


MOLAR FRESH 2021年第13期
人工智能新鲜趣闻 每周五更新
AI现在能教你画画了?!
画画新手们,如何才能画出一副像样的手绘肖像?除了假以时日的练习,或许也可以借助下面这款工具!
这款工具叫做dualFace。它可以根据初始线条给出人像全局框架和局部细节的素描线条,辅助绘画新手和普通用户画出像样的肖像画。
在全局引导阶段,dualFace根据用户绘制的大概轮廓,就能从内部数据库中搜索出若干相关人像,并在画布背景上显示建议的人脸轮廓线。
在局部引导阶段,dualFace利用全局指导绘制的轮廓线,用深度生成模型合成人脸图像,然后将合成结果的细节(眼睛、鼻子、嘴等)作为辅助线条给出来。
首先用户只需画出人脸轮廓图,计算机能提示肖像整体结构的线条供参考,接着,再给出人脸细节的提示线条,最终,就能画出这样一幅作品了!




从试验者从全局和局部以及整体使用感受上的问卷调查结果来看,满分5分,平均分都在3.9以上。从整体用户体验来看,所有参与者都认为该工具可以帮助他们更好地绘制肖像。
(来源:量子位)
网上的假货太多?你把握不住的,让AI来!
还在发愁网购的东西可能是假货?
现在,阿里自己搞了个AI打假师,让算法来协助打假了!只要让它看一眼想辨认的商品照片,它就能在几十毫秒的时间里,判断出商品的真假。
相当于你一眨眼(约0.5秒),它就已经识别了10个假货。
不仅如此,阿里安全团队还公开了一个包含100万张正版商标照片的数据集Open Brand,让更多的人能参与到“AI打假”行动中来。Open Brand是全球最大的奢侈品logo数据集,包含500多个奢侈品大类、1000多个子类商标,累计超过100万张商标logo图片,每张图片,都按COCO结构进行了详细标记。
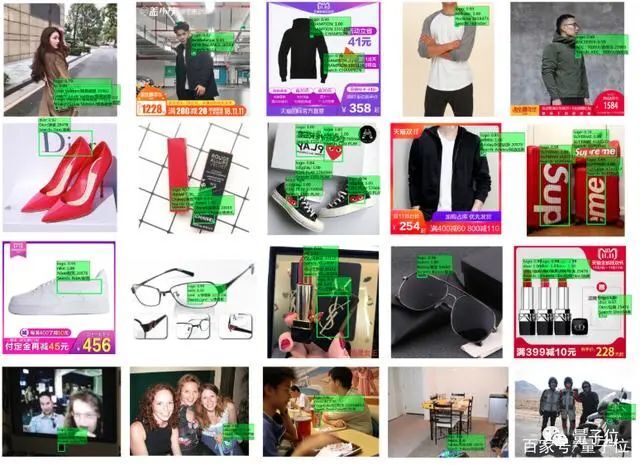
测试表明,这个AI“打假师”,在NVIDIA的多种显卡(T4、P100、V100)上都已经取得了非常快速的检测效果,平均在30~50ms内就能识别一件假货。而且,识别的效果还非常好,线上图片的识别准确率,达到了95%。
当然,网购平台不会完全根据AI“打假师”的判断结果,直接对商家进行处罚。
在AI“打假师”找出疑似售卖假货的商家后,平台还会从商品内容、售卖信息、资质、消费者反馈等多个维度进行调查,以判断商家是否存在卖假货的情况。
目前,阿里安全团队已经利用技术打假,协助警方侦破了好几起案件,光是奢侈品包包假货特大案就有6起,并捣毁了生产窝点10余个、抓获犯罪嫌疑人150余名。
(来源:量子位)
你的论文 “后劲儿” 有多大?MIT科学家开发AI预知模型,能更早、更准锁定 “隐藏宝石”
怎样评估一篇学术论文发表后是否有 “影响力”?
目前,业内普遍采用基于引文的指标,比如所著论文的引用量、H-index(H 指数,一个混合量化指标,用于评估研究人员的学术产出数量与水平),以及期刊影响因子在时间和领域内的归一化测度等。
为了实现对论文 “影响力” 的准确分析评估,来自麻省理工学院的科学家 James Weis 和 Joseph Jacobson 建立了一个名为 DELPHI的机器学习模型,并用知识图谱加以训练,从而可以更早、更准地锁定那些未来有影响力的科研成果,相关论文于 5 月 17 日发表在《自然 – 生物技术》(Nature Biotechnology)期刊上。

DELPHI 的开发者们使用的数据集包含 1980-2019 年期间发表的 1687850 篇具有唯一性的论文,包括 780 多万个单独节点、2.01 亿个关系和 38 亿个计算指标,从中得到了论文发表后 1-5 年与每例论文、作者、期刊、网络相关的 29 个特征,作者再用每篇论文的特征训练一个机器学习模型,让这个模型给出影响力 “预警” 信号。
在一次回顾性盲法研究中,DELPHI 准确识别出了 1980-2014 年期间 20 项具有重大影响的生物技术中的 19 项,还以数据驱动的方式发现并促进经费流向那些 “深藏不露” 的好研究项目。DELPHI 未来或将用于更准确地评估科研人员的产出质量和水平,有望成为一种全新的学术影响力评估手段。

对于 DELPHI,研究人员强调,这仅仅是走出了科学文献机器辅助分析的实践第一步。DELPHI 应该被理解为更广泛的科学分析工具包的一部分,与人类经验和直觉结合使用,以增强而不是取代人类水平的理解。
(来源:中国人工智能学会)
科普机器人亮相北京科技周,可与公众进行海量科普知识展示、对话问答
5 月 22 日上午,2021 年全国科技活动周暨北京科技周启动仪式在中关村国家自主创新示范区展示中心举行。在北京科技周的现场,一个名叫 “小科” 的科普机器人,耐心回答大家的各种知识提问。尤其是面对孩子们的好奇发问,“小科” 都能够耐心、专业地做出回答。

据了解,“小科” 科普机器人由智谱 AI、清华大学和北京智源研究院的团队联合完成,运用超大规模预训练模型、自然语言处理和知识图谱等先进的人工智能技术,打造一个 “智能科普数字脑”,通过实体机器人可完成海量科普知识问答、诗词创作、人设问答和开放式对话等任务,可应用在科普教育、文化传播和智能问答等场景。
项目团队的负责人之一、智谱・AI 合伙人和高级副总裁左家平表示,小科机器人的功能是基于智谱・AI 底层技术研发。智谱・AI 的唐杰教授团队提出了数据融合知识的双轮驱动人工智能框架。小科的核心组件 “智能科普数字脑” 就是依靠这一双轮驱动的人工智能框架开发。
在未来,赋予小科智慧的科普数字脑不仅仅能搭载在实体机器人上,还可以在数字人、全息人、手机和电脑中发挥能力,从而更方便地进入人们的日常生活,为智能科普服务发挥作用。
(来源:学术头条)
清华团队最新成果:可致特朗普能咏比特币,AI写古诗“更上一层楼”
比特币
外挖无穷洞,机神犹未休。
卡中窥币影,池里验沙流。
屡载吸金主,孤深渍盗求。
方知区块链,本是古来游。
这首诗歌来自一支清华团队开发的古诗 AI。你仍可以在文采上对它有所挑剔,但不得不承认的是,这至少是一个不会离题万里的 AI,尤其还是颇具难度的古诗生成。(论文::Controllable Generation from Pretrained Language Models via Inverse Prompting)
在自然语言处理领域,作诗这一任务被归类为生成任务。此前的大部分预训练模型在生成符合题意的句子上仍力不从心。为了解决这个问题,团队成员提出了一个全新的文本可控生成方法 Inverse Prompting,显著提升了对预训练语言模型生成结果的控制能力。
为了提高模型输出中国诗歌概率,团队找到的解决方案是:在生成诗词语句的过程中,放松对于 Perplexity 得分的要求,增加 Beam Search 中的随机性,然后采用诗词规则及 Inverse Prompting 控制生成语句的格式及质量,使其满足中国古典诗歌的格律规范。
原创文章,作者:整数智能,如若转载,请注明出处:https://www.agent-universe.cn/2021/05/8438.html