我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即
学术分析报告:ResearchFlow — 奇绩F23校友的开发的深度研究产品,PC端进入RFlow的分析报告,可直接点击节点右侧的小数字展开节点,登录后可在节点上直接“询问AI”,进一步探索深度信息 如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢 迎 大 家 一 起 交 流 !
信号 SPOT: SE(3) Pose Trajectory Diffusion for Object-Centric Manipulation 这篇文章介绍了一个基于对象的模仿学习框架,称为SPOT。其主要思路是通过对象中心的表示来捕捉每个任务,具体来说是相对于目标的 SE(3) 对象姿态轨迹。该方法将 执行动作 与 感知输入 解耦,使其能够从多种类型的示范中学习,包括基于动作和无动作的人类手部示范,同时支持跨实体的泛化。 此外,对象姿态轨迹天然地从示范中捕捉规划约束,而无需手动制定规则。为了指导机器人执行任务,SPOT 使用对象轨迹来调节扩散策略。实验结果表明,SPOT 在 RLBench 模拟任务 中相较于现有工作有显著改进。在真实环境中,仅使用八个由 iPhone 拍摄的示范,SPOT 完全符合任务约束地完成了所有任务。 https://arxiv.org/abs/2411.00965 Edify 3D: Scalable High-Quality 3D Asset Generation 这篇文章介绍了Edify 3D,一种用于高质量 3D 资产生成的先进解决方案。其方法首先通过扩散模型生成目标物体在多个视角下的 RGB 图像 和 表面法线图。然后使用这些多视角观测来重建物体的形状、纹理和 PBR 材质。Edify 3D 能在 2 分钟内 生成具有精细几何结构、干净拓扑、高分辨率纹理和材质的高质量 3D 资产。 https://arxiv.org/abs/2411.07135
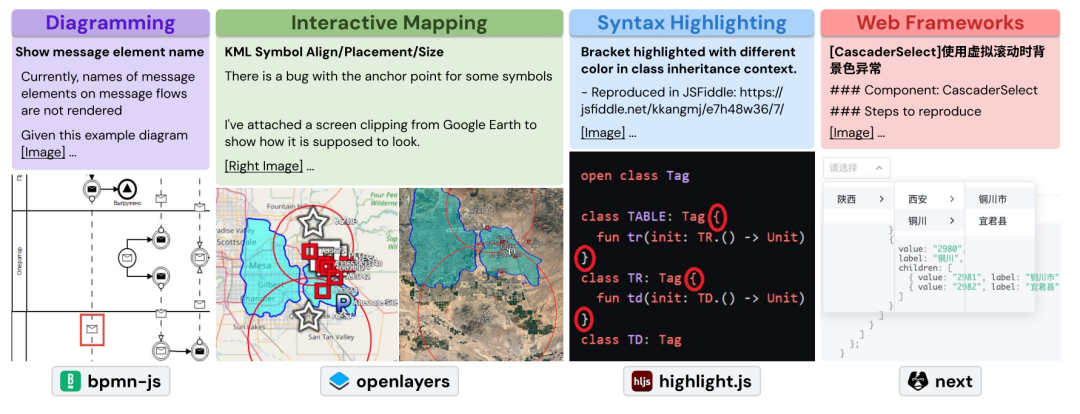
SWE-bench Multimodal: Do AI Systems Generalize to Visual Software Domains? 这篇文章提出了 SWE-bench Multimodal (SWE-bench M),用于评估自主软件工程系统在修复视觉、用户界面相关的 JavaScript 软件中的 bug 的能力。虽然现有的系统普遍在 SWE-bench(仅包含 Python 仓库,问题陈述以文本形式呈现,缺乏视觉元素)上进行评估,但这种单一覆盖范围促使我们研究这些系统在其他未被代表的软件工程领域(如前端、游戏开发、DevOps)中的表现。 SWE-bench M 包含 617 个任务实例,来自 17 个用于网页界面设计、图表、数据可视化、语法高亮和交互式地图的 JavaScript 库。每个任务实例中至少包含一个图像在问题陈述或单元测试中。分析发现,许多在原 SWE-bench 中表现良好的系统在 SWE-bench M 中表现不佳,揭示了它们在视觉问题解决和跨语言泛化方面的局限性 最后,研究表明,SWE-agent 的语言无关特性使其在 SWE-bench M 上的表现明显优于其他系统,成功解决了 12% 的任务实例,而次佳系统仅解决了 6%。 https://www.swebench.com/multimodal
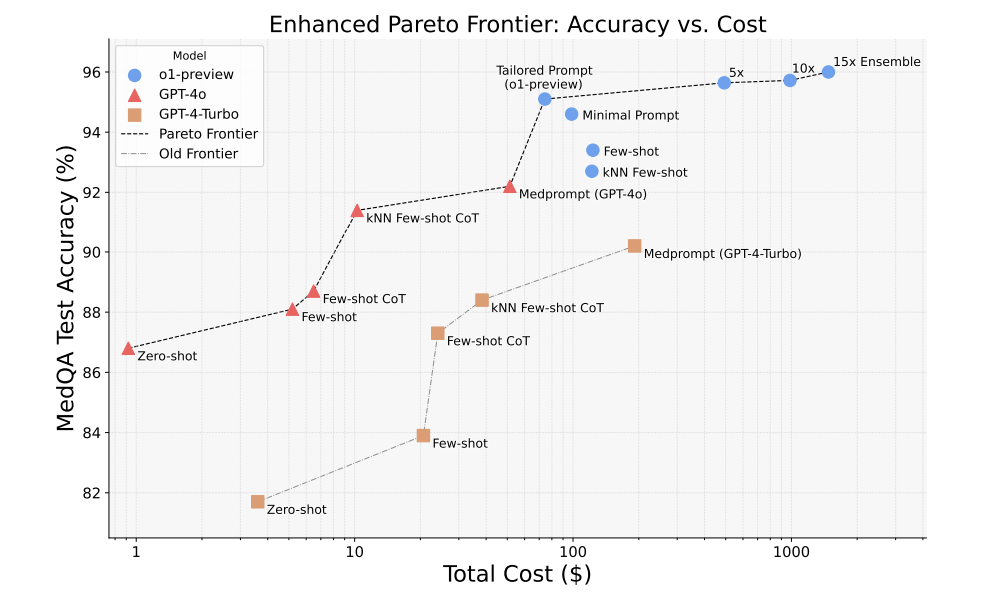
From Medprompt to o1: Exploration of Run-Time Strategies for Medical Challenge Problems and Beyond 这篇文章研究了运行时引导策略(如Medprompt)在指导大型语言模型(LLMs)在复杂任务中实现顶尖表现的价值,特别是在医学领域。Medprompt 通过提示来引导通用 LLM 进行链式推理和集成,从而在医学等专业领域中达到最先进的性能。 OpenAI 的 o1-preview 模型代表了一种新的范式,旨在在生成最终响应之前进行运行时推理。本文在多个医学基准上系统地评估了 o1-preview 的表现,结果表明,即便没有提示工程,o1-preview 也大大超越了 GPT-4 系列结合 Medprompt 的表现。此外,我们对经典提示工程(如 Medprompt)在新型推理模型中的有效性进行了系统研究,发现少样本提示反而降低了 o1 的性能,这表明上下文学习可能不再是推理原生模型的有效引导方式。虽然集成仍然是可行的方法,但它对资源的要求较高,需要进行成本与性能的权衡。 在运行时策略的成本和准确性分析中,我们识别出 Pareto 前沿,其中 GPT-4o 提供了更具性价比的选择,而 o1-preview 则在较高成本下实现了最先进的性能。尽管 o1-preview 提供了顶尖的表现,但在某些特定情况下,结合 Medprompt 的 GPT-4o 依然具有价值。此外,我们注意到 o1-preview 在许多现有的医学基准上已接近性能饱和,强调了开发新的、更具挑战性的基准测试的必要性。 最后,文章对 LLM 在推理时的计算策略进行了反思,探讨了未来研究的方向。 https://arxiv.org/abs/2411.03590v1 FasterCache: Training-Free Video Diffusion Model Acceleration with High Quality 这篇文章介绍了 FasterCache,一种无需训练的新策略,旨在加速视频扩散模型的推理过程,同时保持高质量的生成效果。在对现有的缓存方法进行分析时,作者发现直接复用相邻步长的特征会因为细微变化的丢失而降低视频质量。基于此,文章进一步研究了无分类器引导(CFG)的加速潜力,揭示了同一时间步内条件特征与无条件特征之间存在显著冗余。 基于这些观察,FasterCache通过以下两大创新显著加速基于扩散的视频生成:(1) 提出了一种动态特征复用策略,既能保持特征的区别性,也能维护时间上的连续性;(2) 提出 CFG-Cache,优化条件和无条件输出的复用,以在不影响视频质量的前提下提升推理速度。 实验评估表明,FasterCache在最近的视频扩散模型上显著提高了生成速度,例如在 Vchitect-2.0 上实现了 1.67× 加速,同时保持视频质量与基准模型相当,并且在推理速度和视频质量方面始终优于现有方法。 https://arxiv.org/abs/2410.19355
OmniEdit OMNI-EDIT 是一种多功能图像编辑器,可以解决现有图像编辑方法在实际应用中的局限性。OMNI-EDIT 通过利用七个专业模型的监督训练,采用基于大型多模态模型评分的重采样方法提高数据质量,提出了新的编辑架构 EditNet 来提升编辑成功率,并提供不同纵横比的图像以增强模型的通用性。经过自动和人工评估,OMNI-EDIT 显著优于现有模型,具备处理多种图像编辑任务的能力。相关代码、数据集和模型将公开发布。 https://tiger-ai-lab.github.io/OmniEdit/
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/11/21694.html