
特别活动


我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。

资讯
Karpathy称赞,从零实现LLaMa3项目爆火,半天1.5k star
 https://mp.weixin.qq.com/s/1poG0tEjmym1456mmR66nQ
https://mp.weixin.qq.com/s/1poG0tEjmym1456mmR66nQ首个GPU高级语言,大规模并行就像写Python,已获8500 Star
 https://mp.weixin.qq.com/s/dC7Z5Rk05sM7ND7bYUsrZA
https://mp.weixin.qq.com/s/dC7Z5Rk05sM7ND7bYUsrZA数据更多更好还是质量更高更好?这项研究能帮你做出选择
 https://mp.weixin.qq.com/s/EvPCCw7OAB-1wdSTmykJLQ
https://mp.weixin.qq.com/s/EvPCCw7OAB-1wdSTmykJLQ消息称苹果首席运营官威廉姆斯访问台积电,探讨 AI 芯片开发

科学家提出新型智能体,距离实现全过程自主化更近一步
 https://mp.weixin.qq.com/s/MqoHxFPsT_cVDB7go7CODg
https://mp.weixin.qq.com/s/MqoHxFPsT_cVDB7go7CODg让大模型理解手机屏幕,苹果多模态Ferret-UI用自然语言操控手机
 https://mp.weixin.qq.com/s/GPsnp51OaCO0MCRlXTDObQ
https://mp.weixin.qq.com/s/GPsnp51OaCO0MCRlXTDObQ推特
从零实现llama3的代码库:所有层次的仔细解析
 https://x.com/naklecha/status/1792244347225641338
https://x.com/naklecha/status/1792244347225641338Ethan Mollick:为了在工作中有效地使用人工智能,领导者和员工需要反思他们的工作对他人和对自己的意义
 https://x.com/emollick/status/1792302281737596930
https://x.com/emollick/status/1792302281737596930
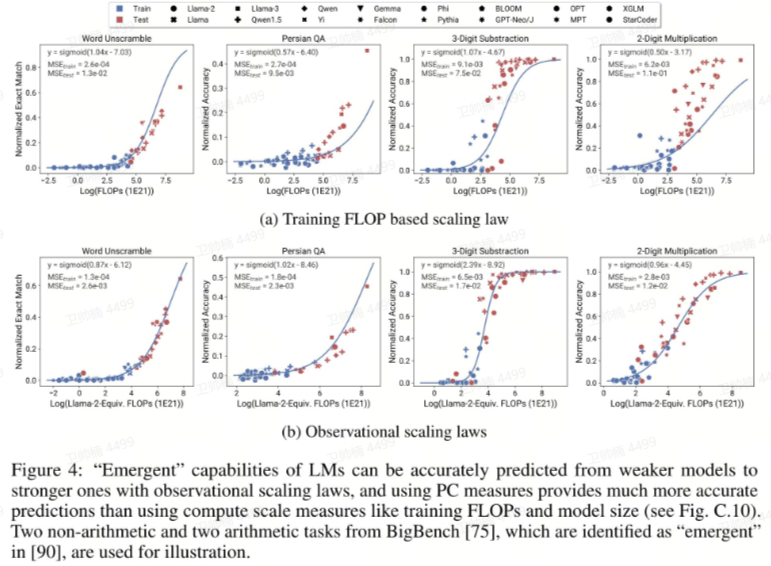
Json Wei谈Scaling Laws论文:在单一模型家族中,通常模型的大小不多,这会影响预测能力
-
在单一模型家族中,通常模型的大小不多,这会影响预测能力。然而,有许多模型家族。如果你能以某种方式标准化模型家族之间的差异,所有数据都可以在同一个图上,从而得到更好的分辨率。 -
不同基准测试的性能高度相关,也许某些关键能力(自然语言理解、推理、编码)可以预测许多下游任务的表现。 -
将横轴从计算量改为“f等效FLOPs”,即参考模型家族匹配某个模型能力所需的计算量。 -
事实证明,这比单纯使用计算量具有更好的预测能力。这个截图中的图表令人印象深刻;你可以用蓝点来预测红点。 -
很酷的是,他们正在预注册他们的预测,并将在几个月内更新草稿。很有趣,看看他们是否能预测最大的Llama 3的性能。 -
我非常好奇:我们能把蓝点推到多远的左边,还能预测红点?蓝点经常逐渐靠近拐点。如果你能用小一个数量级的模型预测拐点,那将是非常酷的。 -
有一点我没有完全理解,那就是观察缩放律的x轴点的计算是否需要“大模型”在“核心能力”上的表现。从图3来看,他们似乎确实使用了大模型的评估性能?
 https://x.com/_jasonwei/status/1792401639552565496
https://x.com/_jasonwei/status/1792401639552565496
Mervin Praison根据Karpathy分享完成视频:GPT-4o从零开始构建LLM操作系统
 https://x.com/MervinPraison/status/1792258982645563874
https://x.com/MervinPraison/status/1792258982645563874Devon:GPT-4o和Claude的配对编程,在本周完全本地化
 https://x.com/akiradev0x/status/1792246200172953701
https://x.com/akiradev0x/status/1792246200172953701
Rowan Cheung分享ChatGPT Mac应用使用视频:终极截图转代码工具
 https://x.com/rowancheung/status/1792234214890336581
https://x.com/rowancheung/status/1792234214890336581
产品
ChatPlayground AI
 https://www.chatplayground.ai/
https://www.chatplayground.ai/User Evaluation AI—— 用户访谈 Agent
 https://www.userevaluation.com/ai-curated-interviews
https://www.userevaluation.com/ai-curated-interviews原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/05/15263.html