我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
学术分析报告:ResearchFlow — 奇绩F23校友的开发的深度研究产品,PC端进入RFlow的分析报告,可直接点击节点右侧的小数字展开节点,登录后可在节点上直接“询问AI”,进一步探索深度信息
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


叶添:揭秘大语言模型推理机制——超越人类的二级推理
奇绩潜空间活动报名
【奇绩潜空间】是 GenAI 时代冲得最快的一批科研学者/从业者/创业者聚集的 AI 人才社区,潜空间定期邀请大模型前沿创业者分享产品实践探索,邀请前沿科研学者分享最新技术进展。
第五季第二期潜空间邀请到的嘉宾是清华大学姚班,卡内基梅隆大学博士生,Physics of LLM 2.1作者,于 Meta 担任 Research Scientist Intern的叶添,在本次活动中叶添将在北京现场与大家面对面交流,他分享的主题是《揭秘大语言模型推理机制——超越人类的二级推理》。

信号
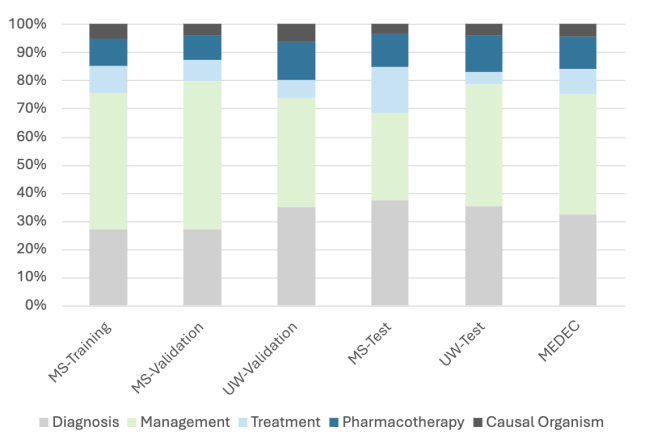
MEDEC: A Benchmark for Medical Error Detection and Correction in Clinical Notes
多项研究表明,大型语言模型 (LLM) 可以正确回答医学问题,甚至在某些医学考试中的表现优于人类的平均分数。但是,据我们所知,尚未进行任何研究来评估语言模型验证现有或生成的医学文本的正确性和一致性的能力。在本文中,我们介绍了 MEDEC(此 https URL),这是第一个公开可用的临床笔记医疗错误检测和纠正基准,涵盖五种类型的错误(诊断、管理、治疗、药物治疗和病原体)。MEDEC 包含 3,848 份临床文本,其中包括来自三个美国医院系统的 488 份临床笔记,这些笔记之前从未被任何 LLM 见过。该数据集已用于 MEDIQA-CORR 共享任务,以评估 17 个参与系统 [Ben Abacha 等人,2024 年]。在本文中,我们描述了数据创建方法,并评估了最近的 LLM(例如 o1-preview、GPT-4、Claude 3.5 Sonnet 和 Gemini 2.0 Flash)在检测和纠正需要医学知识和推理能力的医疗错误方面的任务。我们还进行了一项比较研究,其中两名医生在 MEDEC 测试集上执行了相同的任务。结果表明,MEDEC 是一个足够具有挑战性的基准,可以评估模型验证现有或生成的笔记以及纠正医疗错误的能力。我们还发现,尽管最近的 LLM 在错误检测和纠正方面表现良好,但它们在这些任务中的表现仍然不如医生。我们讨论了这一差距背后的潜在因素、从实验中获得的见解、当前评估指标的局限性,并分享了未来研究的潜在指针。
原文链接:https://arxiv.org/abs/2412.19260v1
ResearchFlow链接:https://rflow.ai/flow/b4187c99-b057-41af-aa26-557a8f58bba1
Explanatory Instructions: Towards Unified Vision Tasks Understanding and Zero-shot Generalization
尽管计算机视觉 (CV) 遵循了自然语言处理 (NLP) 中建立的许多里程碑,例如大型 Transformer 模型、广泛的预训练和自回归范式等,但它尚未完全实现自然语言处理 (NLP) 中观察到的零样本任务泛化。在本文中,我们探讨了 CV 采用离散和术语任务定义(例如“图像分割”)的想法,这可能是零样本任务泛化的主要障碍。我们的假设是,如果不真正理解以前见过的任务(由于这些术语定义),深度模型很难推广到新任务。为了验证这一点,我们引入了解释性说明,它通过从输入图像到输出的详细语言转换提供了一种直观的方式来定义 CV 任务目标。我们创建了一个包含 1200 万个“图像输入 → 解释性说明 → 输出”三元组的大型数据集,并训练了一个基于自回归的视觉语言模型(基于 AR 的 VLM),该模型将图像和解释性说明作为输入。通过学习遵循这些指令,基于 AR 的 VLM 实现了针对之前见过的任务的指令级零样本能力,并展示了针对未见过的 CV 任务的强大零样本泛化能力。
原文链接:https://arxiv.org/abs/2412.18525v2
ResearchFlow链接:https://rflow.ai/flow/9f308b55-4181-4575-bf58-3db2333805f6
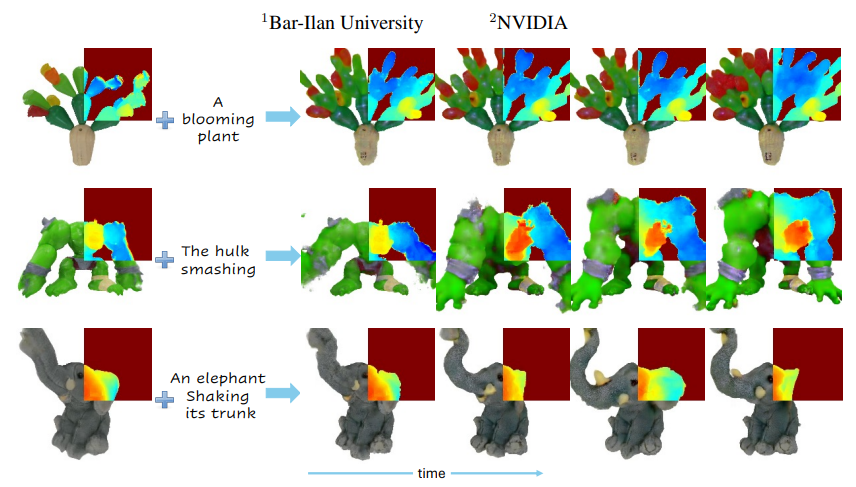
Bringing Objects to Life: 4D generation from 3D objects
生成式建模的最新进展现在使得能够创建由文本提示控制的 4D 内容(移动的 3D 对象)。4D 生成在虚拟世界、媒体和游戏等应用中具有巨大潜力,但现有方法对生成内容的外观和几何形状的控制有限。在这项工作中,我们介绍了一种通过以文本提示为指导 4D 生成来为用户提供的 3D 对象制作动画的方法,从而实现自定义动画,同时保持原始对象的身份。我们首先将 3D 网格转换为“静态”4D 神经辐射场 (NeRF),以保留输入对象的视觉属性。然后,我们使用由文本驱动的图像到视频扩散模型为对象制作动画。为了提高运动真实感,我们引入了一种增量视点选择协议,用于对视角进行采样以促进逼真的运动,并引入了蒙面分数蒸馏采样 (SDS) 损失,利用注意力图将优化重点放在相关区域。我们从时间连贯性、及时遵守和视觉保真度方面评估了我们的模型,发现我们的方法优于基于其他方法的基线,使用 LPIPS 分数衡量的身份保存性能提高了三倍,并有效地平衡了视觉质量和动态内容。
原文链接:https://arxiv.org/abs/2412.20422v1
ResearchFlow链接:https://rflow.ai/flow/80abcfde-852f-4b53-9f8f-6ef2b37ead9a
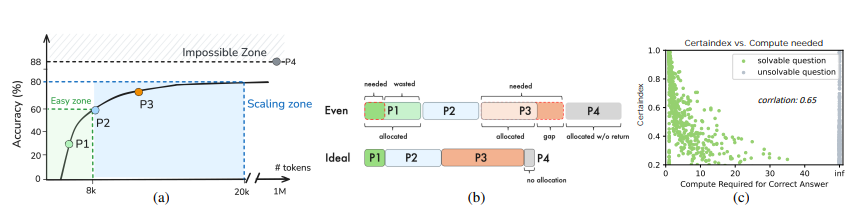
Efficiently Serving LLM Reasoning Programs with Certaindex
大型语言模型 (LLM) 的快速发展释放了它们在数学问题解决、代码生成和法律分析等高级推理任务中的能力。这一进步的核心是推理时间推理算法,它通过探索多种解决方案路径来改进输出,但代价是增加计算需求和响应延迟。现有的服务系统无法适应这些算法的扩展行为或查询的不同难度,导致资源使用效率低下和延迟目标未达到。我们提出了 Dynasor,这是一个优化 LLM 推理查询推理时间计算的系统。与传统引擎不同,Dynasor 跟踪和调度推理查询中的请求,并使用 Certaindex(一种基于模型确定性测量统计推理进度的代理)来动态指导计算分配。Dynasor 共同调整调度和推理进度:它为困难查询分配更多计算,减少简单查询的计算,并提前终止没有希望的查询,平衡准确性、延迟和成本。在不同的数据集和算法上,Dynasor 在批处理中将计算量减少了高达 50%,并在在线服务中维持了 3.3 倍的更高查询率或 4.7 倍更严格的延迟 SLO。
原文链接:https://arxiv.org/abs/2412.20993v1
ResearchFlow链接:https://rflow.ai/flow/fb9ce4b3-ad5c-4c40-b92a-ba83a6cc0620
AgiBot World
大多数现有的机器人学习基准都难以应对由低质量数据和有限传感能力造成的现实挑战,通常仅限于受控环境中的短期任务。推出 AgiBot World,这是第一个旨在推进多用途人形机器人政策的大型机器人学习数据集。它将伴随基础模型、基准和生态系统,使学术界和行业能够民主化获取高质量的机器人数据,为 Embodied AI 的“ImageNet 时刻”铺平道路。AgiBot World 拥有来自 100 个机器人的 100 多万条轨迹,涵盖五个目标领域的 100 多个现实场景,可解决细粒度操作、工具使用和多机器人协作问题。尖端的多模态硬件具有视觉触觉传感器、耐用的 6 自由度灵巧手和具有全身控制的移动双臂机器人,支持模仿学习、多智能体协作等方面的研究。 AgiBot World 致力于变革大规模机器人学习,并推进可扩展的机器人系统投入生产。这个开源平台邀请研究人员和从业者共同塑造 Embodied AI 的未来。
 https://huggingface.co/agibot-world
https://huggingface.co/agibot-world
HuggingFace&Github
AgiBot World Alpha
主要特点🔑

https://huggingface.co/datasets/agibot-world/AgiBotWorld-Alpha
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2025/01/29942.html