

-
ImageNet-P有十个常见类型的绕动,例如几个像素的变化。在这种情况下,mFR和mT5D是是标准的方法去评估模型的鲁棒性。 -
ImageNet-R和ImageNet的标签类相同,只是在不同领域之间增加了semantic shift。 -
ImageNet-A 主要针对多标签分类问题下,类别标签误分类的问题。同时还包括一些纹理细节。 -
ImageNet-O 数据主要针对训练和测试标签不一致的情况下,是否模型预测有较低的置信度。 -
ImageNet-9 主要面向需要背景的视觉任务,而不只是关注前景。

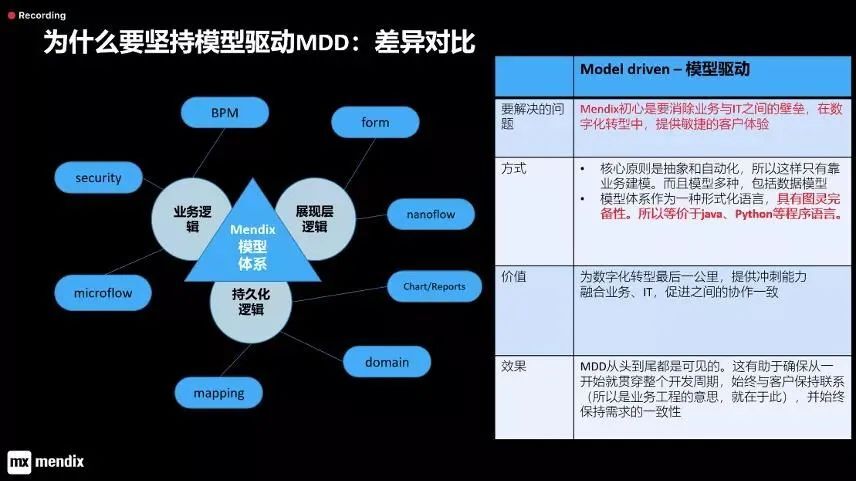
Mendix 披露低代码方法论,解读真实技术趋势
Google机器臂能抓手帕了,软的硬的都能抓!ICRA 2021已接收

OpenAI新研究:扩散模型在图像合成质量上击败BigGAN,多样性还更佳

Facebook AI 研究院在无监督语音识别上取得新突破,wav2vec-U性能直逼监督模型
END







原创文章,作者:整数智能,如若转载,请注明出处:https://www.agent-universe.cn/2021/05/8439.html