
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即
可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!



HuggingFace&Github
Deep Research最新框架验证
Hugging Face试图复制OpenAI的深度研究(Deep Research)。深度研究是一种智能网络搜索框架,在GAIA基准测试中显著提升了性能。Hugging Face为此进行了一场长达24小时的实验,目标是开源一个类似系统 。
1. GAIA基准性能突破:在GAIA基准测试中,该框架通过动态适配搜索策略与模型规模,实现了推理效率与准确率的双重提升。
2. 低成本实验验证:Hugging Face团队通过24小时密集实验验证了框架可行性,总训练成本较传统方法降低约18倍。
3. 开源集成方案:项目计划开源完整的搜索-推理协同系统,支持与现有Hugging Face模型库(如BERT、Llama等)无缝集成。
https://huggingface.co/blog/open-deep-research
信号
The AI CUDA Engineer: Agentic CUDA Kernel Discovery, Optimization and Composition
Sakana AI 的新系统 AI CUDA Engineer 可自动创建用于机器学习操作的高效 CUDA 内核。它将 PyTorch 代码转换为专用的 GPU 内核,然后通过进化策略对其进行改进,以实现显著的加速。
在这里,AI 会自动生成专用的 CUDA 内核,与标准 PyTorch 操作相比,速度显著提高(高达 10-100 倍)。这很重要,因为它将困难的低级 GPU 优化转移到代理系统,使 AI 训练和推理更加高效。
本文分享了新系统四阶段代理流程:
-
第 1 阶段将 PyTorch nn.Module 转换为功能性 PyTorch 实现。使用语言模型将代码重写为纯函数式风格。
-
第 2 阶段使用另一个 LLM 组件将功能性 PyTorch 代码转换为有效的 CUDA 内核。编译并测试生成的内核以验证正确的数值行为。与原始 PyTorch 代码相比,即使是这种初始转换也可以带来速度优势。
-
第 3 阶段应用进化优化来提高内核的性能。它使用受进化算法中的交叉启发的策略,包括结合最强内核以产生新变体的高级提示技术。过滤机制仅提升性能优于现有解决方案的内核。
-
第 4 阶段将高性能内核存储在创新档案中。这些内核可作为后续任务的垫脚石。代理在处理新的内核时会从档案中检索类似的内核,通过结合先前解决方案中的想法来进一步提高性能。
但该方法有时会使用非预期的捷径来提高效率,需要人工监督进一步保证技术的可靠性。

原文链接:https://pub.sakana.ai/static/paper.pdf
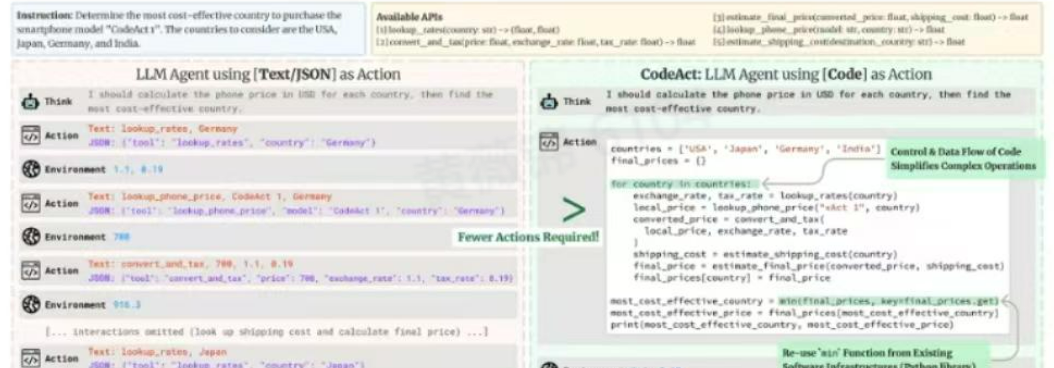
Query-Aware Learnable Graph Pooling Tokens as Prompt for Large Language Models
本文提出了可学习图池化标记 (LGPT) 和早期查询融合两种优化大语言模型(LLM)处理图信息能力的方法
-
可学习图池化标记 (LGPT) 指使用一组可学习标记来表示 LLM 的图信息。LGPT 将这些可学习的标记连接到图中的所有节点。通过图神经网络 (GNN) 传递的消息将图信息聚合到这些标记中。该方法旨在平衡详细的节点信息和全局图形上下文,避免单矢量图表示中出现的信息丢失。
-
早期查询融合旨在将问题上下文纳入图表示过程。该技术在对图进行编码之前集成了查询信息。使用文本编码器创建虚拟查询节点并将其连接到所有图节点。然后,GNN 处理包含此查询节点的图,从而创建查询感知图嵌入。
由于图的尺寸不断增加,将图进行节点级投影到大语言模型中是不可扩展的。将图形级别投影到 LLM 的单个向量会导致信息丢失。
LGPT 提供了一种平衡的方法,与单向量方法相比,它减少了信息丢失,并且与节点级投影相比,它提高了可扩展性。早期查询融合可以更好地实现图形嵌入。将 LGPT 与早期查询融合相结合可进一步提高性能。
原文链接:https://arxiv.org/pdf/2501.17549
Symmetrical Visual Contrastive Optimization: Aligning Vision-Language Models with Minimal Contrastive Images
本文提出了一种名为 S-VCO(Symmetrical Visual Contrastive Optimization) 的新型微调目标,旨在通过强化视觉细节的捕捉和与文本标记的对齐,提升大型视觉语言模型(VLMs)在视觉基础任务中的表现。
S-VCO 通过以下两个关键行为优化模型:
-
关注匹配图像:模型在预测对应响应时,优先关注匹配图像中的视觉细节。
-
拒绝矛盾图像:当呈现包含与响应矛盾的视觉细节的图像时,模型必须显著降低预测该响应的可能性。
研究还构建了一个名为 MVC(Minimal Visual Contrasts) 的数据集,通过自动筛选和增强视觉反事实数据来挑战模型,使其能够处理具有最小视觉对比的困难对比案例。实验表明,S-VCO 方法在多个基准测试中显著提升了 VLM 的性能,特别是在减少视觉幻觉和提升视觉中心任务表现方面。

原文链接:https://arxiv.org/pdf/2502.13928
Idiosyncrasies in Large Language Models
本文研究了大型语言模型(LLMs)中的特异性(idiosyncrasies),即模型输出中的独特模式,这些模式可以用来区分不同的模型。通过对不同LLMs生成的文本进行分类,作者探讨了这些特异性在模型输出中的表现及其潜在影响。
本文采取的研究方法如下:
-
合成分类任务:通过对多个LLMs生成的文本进行采样,构建一个N-way分类任务,训练分类器以识别文本输出的来源。使用预训练的文本嵌入模型(如LLM2vec)进行微调,以提高分类准确性。
-
特征提取与分析:应用TF-IDF等方法提取特征短语,并使用逻辑回归模型进行分类,分析不同模型生成文本的特征。进行文本变换(如随机打乱、重写、翻译)以评估特征对分类性能的影响。
-
控制实验:通过控制提示的长度和格式,评估LLMs输出的特异性。比较不同采样策略(如top-k、top-p采样)对模型输出的影响。
本研究揭示了不同LLMs在生成文本时的独特特征,为理解模型之间的差异提供了量化的依据。,这些特异性主要源于词级分布,即使在文本被重写、翻译或总结后,这些模式依然存在,表明它们在语义内容中也被编码。这些特征的识别有助于开发更有效的模型评估和比较方法。
此外,研究表明,使用合成数据进行训练可能会传播模型的特异性,影响模型的泛化能力。这为未来在训练LLMs时选择数据集提供了重要的参考。

原文链接:https://arxiv.org/pdf/2502.12150
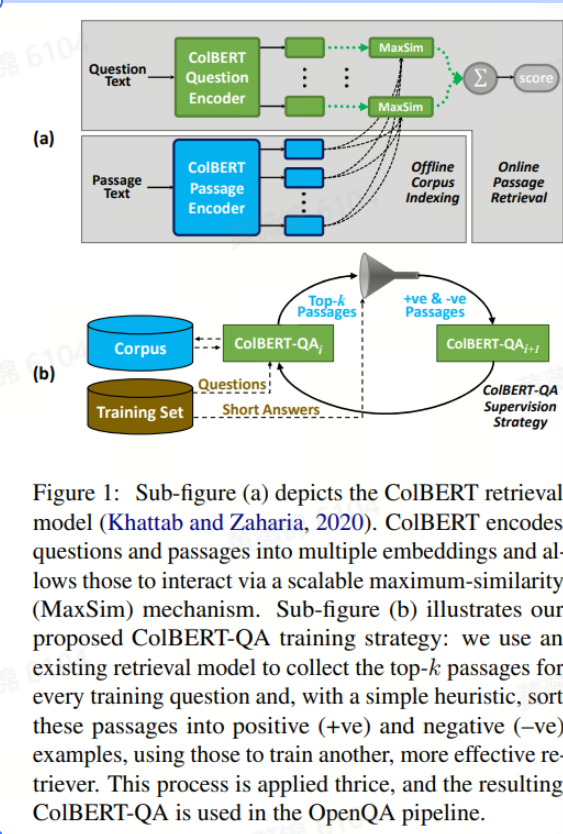
Relevance-guided Supervision for OpenQA with ColBERT
本文介绍了一个名为ColBERT-QA的端到端开放域问答(OpenQA)系统,旨在通过改进检索模型和监督策略来提高OpenQA任务的性能。研究的核心是将ColBERT检索模型应用于OpenQA,并提出了一种高效的弱监督策略——相关性引导监督(Relevance-Guided Supervision, RGS),以提升检索质量和问答性能。
-
ColBERT模型利用BERT对问题和段落进行编码,并通过最大相似性(MaxSim)机制计算问题和段落之间的相似度。该模型通过比较问题和段落的每个词嵌入来实现细粒度的交互,同时保持了对大规模数据的可扩展性。
-
相关性引导监督(RGS),从一个弱检索模型(如BM25)开始,通过迭代检索和排序训练数据,生成正负样本对,用于训练更有效的检索器。RGS通过仅在训练过程中重新索引1-2次,避免了频繁重新索引或冻结文档编码器的问题。
ColBERT-QA通过细粒度的交互机制,显著提高了检索模型对复杂自然语言问题的匹配能力,同时RGS策略提供了一种高效、灵活的弱监督方法,能够自动生成高质量的训练数据,减少了对手工标注数据的依赖。
原文链接:https://arxiv.org/pdf/2007.00814
2. 「理论与实践」AIPM 张涛:关于Diffusion你应该了解的一切
3. 「奇绩潜空间」吕骋访谈笔记 | AI 硬件的深度思考与对话
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2025/02/43048.html