这一轮融资。 此外,去年2月,Figure AI这家开发AI驱动类人机器人初创公司获得了6.75亿美元的融资,估值为26亿美元,投资方包括微软、OpenAI创业基金、英伟达、亚马逊工业创新基金和杰夫·贝佐斯(通过贝佐斯探险)。 公司官网:https://www.skild.ai/ https://techcrunch.com/2025/01/28/softbank-to-invest-500m-in-robotics-startup-skildai/ DataBank获2.5亿美元股权投资,数据中心市场持续升温 受人工智能需求驱动,数据中心市场迎来投资热潮。微软计划今年投入约800亿美元建设AI基础设施,OpenAI则计划与软银等支持者合作,在美国投资至少1000亿美元的数据中心项目。 作为高性能计算数据中心的主要提供商之一,DataBank近日宣布获得私募股权公司TJC的2.5亿美元投资,并通过二级股票发行筹集了6亿美元。DataBank CEO Raul K. Martynek表示,此轮融资证明了市场对公司战略及执行能力的信心。 https://techcrunch.com/2025/01/30/data-center-operator-databank-nets-250m-equity-investment/ Ola创始人投资2.3亿美元于印度AI初创公司Krutrim Ola创始人Bhavish Aggarwal正在通过家族办公室向印度人工智能初创公司Krutrim投资2.3亿美元。这笔投资支持Krutrim开发印度语言的大型语言模型(LLM),旨在帮助印度在人工智能领域建立竞争力。目前,Krutrim的目标是到明年筹集11.5亿美元的资金,Aggarwal计划从外部投资者筹集剩余资金。 Krutrim宣布将其AI模型开源,并计划与英伟达合作,建设印度最大的超级计算机。Krutrim刚刚发布了12亿参数的Krutrim-2模型,在处理印度语言的能力上表现优异,特别是在情感分析和代码生成任务中超越了其他竞争模型。为了支持印度本地AI生态系统的发展,Krutrim还开源了多个针对印度语言优化的专用模型,涵盖图像处理、语音翻译和文本搜索等领域。 Krutrim的技术包括使用128,000标记的上下文窗口,能够处理更长的文本和更复杂的对话。根据发布的性能指标,Krutrim-2在语法纠正和多轮对话中表现出色。Krutrim的BharatBench评估框架也填补了现有评估标准侧重于英语和中文的空白,专注于印度语言的AI模型能力。 此外,Krutrim还在1月推出了其首个大型语言模型Krutrim-1,该模型拥有70亿个参数。与英伟达的超级计算机合作预计将在3月上线,并将在全年内继续扩展。 https://techcrunch.com/2025/02/04/softbank-backed-billionaire-to-invest-230m-in-indian-ai-startup-krutrim/ 中东AI电商初创公司Qeen.ai获1000万美元种子轮融资,致力于推动自动化营销 位于迪拜的AI电商初创公司Qeen.ai宣布完成1000万美元种子轮融资,由Prosus Ventures领投,此轮融资不仅是中东地区AI行业的重要融资之一,也在MENA地区引起广泛关注。Qeen.ai专注于为电商企业提供自主AI代理,旨在通过智能营销自动化优化电商业务的内容创作、市场推广及客户互动。 Qeen.ai由曾在Google和DeepMind工作的三位创始人Morteza Ibrahimi(首席执行官)、Ahmad Khwlieh(首席技术官)和Dina Alsamhan(首席商务官)创立,三人通过在Google Ads的经验,意识到电商不仅仅依赖广告系统,更多的是提升运营效率,创造卓越的产品。基于此,他们开发了一个能够自动化运行电商业务的AI平台,帮助中小型商家在不依赖昂贵广告和深厚广告经验的情况下,提升销售和市场竞争力。 Qeen.ai的AI代理能够持续学习用户行为,并使用其专有的RL-UI技术实时优化营销策略,从而提高电商销售的转化率。据公司透露,Qeen.ai的AI工具自2024年第二季度推出以来,已为超过1500万用户提供服务,帮助商家销售增长了30%。该平台的AI代理包括动态内容创建、SEO优化等功能,能够根据不同设备和用户行为个性化调整广告内容。 在电商市场迅速增长的背景下,Qeen.ai通过自动化的AI营销工具帮助商家提高运营效率,降低对人工干预的依赖。根据Ibrahimi的说法,Qeen.ai的解决方案已经帮助多个客户提升了搜索量和谷歌排名,且无须任何人工干预。公司采用基于订阅的定价模型,按每个活跃商品SKU计费,以及根据互动量定价的AI营销代理。 此轮融资将支持Qeen.ai的扩展战略,包括平台功能扩展、团队扩展以及吸引更多客户。值得注意的是,Qeen.ai的AI营销工具目前在中东地区独具竞争力,该地区在AI驱动的营销自动化工具的市场尚未饱和。Ibrahimi表示,公司计划首先在中东地区建立稳固的市场基础,随后逐步扩展至全球市场。 Qeen.ai于2023年初获得了200万美元的前种子轮融资,并在2024年6月推出产品,至今共计融资1200万美元。公司的另一大亮点是其深厚的AI技术背景,创始人团队拥有超过十年的AI研发经验,特别是在自学习、目标驱动的AI代理领域。Qeen.ai目前在阿联酋和约旦雇佣了超过25名员工,并吸引了大量本地及国际AI人才。 此外,Wamda Capital、10X Founders Fund和Dara Holdings等投资机构也参与了此次融资,进一步加速了Qeen.ai的增长步伐。 公司官网:https://www.qeen.ai/ https://techcrunch.com/2025/02/04/google-and-deepmind-alums-raises-10m-for-qee/ 加拿大StackAdapt获2.35亿美元融资,推动AI驱动的程序化广告平台发展 位于多伦多的程序化广告初创公司StackAdapt宣布完成2.35亿美元的股权融资,此轮融资由安大略省教师退休金计划(Ontario Teachers’ Pension Plan)旗下的投资部门Teachers’ Venture Growth(TVG)领投,Intrepid Growth Partners等其他投资机构也参与其中。此次融资对StackAdapt而言意义重大,不仅金额庞大,也反映了其在AI广告领域的核心竞争力。 StackAdapt成立于2014年,最初作为一家默默发展的自筹资金公司,直到2022年获得了Summit Partners投资的3亿美元,这一轮融资帮助其进一步扩展了业务规模。根据PitchBook的数据,StackAdapt的估值在当时已突破6亿美元,但目前该公司未透露此次融资后的最新估值。 此次融资的意义不仅体现在资金规模上,还在于它体现了StackAdapt本地化的融资支持。程序化广告如今已成为数字广告的核心,占据了市场的90%以上,StackAdapt通过利用AI技术,帮助客户实现更高效的广告投放和数据分析。其客户群体涵盖政治、零售、B2B、旅游、医疗和金融等多个行业,广告类型包括原生广告、展示广告、视频广告、电视广告、音频广告等。 然而,随着AI及自动化技术的崛起,程序化广告也面临诸如广告欺诈、品牌安全和数据保护等挑战。StackAdapt通过多年的广告流量分析经验,利用AI技术应对这些问题,特别是在广告欺诈和机器人流量防范方面,展现出其独特优势。 StackAdapt的首席执行官Vitaly Pecherskiy表示,尽管2022至2023年间行业增长放缓,但如今公司看到了强烈的增长需求,客户对自动化和AI驱动的解决方案需求强劲,尤其是在成本效益方面。TVG的Rick Prostko则表示,StackAdapt凭借其卓越的团队、远见的领导力和对客户价值的专注,展现了强劲的增长势头,未来有望成为全球AI广告领域的领导者。 公司官网:https://www.stackadapt.com/ https://techcrunch.com/2025/02/04/canadas-stackadapt-snaps-up-235m-for-its-ai-based-programmatic-platform/ — END — 快速获得3Blue1Brown教学动画?Archie分享:使用 Manim 引擎和 GPT-4o 将自然语言转换为数学动画
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2025/02/37988.html