Transformers Can Navigate Mazes With Multi-Step Prediction
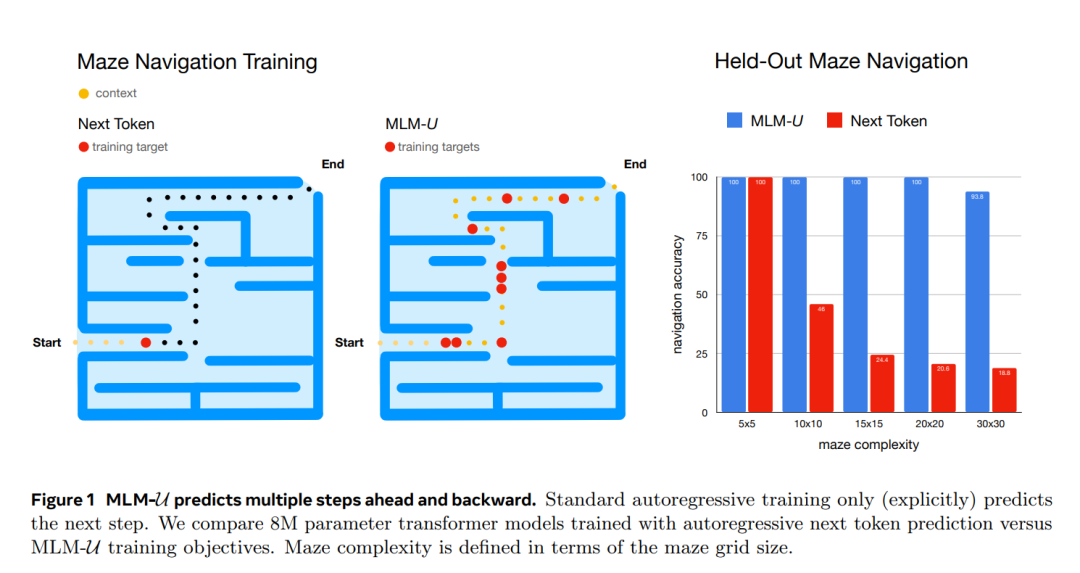
本文探讨了当前Transformer模型在处理长期规划和决策任务时的局限性,尤其是在迷宫导航等任务中的表现。传统的训练方法基于下一个令牌预测,即模型根据前一步预测下一步,然而,这种方法在需要前瞻性思维的任务中存在明显缺陷,特别是当路径复杂度增加时,模型可能会选择捷径而不是规划多个步骤。这篇论文提出了一个创新的学习目标,MLM-U(Masked Language Model with Unidirectional prediction),并检验其在迷宫导航任务中的效果。与传统的下一个令牌预测方法不同,MLM-U通过掩蔽输入序列的子集,明确地预测多个步骤的前后轨迹。这种方法的核心在于,通过学习预测未来和回溯多个步骤,模型能够更好地进行长时间的规划,避免只依赖最近的输入来做出决策。为了验证这一点,作者训练了多个Transformer模型,并使用了具有不同复杂度的迷宫环境进行测试。实验结果显示,相比于传统的下一个令牌训练,MLM-U显著提高了迷宫导航的准确性和训练效率。例如,在20×20的迷宫中,MLM-U训练的8M参数模型能够完美解决所有迷宫,而使用标准下一个令牌预测训练的模型在相同迷宫上的表现仅为20.6%的导航准确率。此外,MLM-U在复杂迷宫(如30×30)的表现也超过了更大参数量(175M)的模型,这些模型即使加入了A*搜索轨迹的额外监督,也只能达到70.2%的导航准确率。进一步的分析显示,MLM-U在数据效率和训练效率上也表现优异。在简单的迷宫(如5×5)上,MLM-U在训练样本使用上比标准下一个令牌训练效率高4倍,且在GPU小时数上也节省了2倍的时间。更重要的是,随着模型规模的增加,MLM-U的表现有明显提升。例如,将MLM-U从3M参数扩展到8M参数时,20×20迷宫的导航准确率从85%提高到100%。https://arxiv.org/abs/2412.0511703
“The Well”是一个大规模的机器学习数据集集合,包含15TB的数值模拟数据,涵盖了生物系统、流体动力学、声学散射、外星流体的磁流体动力学模拟以及超新星爆炸等多个领域。这些数据集可以单独使用,也可以作为一个整体基准套件,帮助加速机器学习和计算科学研究。其数据来源于领域专家和数值软件开发人员,旨在为训练深度学习模型提供丰富的数据支持。该数据集的使用通过the_well库实现,用户可以通过简单的API接口访问和加载数据。使用时,首先需要安装the_well包并下载数据。数据下载支持从PyPI直接安装,也可以从源代码进行安装,适配不同的硬件加速环境(如CUDA版本)。安装完成后,用户可以选择下载单个数据集或整个数据集集合。the_well支持直接从Hugging Face进行数据流式下载,但为了提升大规模训练性能,推荐将数据下载到本地。此外,”The Well”还包括基准测试功能,用户可以使用不同的数据集来训练和评估代理模型。该项目提供了多种基准模型的实现,并依赖于hydra配置管理系统来处理训练、模型、优化器等不同组件的配置。例如,用户可以通过运行简单的命令来训练基于FNO架构的模型,进行不同数据集的训练。值得一提的是,”The Well”的数据集非常庞大,单个数据集的大小从6.9GB到5.1TB不等,整个数据集的总量达到15TB。因此,使用这些数据集进行训练时需要确保足够的存储空间和计算资源。为了方便用户使用,提供了便捷的下载工具和示例代码。该项目由Polymathic AI组织主导,并与多个研究机构合作,包括Flatiron Institute、哥伦比亚大学、剑桥大学等。相关文献已在2024年神经信息处理系统大会(NeurIPS)上发表,若研究人员在研究中使用该项目,可以引用该文献。https://polymathic-ai.org/the_well/ 推荐阅读 — END —1. The theory of LLMs|朱泽园ICML演讲整理