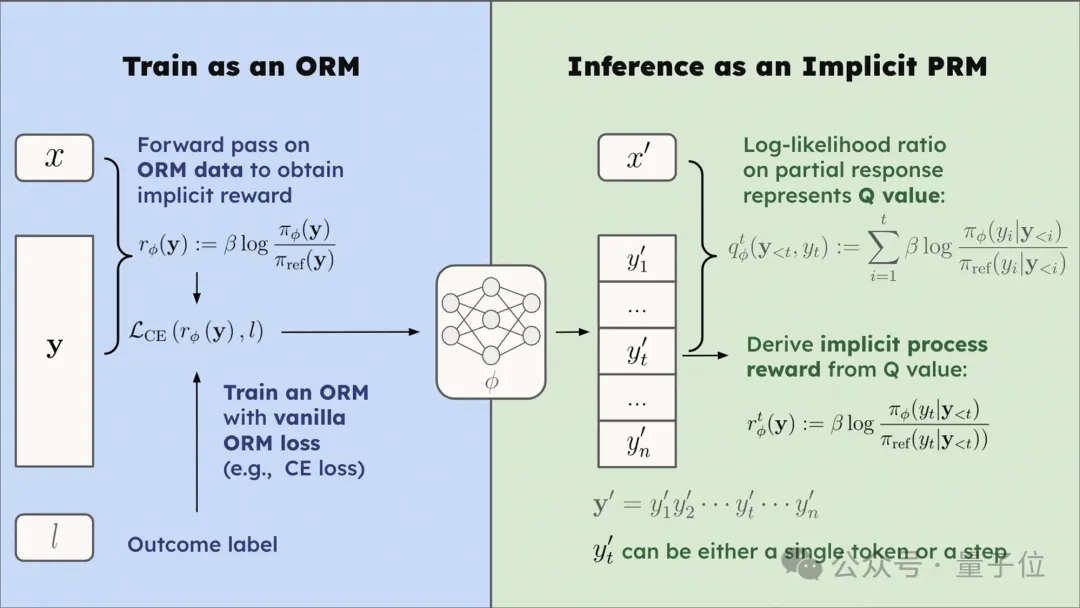
近日,清华大学NLP实验室与多家机构合作,提出了一种新型强化学习方法——PRIME(Process Reinforcement through IMplicit REwards)。该方法通过隐式过程奖励(implicit process reward),解决了大模型强化学习中的两个关键挑战:如何获得密集且可扩展的奖励,以及如何设计有效的强化学习算法。研究人员利用这一方法,成功训练出一个数学能力超过GPT-4o、Llama-3.1-70B的7B模型——Eurus-2-7B-PRIME,仅用了8张A100显卡和不到10天的时间,成本仅为一万块左右。该模型在美国IMO选拔考试AIME 2024中的准确率达到26.7%,大幅超越了现有的多种开源模型,强化学习方法带来了16.7%的绝对提升,超越了已知的任何开源方案。PRIME方法的核心在于其隐式过程奖励模型。传统的强化学习往往依赖明确的奖励模型,而PRIME则能够在不额外训练奖励模型的情况下,通过对结果标签(如最终答案的正确与否)进行训练,自动建模过程奖励。这一创新使得PRIME方法具备了高效性、可扩展性和简洁性三大优势。首先,隐式过程奖励能够为每个token提供价值估计,不需要额外训练价值模型;其次,隐式过程奖励模型可以只依赖结果标签进行在线更新,从而解决了大模型在强化学习中面临的分布偏移与可扩展性问题;最后,这种模型本质上就是一种语言模型,实践中可直接用初始策略模型进行初始化,大大简化了强化学习过程。在实验中,PRIME算法相比于传统的结果监督方法,展现了2.5倍的采样效率提升,并且在下游任务中也取得了显著的性能提升。此外,PRIME方法还证明了在线更新过程奖励模型(PRM)的重要性,与固定不更新的PRM相比,在线更新的效果更佳。PRIME的发布引发了海外AI社区的广泛关注,短短几天内,GitHub上的star数已接近300。研究团队预计,基于PRIME方法和更强基座模型的结合,未来有望训练出接近OpenAI o1模型的强大推理能力。这项创新性的强化学习算法不仅解决了大模型强化学习的奖励稀疏问题,还为模型的高阶推理能力提供了新的突破,有望在大模型训练和复杂推理领域带来更大的发展。https://mp.weixin.qq.com/s/uQxHkPeLQkiZ0y8NEF5bmg 02
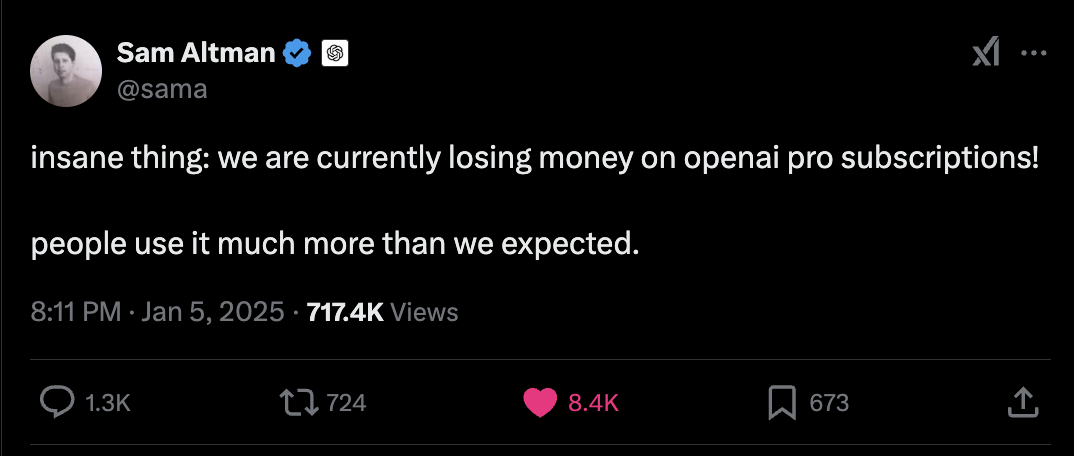
OpenAI 正开始将注意力转向“超级智能”。在个人博客的一篇文章中,OpenAI 的 CEO Sam Altman 表示,他相信 OpenAI “知道如何构建(人工通用智能,AGI)”,这是根据传统理解的定义——并且现在正在将目标转向“超级智能”。“我们热爱当前的产品,但我们是为了辉煌的未来而存在的,”Altman 在周日晚间发表的文章中写道。“超级智能工具可以大幅加速科学发现和创新,远远超越我们单凭自己所能实现的能力,从而极大地增加社会的繁荣与富足。”Altman 此前曾表示,超级智能可能在“几千天”内到来,而且它的到来会比人们想象的“更加震撼”。• @lmstudiohttps://x.com/TechCrunch/status/1876092107326165309
产品
01
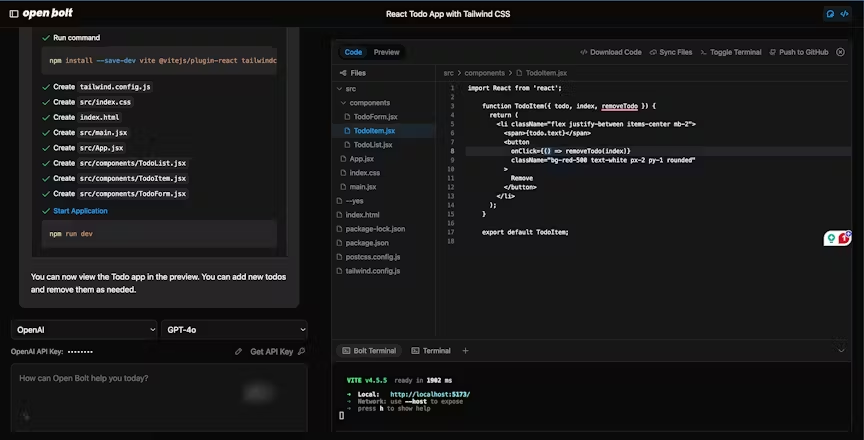
OpenBolt Web全栈应用开发工具
使用 OpenBolt,用户可以轻松完成从构思到上线的全栈 Web 应用开发。通过其强大的 AI 驱动功能,OpenBolt 可自动生成项目结构,并根据需求进行高度定制,显著减少开发时间。平台支持快速提示、运行和编辑代码,同时提供一键部署的便捷工具,使开发者能够专注于创意实现,而无需担忧繁琐的基础设施配置。无论是初学者还是资深开发者,OpenBolt 都是打造高效、现代化 Web 应用的理想解决方案。https://www.openbolt.dev/?ref=producthunt02
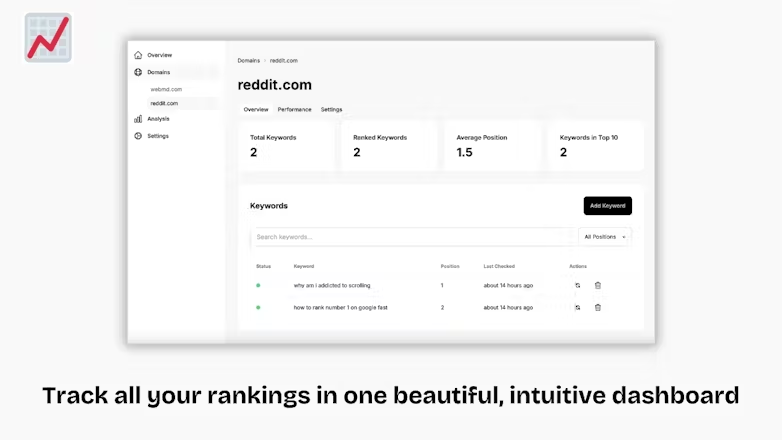
That’s Rank! 谷歌SEO关键词追踪工具
轻松追踪您的网站在 Google 搜索中的排名表现。提供每日更新、历史数据以及可操作的 SEO 洞察,帮助用户全面优化网站表现。这一切都通过一个美观且操作简便的界面呈现,让数据分析变得更直观。测试版现已免费开放,助力更多用户抢占搜索引擎优化先机!https://www.thatisrank.com