我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
学术分析报告:ResearchFlow — 奇绩F23校友的开发的深度研究产品,PC端进入RFlow的分析报告,可直接点击节点右侧的小数字展开节点,登录后可在节点上直接“询问AI”,进一步探索深度信息 如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!
资讯
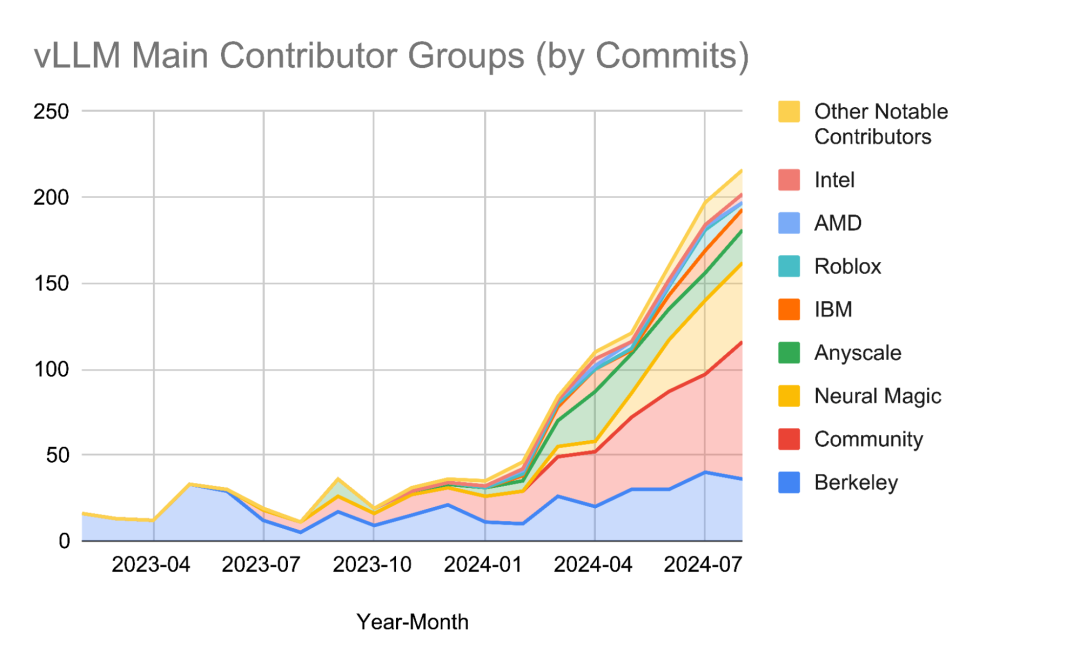
Vertex AI RAG Engine: A developers tool 生成式AI与大语言模型(LLM)正在快速改变各行各业,但在企业应用中,存在两个关键挑战:幻觉(生成错误或无意义的信息)和模型知识的局限性(仅基于训练数据)。通过检索增强生成(RAG)和知识基础的连接,可以使LLM访问实时数据,生成更为准确和相关的响应,从而解决这些问题。 RAG是通过从知识库中检索相关信息并提供给LLM,以生成更准确的响应。这与仅依赖LLM预训练的知识(往往是过时或不完整的)有所不同。RAG的优势在于其能够提供准确性、更新的信息和专业领域知识,适用于需要高准确性和及时数据的企业级应用。 RAG与基础(Grounding)和搜索(Search)有本质的区别。RAG侧重于从外部源头检索并提供与当前任务相关的知识,Grounding则确保AI生成内容的可靠性,将生成的内容与可信的验证来源相结合。搜索则是通过先进的AI模型,快速从数据源中寻找并交付相关信息。 Vertex AI RAG引擎是一个托管服务,简化了检索相关信息并将其馈送给LLM的复杂过程,开发者无需担心基础设施问题,能够专注于应用开发。该引擎的核心优势包括:易于使用的API、托管的工作流、可定制性与开源支持、高质量的Google技术组件、以及灵活的集成方式,能够与多种向量数据库连接。 Google Cloud提供了一系列RAG与基础解决方案,针对不同复杂度和定制需求的应用场景。Vertex AI RAG引擎介于完全自定义与开箱即用之间,为开发者提供了快速原型制作和灵活定制的平衡选择。 在金融、医疗和法律等行业中,RAG引擎可应用于个性化投资建议与风险评估、加速药物发现与个性化治疗计划,以及加强尽职调查与合同审查。在金融领域,RAG引擎通过提供相关文档和数据的精确回答,提高了财务顾问的效率,减少了人工错误,增强了投资建议的个性化和准确性。医疗领域则利用RAG引擎处理海量的生物医学文献与患者数据,帮助研究人员和临床医生提供更精准的治疗方案。法律领域通过加速合同审查与合规性检查,提高了法律专业人员的工作效率与准确性,缩短了交易闭环时间。 https://developers.googleblog.com/en/vertex-ai-rag-engine-a-developers-tool vLLM 2024 Retrospective and 2025 Vision vLLM社区在2024年取得了显著进展,从一个专门的推理引擎成长为开源AI生态系统中公认的服务解决方案。GitHub上的星标数从14,000增长至32,600,贡献者人数从190增至740,月度下载量从6,000增加至27,000,GPU使用时长在过去六个月增长了10倍。这些数据体现了vLLM的广泛应用与社区支持,包括Amazon Rufus与LinkedIn AI等生产环境中的应用,成为了行业合作的战略平台。 2024年,vLLM在模型支持、硬件兼容性和功能特性方面实现了巨大突破。最初vLLM仅支持少数几种模型,到年末已支持近100种主流的开源大语言模型(LLM)及其他多模态、编码解码、推测解码等架构。此外,vLLM扩展了硬件支持,除了最初的NVIDIA A100,还包括NVIDIA H100、AMD MI200系列、Google TPU v4-v6、AWS Inferentia、Intel Gaudi架构等,满足了多种硬件平台上的性能需求。 vLLM的功能也不断增强,2024年增加了诸如权重和激活量化、自动前缀缓存、分布式推理、工具调用等特性。其中,量化方法的加入使得推理更加高效,20%以上的vLLM部署已使用量化技术。此外,vLLM还通过增强的分布式推理能力和优化的标记生成,支持了大规模生产环境中的高效计算需求。 展望2025年,vLLM计划在预训练与推理时的扩展性方面继续突破。目标是使GPT-4o级别的模型能够在单个GPU节点上运行,并在更大的集群中提供下一代的推理能力。为此,vLLM将专注于跨层注意力、专家共享机制、状态空间模型等优化技术,同时根据不同应用场景,如推理、编程、代理框架和创意应用,开发定制的优化路径。 vLLM的成功不仅仅依赖于技术进步,还得益于其开放的架构与社区的协作精神。未来,vLLM将继续推动开源AI推理的普及,通过开放的插件架构与高度定制化的开发模式,确保所有开发者和组织能够根据自己的需求扩展平台功能。此外,vLLM还将加强与数据策展与后训练流程的紧密结合,成为AI开发生命周期中的核心工具。 2025年,vLLM将致力于成为全球最大的生产集群支持平台,推动开源AI在大规模部署中的应用。通过提供默认的优化特性、自动扩展和集群级解决方案,vLLM将进一步降低AI推理的门槛,帮助开发者实现更高效、更可扩展的AI应用。 https://blog.vllm.ai/2025/01/10/vllm-2024-wrapped-2025-vision.html Everything you need to run Mission Critical Inference (ft. DeepSeek v3 + SGLang) 2024年末,DeepSeek v3发布,标志着大型开源语言模型的又一突破,成为全球最强的开源模型之一。然而,随着这些超大规模语言模型的推出,如何高效地提供推理服务成为了一个巨大的技术挑战。Baseten是首家将DeepSeek v3投入生产的推理平台,依赖于其H200集群与与DeepSeek团队的紧密合作。H200集群每台配备141 GB 的 VRAM 和4.8TB的带宽,支持在FP8精度下进行DeepSeek v3推理,并能够满足 KV 缓存需求。 针对大规模推理负载,Baseten团队提出了实现关键推理的三大支柱。第一, 模型级性能 是基础,影响单个 GPU 上模型的运行速度。为了加速推理,团队采用了如推测解码和Medusa头等高级技术。这些方法不仅依赖推理框架,还需要硬件层面的优化,例如 CUDA 内核调整。第二, 横向扩展能力 对于支持大流量至关重要,尤其是在模型需要快速从单一实例扩展到多个实例时。这不是单纯的 机器学习 问题,更是基础设施挑战,涉及如何高效管理和部署成百上千的模型副本。虽然Kubernetes提供了某种程度的扩展能力,但在面临超大规模推理需求时,还需要更复杂的基础设施解决方案。 https://www.latent.space/p/baseten 推特
00 Arxiver开源:包含 138,830 篇 arXiv 论文的多Markdown格
Omni-RGPT:通过标记统一图像和视频区域级理解 🚨Omni-RGPT:通过标记统一图像和视频区域级理解 🌟项目地址: https://miranheo.github.io/omni-rgpt/ Omni-RGPT 是一个统一的多模态大型语言模型,能够同时处理图像和视频的区域级理解。根据用户定义的局部区域输入(如框或掩码)及相应的文本提示,Omni-RGPT 可针对每个区域的视觉上下文生成定制化的响
https://x.com/_vztu/status/1880787174079041890 CityDreamer4D:无界的 4D 城市生成,能够将静态和动态场景分离却兼具真实感
🔥无界的 4D 城市生成🔥
#CityDreamer4D 是一种生成模型,可以创建无界的 4D 城市,能够将静态和动态场景分离,同时兼具真实感和可控性。 项目地址: https://infinitescript.com/project/city-dreamer-4d/ 代码仓库: https://github.com/hzxie/CityDreamer4D CityTopia 数据集: https://gateway.infinitescript.com/s/CityTopia
https://x.com/liuziwei7/status/188097852772368011 2
投融资
00 Arxiver开源:包含 138,830 篇 arXiv 论文的多Markdown格式
Investing in Eve
Eve是一款AI原生案件工作平台,旨在为原告律师提供智能支持,帮助他们提高案件处理效率,最多可处理4倍以上的案件量。美国每年约有6600万件案件由原告提起,但全美只有43万家律师事务所,且案件数量远远超过律师的处理能力。由于原告律师主要采用风险代理模式,他们只有在成功为客户争取到财务赔偿或有利判决时才能获得报酬。因此,律师的时间和处理能力极为有限,这使得Eve平台显得尤为重要。
Eve通过全面覆盖案件生命周期的多个模块,极大提升了律师事务所的工作效率。其服务内容包括:客户接收——通过程序化筛选和评估案件的潜力,Eve帮助事务所快速筛查大量案件;案件处理——为律师提供详细的医疗时间表、案件风险分析及潜在赔偿计算,帮助他们迅速准备诉状和发现材料,同时提升客户沟通效率;事务所管理——作为案件和客户信息的中央存储库,Eve还可以支持账单处理、员工培训和专家证人网络等其他工作流程。 Eve的独特之处在于其“行动系统”的设计,它不仅仅是案件管理工具,更是帮助律师处理案件的智能伙伴。通过AI和机器学习的持续迭代,Eve在帮助律师处理案件的同时,积累经验,进一步优化案件筛选和处理流程,形成了一个正向的飞轮效应。 Eve的市场表现非常出色,在过去的8个月里,Eve与超过80家新律师事务所合作,客户量增长了800%。客户如Barrett和Farahany律师事务所表示,Eve大大缩短了任务时间,例如将发现材料的响应时间从20小时缩短到仅30分钟。这些显著的效率提升使得Eve在业界引起了广泛关注,并且获得了投资者的高度认可。 公司官网:https://www.eve.legal/ https://a16z.com/announcement/investing-in-eve/ — END — 快速获得3Blue1Brown教学动画?Archie分享:使用 Manim 引擎和 GPT-4o 将自然语言转换为数学动画
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2025/01/36478.html