
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!



资讯
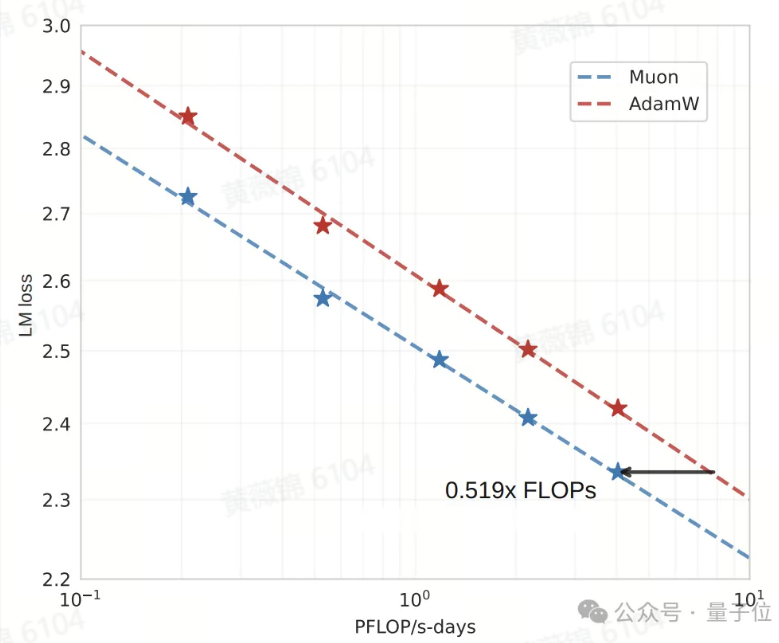
月之暗面开源改进版Muon优化器,算力需求比AdamW锐减48%,DeepSeek也适用
月之暗面团队对OpenAI技术人员提出的Muon优化器进行了改进,使其算力需求相比AdamW锐减48%,并证明了其适用于大规模模型和分布式训练环境。Muon是一种神经网络隐藏层的2D参数优化器,核心思想是通过正交化梯度更新矩阵,避免参数更新陷入局部极小,使模型能够学习到更加多样化的特征表示。此前,Muon主要适用于较小的模型和数据集,存在能否用于更大规模训练、更大规模GPU集群以及微调和强化学习的疑问。月之暗面团队通过实验给出了肯定回答。
团队在改进Muon时,引入了AdamW的权重衰减机制,解决了大规模训练中模型权重和层输出幅度持续增长的问题。同时,调整了Muon的参数更新尺度,使不同形状矩阵参数的更新幅度保持一致,并与AdamW的更新幅度匹配。此外,为将Muon扩展到分布式训练环境,团队提出了分布式Muon的并行化策略,在ZeRO-1的基础上引入梯度聚合通信和并行计算正交化更新量的操作,最小化内存占用和通信开销。
在Llama架构的稠密模型上,改进后的Muon在计算预算最优的情况下,样本效率是AdamW的1.92倍,训练FLOPS只需AdamW的52%。基于DeepSeek-V3-Small架构,团队用改进的Muon训练了Moonlight模型,这是一个具有15.29B总参数和2.24B激活参数的MoE模型。与相同规模和数据量的模型相比,Moonlight在多项任务上展现了更好的性能,推进了性能-训练预算平面上的帕累托前沿。此外,团队还探索了Muon在微调阶段的效果,发现预训练和微调阶段均使用Muon效果最佳。
https://mp.weixin.qq.com/s/E65ULmjlK7Lv81dqvAubcQ
2025全球开发者先锋大会Day1亮点回顾
2025年2月21日,全球开发者先锋大会在上海拉开帷幕,首日活动精彩纷呈,汇聚了众多行业专家与开发者,聚焦人工智能前沿技术与应用。在西岸艺术中心B馆举办的大师讲坛中,上海交通大学特聘教授俞勇、浙江工业大学教授王万良等多位重量级嘉宾分享了关于人工智能人才培养、前沿技术与“人工智能+”通识教育模式创新等观点,为AI教育发展提供了新思路。
上海漕河泾会议中心科创厅B的“AI赋能生物经济创新发展讲坛”则聚焦AI与生物经济的深度融合,探讨了合成生物学、智能育种、基因检测等前沿领域,展示了AI在生物制造、精准医疗和农业现代化等方面的变革潜力。中国农业银行主办的“AI+金融创新”讲坛,汇聚了蚂蚁数科、中科曙光等行业领军企业,围绕大模型技术驱动下的金融变革展开讨论,强调了技术底座革新、场景深度实践和生态安全共建,为金融智能化转型提供了指引。
开发者社区如Center for Safe AGI、魔搭、Google等也在大会中亮相,分享了开源大语言模型、多智能体应用等技术热点与实践心得。阿里魔搭社区展示了零基础应用开发和大模型多模态能力构建,吸引了众多开发者和观众。此外,大会还推出了“AI的魔力·爱情孵化器”交友平台,通过智能算法实现开发者之间的精准匹配,展现了科技与人文的融合。
场馆内的机器人互动也成为一大亮点,展示了机器人在生活中的多种应用,让参与者感受到科技进步带来的便利与乐趣。整体而言,首日活动不仅展示了AI技术的最新进展,还促进了学术界、产业界和开发者之间的交流与合作,为全球开发者生态的建设注入了新动力。

https://mp.weixin.qq.com/s/m0a_ZH4_Bmw-A-qDKT_opA
波士顿动力机器狗Spot速度突破:强化学习助力,电池成关键瓶颈
波士顿动力的机器狗Spot在速度上取得了重大突破,其跑步速度从出厂时的1.6米/秒提升至18.7千米/时,接近小型犬的平均奔跑速度。这一进步并非来自马达性能的提升,而是通过强化学习优化了机器狗的运动控制。RAI研究所与波士顿动力合作,利用强化学习对Spot的电机和动力装置建模,发现限制Spot速度的真正瓶颈是电池供电能力。研究人员通过在模拟环境中并行训练多台Spot机器人,为其提供了“自主发现的空间”,让机器人自己找到最高效的快速移动方式。Spot提速的关键在于在小跑步态基础上增加了四脚同时离地的“飞行”阶段,使机器人能够快速向前移动脚步维持速度。
强化学习为机器人控制带来了新的范式。与传统的模型预测控制(MPC)方法相比,强化学习让机器人在“虚拟道场”中不断练习,找到最优的动作方案,从而最大化性能并提高可靠性。RAI研究所还利用类似的强化学习流程训练了一款名为UMV的自行车机器人,使其学会了跑酷动作,甚至在没有平衡陀螺仪的情况下依靠AI保持平衡。然而,UMV在完成一些看似简单的动作,如倒车时,仍面临挑战。RAI研究所正在努力让UMV走出实验室,在复杂地形上进行真正的自行车跑酷表演。该研究所强调,重点在于通过强化学习等基于学习的方法,突破机器人控制的边界,挖掘硬件系统的隐藏潜力。

https://mp.weixin.qq.com/s/9hwaajMeB5XeXrlcLjZFmg
YOLOv12:首个以Attention为核心的实时目标检测框架
YOLOv12是首个将注意力机制(Attention)作为核心模块的YOLO系列目标检测模型,由纽约州立大学布法罗分校的田运杰、David Doermann和中国科学院大学的叶齐祥合作完成。该模型突破了以往YOLO系列主要依赖CNN架构的限制,通过创新性设计解决了注意力机制在实时性要求下的低效问题,显著提升了性能。
YOLOv12的核心创新之一是提出了一种区域注意力模块(Area Attention,A2),通过将特征图划分为纵向或横向区域,以简单直接的方式降低了传统注意力机制的计算复杂度,同时保持了大感受野。实验表明,A2在几乎不影响性能的前提下,大幅提升了计算速度,满足了实时推理的需求。
此外,YOLOv12引入了残差高效层聚合网络(R-ELAN),以优化特征聚合效率并解决大规模模型的优化不稳定性问题。R-ELAN通过在block内引入残差连接和缩放因子,稳定了训练过程中的梯度流动,并重新设计了特征聚合方式,进一步提升了优化稳定性和计算效率。
为了更好地适配实时目标检测任务,YOLOv12还对基础注意力机制进行了多项优化,包括调整MLP比例、移除位置编码、引入可分离卷积等。这些改进使得模型在保持高性能的同时,显著降低了计算开销。
在实验中,YOLOv12在COCO数据集上取得了优异的性能。例如,YOLOv12-N在计算量和参数规模相近的情况下,比YOLOv6-N、YOLOv8-N等提升了3.6%的mAP,推理速度达到1.64ms/图像;YOLOv12-S在21.4GFLOPs和9.3M参数下,实现了48.0%mAP,优于YOLOv8-S等模型。此外,YOLOv12在CPU推理速度和参数量平衡方面也展现出显著优势。
可视化分析表明,YOLOv12能够生成更清晰的目标轮廓和更精确的前景激活,这主要归功于区域注意力机制带来的更大感受野和更强的全局上下文感知能力。YOLOv12的推出为实时目标检测任务提供了新的高效解决方案,也为未来YOLO系列的发展提供了新的方向。

https://mp.weixin.qq.com/s/DGVybcJMnrWyW1ceOcIaaQ
端侧AI产业链投资前景
中信建投证券发布报告指出,端侧AI产业链投资前景广阔。2024年,北美云厂商资本开支高速增长,全年达2504亿美元,同比增长62%。云厂商持续投入AI基础设施建设,推动算力需求增长。DeepSeek发布的R1模型大幅降低训练和推理成本,其端侧应用场景受到关注。国内物联网模组厂商在端侧AI领域具备先发优势,积极布局产业。三大运营商上线DeepSeek,提供算力服务,有望拉动算力基础设施需求。
报告重点推荐端侧AI产业,DeepSeek模型通过小参数量模型蒸馏提升性能,推动端侧AI发展。端侧硬件设备成为大模型能力落地的关键环节,OpenAI计划开发生成式AI专用终端。端侧AI的潜在爆品智能眼镜市场迎来爆发元年,多家厂商布局,预计2025年市场将快速增长。
报告还强调,端侧AI的发展将推动硬件升级,包括算力、存储、连接和电力等环节。AI手机、AI PC等终端设备迎来创新周期,新一代AI手机支持端侧运行大模型,AI PC硬件算力与系统级AI功能逐步完善。AI PC出货量有望快速提升,微软和苹果在系统级AI应用上持续发力。此外,“AI+硬件”模式在办公、娱乐、教育等领域广泛应用,AI眼镜、耳机、音箱等产品迎来发展机遇。
报告提示风险,包括国际环境变化、人工智能发展不及预期、市场竞争加剧、汇率波动、数字中国建设不及预期等。
https://mp.weixin.qq.com/s/fQMtZQK-gFopeiK4xrZmSQ
推特
1x发布NEO Gamma
介绍 NEO Gamma。
离家更近一步。

https://x.com/1x_tech/status/1893012909082714299
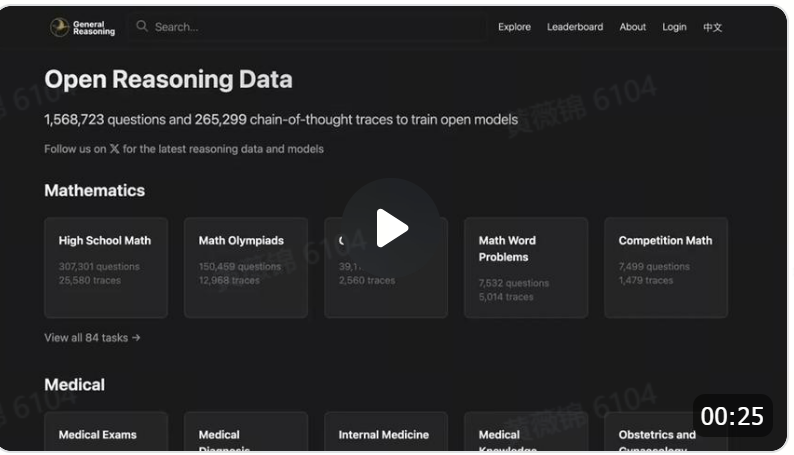
General Reasoning:一个用于构建大型推理模型的全新开源资源
🎉 介绍 General Reasoning!
一个用于构建大型推理模型的全新开源资源。
我们已索引超过 150 万个问题、27 万条思维链追踪,并创建了数百个基准测试来跟踪进展。
欢迎贡献问题、验证、基准测试等内容 🧵
https://x.com/GenReasoning/status/1892983129528222111
Gavin Baker:独特数据最终可能成为区分模型、实现预训练投资回报的唯一基础
OpenAI 在 2022 年夏季至 2024 年春季期间一直保持显著领先,直到 Google 和 Anthropic 赶上了 GPT-4。这七个季度的主导地位主要得益于 OpenAI 最早积极押注于传统的预训练“缩放定律”。
然而,在推理能力上率先推出 o1 仅带来了几个月的优势。
目前,DeepSeek、Google 和 xAI 与 OpenAI 大致处于同一水平,甚至可以说 xAI 处于领先地位。Google 和 xAI 很可能会很快全面超越 o3,因为它们的基础模型更强。因此,GPT-5 作为潜在的 “o5” 推理模型的基础已经变得迫在眉睫。
Sam Altman指出,OpenAI 未来的领先优势会缩小,而 Satya(Nadella)基本上承认,OpenAI 在模型能力上的绝对领先时期即将结束。
在我看来,这正是 Satya 选择不为 OpenAI 提供 1600 亿美元预训练资金的原因(消息来源:@theinformation)。相反,他的策略是通过向 OpenAI 提供推理服务来赚钱。
Google 和 xAI 都拥有独特且有价值的数据来源,这将使它们与 DeepSeek、OpenAI 和 Anthropic 形成日益明显的差异化。如果 Meta 能在模型能力方面迎头赶上,它也会加入这一行列。
我多次引用 Eric Vishria 的观点,并强调如果没有访问独特且有价值的数据,前沿模型将成为历史上贬值最快的资产,而蒸馏(distillation)只会加剧这种情况。
Satya 似乎也持相同观点,因此选择退出 1600 亿美元的预训练投资,并且传闻微软正在取消数据中心建设。他最近在播客中提到,未来可能会出现数据中心的过度建设,因此租赁比购买更划算。从经济角度来看,这可能是微软的一个明智决策,甚至未来微软可能会使用开源模型来驱动 CoPilot。
如果未来的前沿模型无法访问类似 YouTube、X(前 Twitter)、TeslaVision、Instagram 和 Facebook 这样的独特数据,那么可能根本不会有投资回报(ROI)。从这个角度来看,扎克伯格(Zuckerberg)的战略也显得更加合理。独特数据最终可能成为区分模型、实现预训练投资回报的唯一基础。
如果这一判断正确,未来可能只有 2-3 家公司会进行前沿模型的预训练,而用于预训练的超大规模数据中心也只需要几座。其余 AI 计算资源将主要由小型数据中心承担,并针对低延迟或成本优化的推理进行地理空间优化。成本优化的推理意味着可以使用更便宜、质量较低的电力(例如不需要为核能支付溢价),对短期内的液冷需求也会降低。这与 6-10 家公司都在预训练前沿模型的世界截然不同。
需要注意的是,推理模型的计算需求极其庞大。在推理阶段,计算力实际上就是智能。因此,在这种情况下,所需的计算量甚至可能比 2023-2024 年市场普遍假设的“预训练主导”计算场景还要多。不过,这种计算形态会发生很大变化:过去预训练和推理计算的比例是 50/50,而未来可能变成 5/95。将会有大量“本田”(低成本推理计算),而“法拉利”(高成本训练计算)会变得极少。基础设施的卓越性将变得至关重要。
以上分析还未考虑端侧推理(on-device inference)和全量化(full quantization)的影响——DeepSeek R1 论文并不是过去一年中中国实验室发表的最重要的论文。如果你懂,你就懂。
超级智能(ASI)的经济回报本质上是无法预测的。我希望它的回报是高的,但一个 IQ 140 的模型,在设备端运行,并能访问独特的世界数据,可能已经足够满足大多数应用场景。例如,预订旅行根本不需要 ASI。
我已经尽力做到客观,但在涉及 xAI 和 OpenAI 时,我确实有个人和经济上的偏见。如果 OpenAI 仍然是五年后的领导者,那可能主要归因于先发优势、ChatGPT 成为“动词”(即广泛应用)以及规模在推理模型中的更大优势——用户会生成并验证推理链。
如往常一样,时间会给出答案。
https://x.com/GavinSBaker/status/1893348988386189774
DeepTutor:专为学习打造的深度研究工具
互联网现在成为你的私人导师。
我们在 Opennote 上推出了 DeepTutor——全球首个(也是最快的)专为学习打造的深度研究工具。
现已在 http://opennote.me 向所有用户开放。
https://x.com/abh1a0/status/1893035220317663415
Veo 2发布:最先进的 AI 视频模型
Veo 2来了,全球首发于 Freepik!
Google 与我们合作,推出最先进的 AI 视频模型。
无与伦比的真实感、精确度和流畅动画。
快来体验!前 10,000 名用户可获得 2 次免费生成机会。

https://x.com/freepik/status/1892842061310939361
产品
Smallest.ai:实时生成任何口音、语言或情感的人工智能语音
Smallest.ai 提供具备超个性化、低延迟且可扩展模型的实时人工智能技术,以高效且经济的方式革新人工智能与人类的交互。
主要功能:
-
实时生成 AI 语音:可实时生成各种口音、语言、情感的 AI 语音。
-
超个性化交互:借助实时 AI 实现高度个性化的人机交互体验。
-
低延迟:运行过程中延迟较低,能保证交互的流畅性。
-
模型可扩展:其模型具备可扩展性,能适应不同规模的需求。

https://smallest.ai/
投融资
灵境AI完成种子轮融资,加速AIGC技术与文创IP出海布局
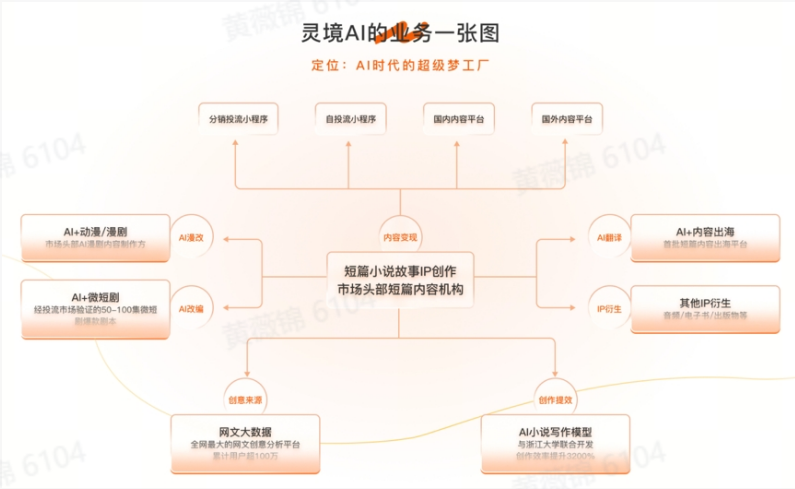
2025年2月19日,灵境万维(杭州)智能科技有限公司(灵境AI)宣布完成数百万元种子轮融资。本轮融资将用于AIGC技术研发、团队扩建、内容出海及构建AIGC内容生产与IP孵化生态,巩固其在小说、动漫、微短剧等垂直领域的智能化生产优势。
随着生成式AI技术的发展,文创产业正从“人力密集型”向“智能工业化”转型。灵境AI以“创意洞察+AI提效”为核心,构建了覆盖内容生产、分发、变现及IP孵化的完整生态。公司成立于2023年8月,核心团队来自头部互联网和内容公司,凭借“创意故事+AI工业化生产+爆款IP运营”模式,迅速取得商业化成果。
灵境AI的核心业务包括:1)网文大数据平台,实时监测超1000万部小说,为内容生产者提供选题挖掘、创意灵感激发等服务;2)AI短篇小说工厂,与浙江大学联合开发AI写作模型,月均产出1000+篇小说,效率是传统生产的20倍;3)AI动漫创作引擎,将文字内容改编为动漫,制作效率提升12倍,成本降低70%;4)内容出海计划,推动IP内容向东南亚、欧美市场延伸,首批作品已在海外平台实现付费变现。
成立仅半年,灵境AI已实现近百万营收,2024年收入同比增长540%,预计2025年突破6000万元。公司还获得杭州市余杭区750万元重点项目补助。创始人表示,灵境AI将通过AI重构内容生产链条,打造“AI时代的超级梦工厂”,并计划下半年开放创作平台,赋能创作者,构建“AI时代的造梦新基建”。
投资方看好AIGC在文创领域的应用前景及灵境AI的创新能力和商业落地能力。公司计划于2025年Q2启动天使轮融资,Q4启动Pre-A轮融资,持续推动技术研发、IP生态建设及全球化布局。
公司官网:https://h5.lingjingai.cn/
https://36kr.com/p/3173376885523336
人工智能招聘初创公司Alfa获得62.5万美元种子轮融资,估值达600万美元
人工智能招聘初创公司Alfa已获得超过62.5万美元的融资,估值达到600万美元。本轮融资由 Fuel Ventures 领投,Davie Rowe(Sixty Six & Black Green)、Pierre Decote(Revolut & Golden Square)、Chris Adelsbach(Outrun Ventures)和其他多个天使投资人参与了本轮融资。
Alfa 正在打造世界上第一个真正智能的人工智能招聘器。Alfa 的代理可以自动即时查找、筛选并将雇主与最优秀的 1% 候选人联系起来。
Alfa不是一个替代者,而是一个副驾驶员,旨在自动处理招聘中的所有行政工作,这样招聘经理就可以花更多时间与候选人讨论真正重要的事情。
与某些人类不同,Alfa没有性别或种族偏见。通过支持代表性不足的少数群体,这极大地改善了DE&I。
公司官网:https://welovealfa.com/
— END —
2. 「理论与实践」AIPM 张涛:关于Diffusion你应该了解的一切
3. 「奇绩潜空间」吕骋访谈笔记 | AI 硬件的深度思考与对话
快速获得3Blue1Brown教学动画?Archie分享:使用 Manim 引擎和 GPT-4o 将自然语言转换为数学动画
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2025/02/43057.html