欢迎观看大模型日报 , 如 需 进 入 大 模 型 日 报 群 和 空 间 站 请 直 接 扫 码 。 社 群 内 除 日 报 外 还 会 第 一 时 间 分 享 大 模 型 活 动 。
资 讯
流浪地球里的数字生命计划启动了? DeepMind在电脑里造果蝇,网友:能造人吗? 在《流浪地球 2》中,刘德华饰演的图恒宇是一个令人印象深刻的角色。为了让在车祸中去世的女儿拥有「完整的一生」,他不顾人类世界对「数字生命计划」的禁令,一直在暗中独自努力完善数字生命的架构,并最终决定公然违规,将女儿的数据上传至量子计算机,之后因此被捕入狱。最近,谷歌 DeepMind 和美国 Janelia 研究园区(霍华德・休斯医学研究所成立的神经科学研究机构)共同研究出的一个虚拟果蝇,它能像真实的果蝇一样行走和飞行。同时,它也是迄今为止最逼真的果蝇模拟,结合了新的解剖学精确模型、快速物理模拟器和根据果蝇行为训练的人工神经网络,以模仿真实果蝇的动作。除了在复杂的轨迹上行走和飞行,虚拟果蝇还能用眼睛控制和引导飞行。「你获取真实的果蝇数据 —— 它们是如何飞行的,如何行走的 —— 训练网络来模仿这些动作,然后让我们训练好的这个网络来控制果蝇,告诉果蝇如何运动,」Janelia Turaga 实验室的机器学习研究员 Roman Vaxenburg 领导了这个项目。他说,「它就像一个小型大脑,控制着果蝇的动作」。新模型是该团队虚拟果蝇的首次迭代,他们计划利用更多的解剖和感官特征以及真实的神经网络使其更加逼真。这也是他们所希望实现的一系列逼真动物模型中的第一个。他们和其他研究人员现在可以利用这个通用的开源框架来开发这些模型。
一句指令就能冲咖啡、倒红酒、锤钉子 清华具身智能CoPa「动」手了 近期,具身智能方向取得了诸多进展。从谷歌的 RT-H 到 OpenAI、Figure 联合打造的 Figure 01,机器人的交互性、通用性越来越强。如果未来机器人成为人们日常生活的助手,你期待它们能够完成哪些任务?泡一杯热气腾腾的手冲咖啡,整理桌面,甚至帮你精心安排一场浪漫的约会,这些任务,只需一句指令,清华的具身智能新框架「CoPa」都能完成。CoPa(Robotic Manipulation through Spatial Constraints of Parts)是清华叉院高阳教授机器人研究团队最新提出的具身智能框架,首次实现了多场景、长程任务、复杂3D行为的泛化能力。得益于对视觉语言大模型(VLMs)的创新使用,在不经过任何训练的前提下,CoPa 可以泛化到开放场景中,处理复杂的指令。CoPa 最令人惊喜的是它展现出对场景中物体的物理属性具备细致的理解,以及其精确的规划与操作能力。
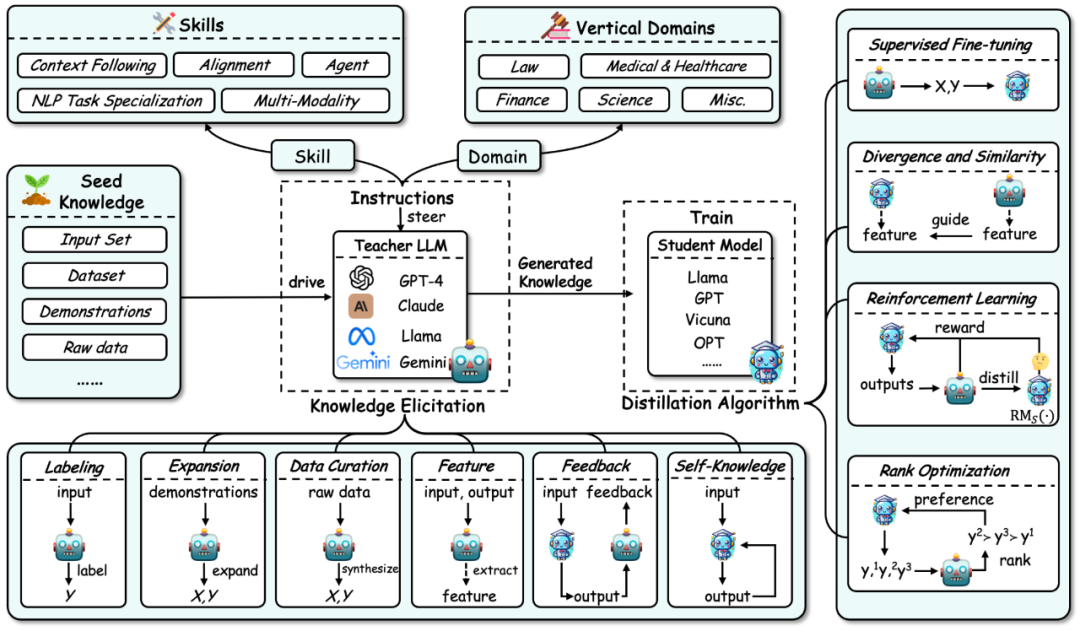
总结374篇相关工作 陶大程团队联合港大、UMD发布LLM知识蒸馏最新综述 大语言模型(Large Language Models, LLMs)在过去两年内迅速发展,涌现出一些现象级的模型和产品,如 GPT-4、Gemini、Claude 等,但大多数是闭源的。研究界目前能接触到的大部分开源 LLMs 与闭源 LLMs 存在较大差距,因此提升开源 LLMs 及其他小模型的能力以减小其与闭源大模型的差距成为了该领域的研究热点。LLM 的强大能力,特别是闭源 LLM,使得科研人员和工业界的从业者在训练自己的模型时都会利用到这些大模型的输出和知识。这一过程本质上是知识蒸馏(Knowledge, Distillation, KD)的过程,即从教师模型(如 GPT-4)中蒸馏知识到较小的模型(如 Llama)中,显著提升了小模型的能力。可以看出,大语言模型的知识蒸馏技术无处不在,且对于研究人员来说是一种性价比高、有效的方法,有助于训练和提升自己的模型。2024 年初,陶大程团队与香港大学和马里兰大学等合作,发表了最新综述《A Survey on Knowledge Distillation of Large Language Models》,总结了 374 篇相关工作,探讨了如何从大语言模型中获取知识,训练较小模型,以及知识蒸馏在模型压缩和自我训练中的作用。同时,该综述也涵盖了对大语言模型技能的蒸馏以及垂直领域的蒸馏,帮助研究者全面了解如何训练和提升自己的模型。 COLING24丨 自适应剪枝让多模态大模型加速2-3倍 哈工大等推出SmartTrim 基于 Transformer 结构的视觉语言大模型(VLM)在各种下游的视觉语言任务上取得了巨大成功,但由于其较长的输入序列和较多的参数,导致其相应的计算开销地提升,阻碍了在实际环境中进一步部署。为了追求更为高效的推理速度,前人提出了一些针对 VLM 的加速方法,包括剪枝和蒸馏等,但是现有的这些方法大都采用静态架构,其针对不同输入实例采用同样的计算图进行推理,忽略了不同实例之间具有不同计算复杂性的事实:针对复杂的跨模态交互实例,自然需要更多计算才能完全理解图像和相关问题的复杂细节;相反,简单的实例则可以用更少的计算量解决。这也导致较高加速比下的 VLM 的性能严重下降。为了解决上述这些问题,哈工大联合度小满推出针对多模态模型的自适应剪枝算法 SmartTrim,论文已被自然语言处理顶级会议 COLING 24 接收。
腾讯混元最新图生视频模型! 想动哪里点哪里,诸葛青睁眼原来长这样 | 开源 新的图生视频模型Follow-Your-Click,由腾讯混元、清华大学和香港科技大学联合推出。研究团队还将Follow-Your-Click和其他视频生成模型进行了同题对比。此前图生视频模型的生成方法,一般都需要用提示词描述运动区域,并提供运动指令的详细描述。从生成效果来看,过往技术在指定图像移动部分缺乏控制,往往是让整个场景动起来,而不是具体到图像上的某个区域。为了解决这些问题,腾讯混元大模型团队、清华和港科大联合项目提出了更实用和可控的图像到视频生成模型Follow-Your-Click。实现方式上,Follow-Your-Click首先整合了图像语义分割工具Segment-Anything,将用户点击转换为二进制区域Mask,将其作为网络条件之一。其次,为了更好地正确学习时间相关性,团队还引入了一种有效的首帧掩模策略。 https://mp.weixin.qq.com/s/HN5gQ6_g4FJjmBL6GB1JGQ 使用 LLM 设计「硅大脑」 Hopkins 团队利用 ChatGPT 自动描述尖峰神经元阵列 大型语言模型(LLM)能够根据各种提示(包括代码生成)合成听起来合理的响应,因此受到了广泛的关注。约翰霍普金斯大学(Johns Hopkins University)的电气和计算机工程教授 Andreas Andreou 团队正利用 LLM 开创一种创建神经网络芯片的新方法——神经形态加速器,可以为自动驾驶汽车和机器人等下一代实体系统提供节能、实时的机器智能。Andreou 实验室的 Michael Tomlinson 和 Joe Li 使用自然语言提示和 ChatGPT(GPT-4) 生成详细指令来构建脉冲神经网络芯片:一种运行方式与人脑非常相似的芯片。通过 ChatGPT 的逐步提示,从模仿单个生物神经元开始,然后连接更多生物神经元形成网络,他们生成了可以制造的完整芯片设计。该设计流程展示了如何使用 ChatGPT 进行自然语言驱动的硬件设计。AI 生成的设计使用手工制作的测试台进行了模拟验证,同时已提交使用开源 EDA 流程,并且交给芯片厂商进行了实体制造。「这是第一个由机器使用自然语言处理设计的人工智能芯片。这类似于我们告诉计算机『制作人工智能神经网络芯片』,计算机会吐出用于制造芯片的文件。」Andreas Andreou 说道。
纳德拉对话挪威财富基金 CEO 谈 AI 范式转变对经济影响与科技支出 本周,挪威银行 CEO Nicolai Tangen 与微软 CEO Satya Nadella 进行了一场关于科技、企业文化、个人成长和未来趋势的讨论。Nadella 首先表达了对微软成为世界上市值最高公司的自豪,同时也意识到作为 CEO 的责任。他强调了科技行业的不断变化,以及在这样的行业中,没有所谓的特许经营价值,意味着必须不断创新。关于范式转变,Nadella 讨论了微软正在经历的,这是他职业生涯中经历的第四次,他强调了在新的技术平台上找到立足之地的重要性,并对未来的可能性感到兴奋。 苹果为杀入AI领域低调收购 iOS 18要有大动作 在 AI 领域百花齐放的当下,作为全球顶尖的科技公司苹果,似乎掀起的水花不是很大。苹果在 AI 领域的布局到底是什么,或许苹果 CEO 蒂姆・库克的一句话可以为我们答疑解惑。此前在 2024 苹果股东大会上,库克表示,今年将在 GenAI领域实现重大进展。此外,苹果宣布放弃 10 年之久的造车项目之后,一部分造车团队成员也开始转向 GenAI。如此种种,苹果向外界传达了加注 GenAI 的决心,很多人开始感叹苹果在生成式 AI 领域终于不再低调了。显然,苹果在宣布放弃造车计划后,也拿出了一些卓有成效的研究。昨天,苹果首次披露了多模态大模型 MM1, 这是一个具有高达 30B 参数的多模态 LLM 系列。不仅是发表学术论文,在战略性收购方面,苹果已经开始摩拳擦掌了。据彭博社报道,苹果公司在其收购名单中增加了另一家人工智能初创公司DarwinAI,该公司以开发在制造过程中对零件进行视觉检查的AI技术而闻名。此外,这家初创公司在创建更小、更快的人工智能系统方面的专业知识与苹果专注于在端侧运行人工智能(而不仅仅是基于云的解决方案)的目标相一致。或许,苹果正是看中了这一点,这项收购才得以完成。 从直观物理学谈到认知科学 Sora不是传统物理模拟器盖棺定论了? 最近,OpenAI 的文生视频模型 Sora 爆火。除了能够输出高质量的视频之外,OpenAI 更是将 Sora 定义为一个「世界模拟器」(world simulators)。当然,这一说法遭到了包括图灵奖得主 Yann LeCun 在内很多学者的反驳。LeCun 的观点是:仅仅根据 prompt 生成逼真视频并不能代表一个模型理解了物理世界,生成视频的过程与基于世界模型的因果预测完全不同。近日,澳大利亚麦考瑞大学的哲学助理教授 Raphaël Millière 撰写了一篇长文,深入探讨了 Sora 究竟是不是「世界模拟器」。作者回顾了 Sora 的功能、工作原理以及它模拟 3D 场景属性的意义,讨论了认知科学中直观物理学文献、机器学习中「世界模型」的多义(多种解释)概念以及图像生成模型的可解释性研究。结论是:Sora 并没有运行传统意义上的模拟,尽管它可能在更有限的意义上表现出了视觉场景的物理属性。但是,行为证据不足以充分评估 Sora 是世界模拟器这一说法。最后,作者对视频生成模型在未来 AI 和机器人学中的地位,以及它们与认知科学中正在进行的辩论之间的潜在相关性进行了预测。 大模型能自己优化Prompt了 曾经那么火的提示工程要死了吗? 2022 年底,ChatGPT 上线,同时引爆了一个新的名词:提示工程(Prompt Engineering)。简而言之,提示工程就是寻找一种编辑查询(query)的方式,使得大型语言模型(LLM)或 AI 绘画或视频生成器能得到最佳结果或者让用户能绕过这些模型的安保措施。现在的互联网上到处都是提示工程指南、快捷查询表、建议推文,可以帮助用户充分使用 LLM。在商业领域,现在也有不少公司竞相使用 LLM 来构建产品 copilot、自动化繁琐的工作、创造个人助理。之前在微软工作过的 Austin Henley 最近采访了一些基于 LLM 开发 copilot 产品或服务的人:「每一家企业都想将其用于他们能想象到的每一种用例。」这也是企业会寻求专业提示工程师帮助的原因。但一些新的研究结果表明,提示工程干得最好的还是模型自己,而非人类工程师。这不禁让人怀疑提示工程的未来 —— 并且也让人越来越怀疑可能相当多提示工程岗位都只是昙花一现,至少少于当前该领域的想象。 https://mp.weixin.qq.com/s/H6xrD2WxuXwj1tZOuYQ_Kw 推特 DexCap:一个价值3,600美元的开源硬件堆栈 用于记录人类手指的运动,以训练灵巧的机器人操作 DexCap:一个价值3,600美元的开源硬件堆栈,用于记录人类手指的运动,以训练灵巧的机器人操作。它就像是Optimus的一个非常 “低保真” 的版本,但学术研究人员也能负担得起。这不是远程操作:数据采集与机器人执行是分离的,因此您不需要一对一的人类操作员时刻看管机器人。这是来自 @chenwang_j 和 @StanfordAILab 的出色工作! https://x.com/DrJimFan/status/1768323865317671413?s=20
高分辨率图像放大器 轻松控制幻觉、相似性和创造力的数量 在过去的几个月里,我一直在对 Magnific AI 著名的放大器进行逆向工程。它使用了 MultiDiffusion、ControlNet 瓷砖和细节 LoRa。本着 AI 的真正精神,我将其开源,供大家在应用程序中免费使用。它旨在轻松控制幻觉、相似性和创造力的数量。你现在可以在 Replicate 上使用它:https://replicate.com/philipp1337x/clarity-upscaler… 或者在本地使用 A1111 的 Web UI 运行它(参数在注释中)。代码是完全开源的:https://github.com/philz1337x/clarity-upscaler https://x.com/philz1337x/status/1768679154726359128?s=20
yi-9b-200k发布 https://x.com/erhartford/status/1768938400705618146?s=20
“MindGraph”开源:概念验证的入门套件 用于构建不断扩展的知识图谱并使用自然语言进行查询 开源 “MindGraph”,这是一个概念验证的入门套件,用于构建不断扩展的知识图谱并使用自然语言进行查询! https://x.com/yoheinakajima/status/1769019899245158648?s=20
Beta Royban:智能眼镜中的Whomane Pin 数千人使用了 Whomane Pin,许多人要求将其放入智能眼镜中。
在 #DreamXR 黑客马拉松中,我们构建了 Beta Royban。
它的工作原理如下:
https://x.com/kodjima33/status/1769161815626489879?s=20
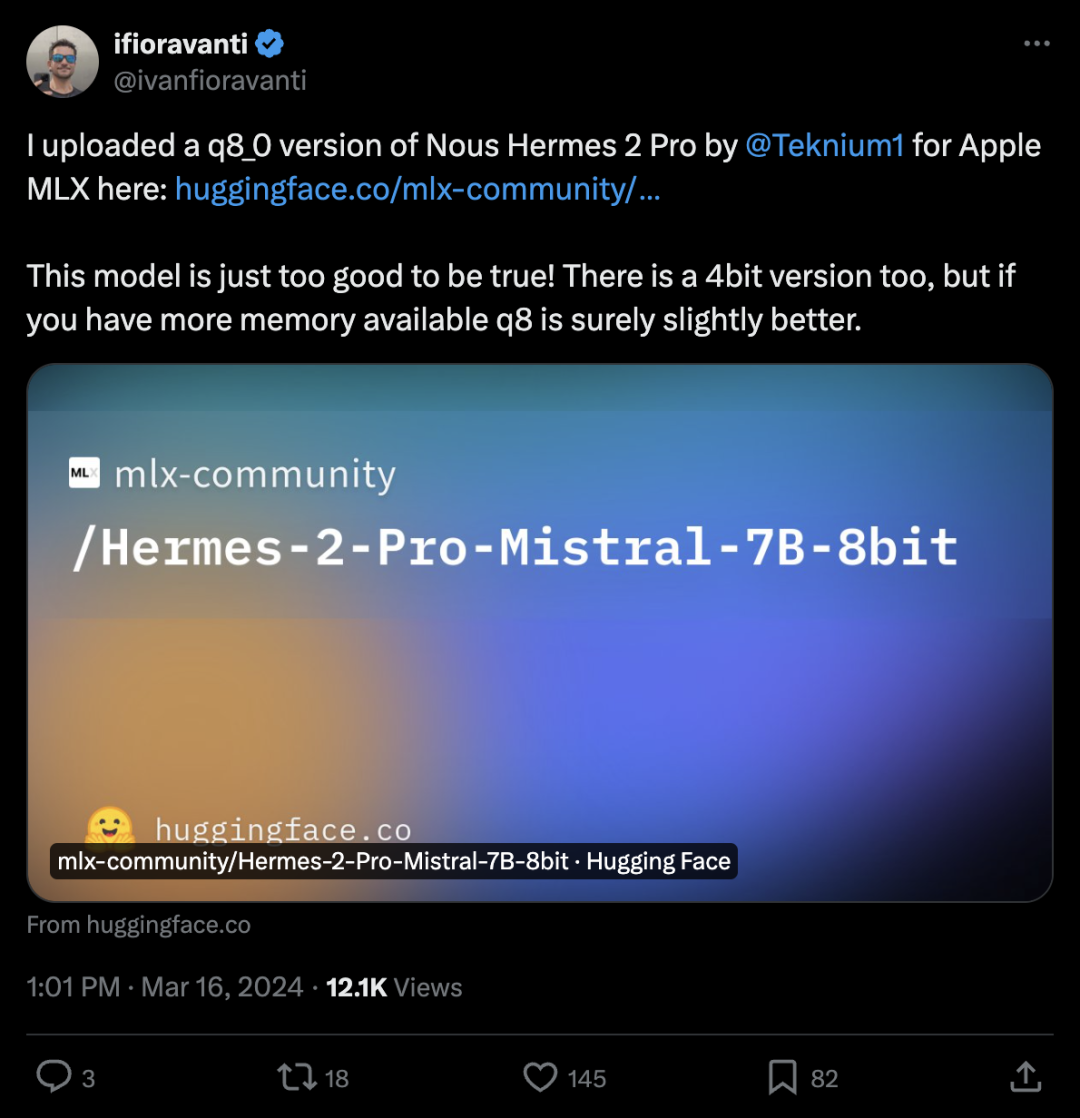
Nous Hermes 2 Pro q8_0 版本,用于 Apple MLX 我在此处上传了由 @Teknium1 开发的 Nous Hermes 2 Pro 的 q8_0 版本,用于 Apple MLX:https://huggingface.co/mlx-community/Hermes-2-Pro-Mistral-7B-8bit 这个模型实在是太棒了,简直难以置信!还有一个4位版本,但如果你有更多可用内存,q8 版本肯定会稍微更好一些。 https://x.com/ivanfioravanti/status/1769091733336273304?s=20
EagleX 1.7T 在英语和多语言评估中飞越 LLaMA 7B 2T(RWKV-v5) EagleX 7B 仅使用了 1.7 万亿 token,就在英语评估中平均击败了 llama2 7B。这将开源研究中最好的模型带入其中:
2T token 以下的最佳英语模型(超过 LLaMA)
同时还是一个无需注意力机制的线性 transformer
https://x.com/picocreator/status/1768951823510180327?s=20 Watney Robotics分享技术细节 已经使整个技术栈防弹,软件相关的停机时间为0 在伯克利,我们喝真正的咖啡。每天早上至少喝6杯浓缩咖啡。 我们是如何做到的?下面我们将阐述独特的技术方法以及最近使这一切成为可能的催化剂。 我们移除了旧的ROS2堆栈,并用Rust重新手工打造了整个架构(毕竟我们是纯粹主义者)。这使得系统延迟大幅下降,从操作员到机器人的关键路径不受阻碍。命令端的系统延迟现在约为3.4毫秒。 那么视频流呢?我们的联合创始人有在各种专有交易公司构建低延迟交易系统的背景。当你的软件太慢时,就用硬件来实现。我们使用专门的ASIC芯片实现硬件加速视频编码和压缩,通过定制的摄像头电路在线传输比特,时间不到10毫秒。 等等,但是网络延迟呢?好吧,我们要感谢 @elonmusk 也让光速提高了30%。我们通过真空传输信号比光纤的延迟更低。我们从 @SpaceX 的一些朋友那里了解到激光链路即将上线。事实证明,在300英里高空,横跨地球一条直线传输比在BGP边界之间往返要快得多。 我们现在的情况如何?我们已经使整个技术栈防弹,软件相关的停机时间为0(Rust太棒了),并且我们将在未来几个月内在旧金山湾区部署试点。你会看到我们的人悄悄出现——他们将很难被忽视。 https://x.com/watneyrobotics/status/1769058250731999591?s=20 Tim Brooks 和 Bill Peebles在UCB分享的Sora的技术细节 OpenAI 的 Sora 团队的 Tim Brooks 和 Bill Peebles 出现在加州大学伯克利分校的 Alberto 课堂上 https://x.com/dotey/status/1769263376415215731?s=20 产品
Opencord AI 2.0 Opencord AI 提供 AI Agents 帮助用户处理繁重的工作,让他们能够专注于核心业务。这些 AI Agents 可以帮助用户在社交媒体平台上生成、策划和管理内容,用户可以利用 AI 技术更好的搭建属于自己的社交媒体账号。 https://www.opencord.ai/
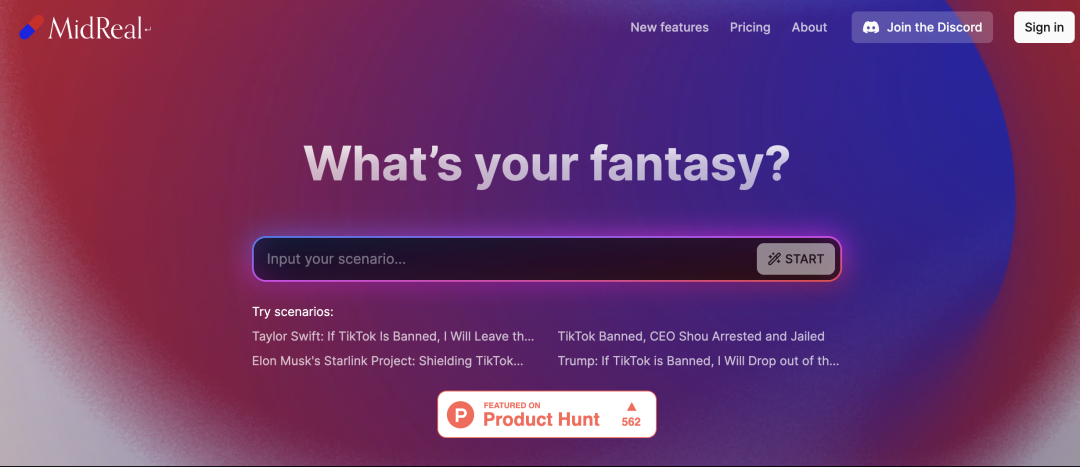
MidReal MidReal 是一个借助 AI Agent 创建个性化交互故事的平台。用户通过进入自己设定的一个故事场景,然后通过与 AI 的交互做出关键选择引导故事的无限展开。目前,Midreal 计划推出视频模式,提供用户量身定制的互动电影体验。 https://midreal.ai/
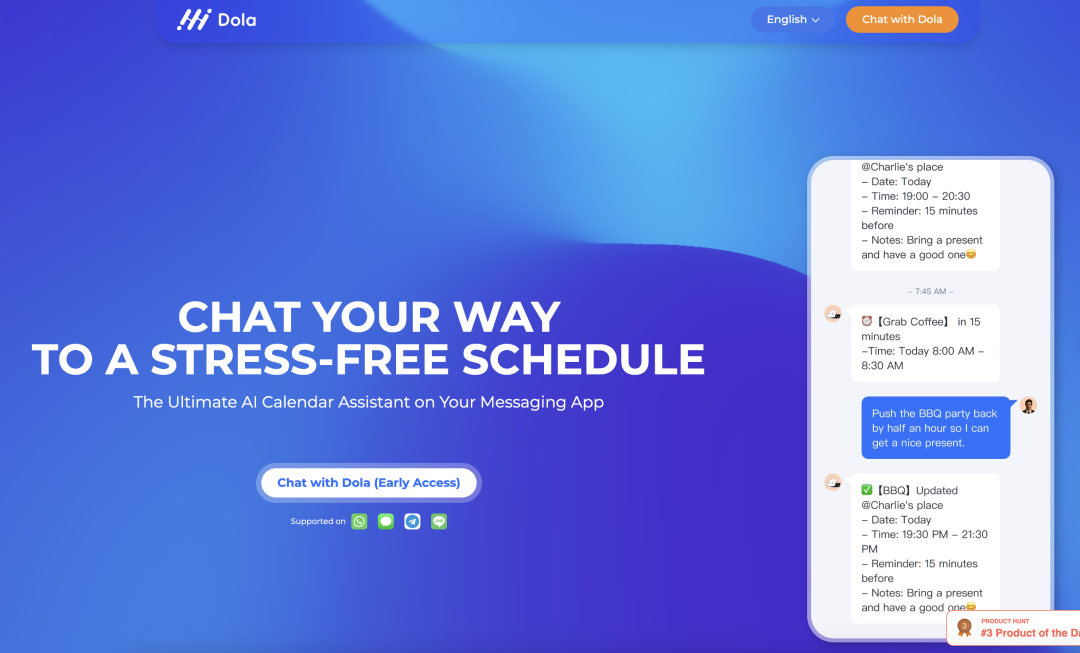
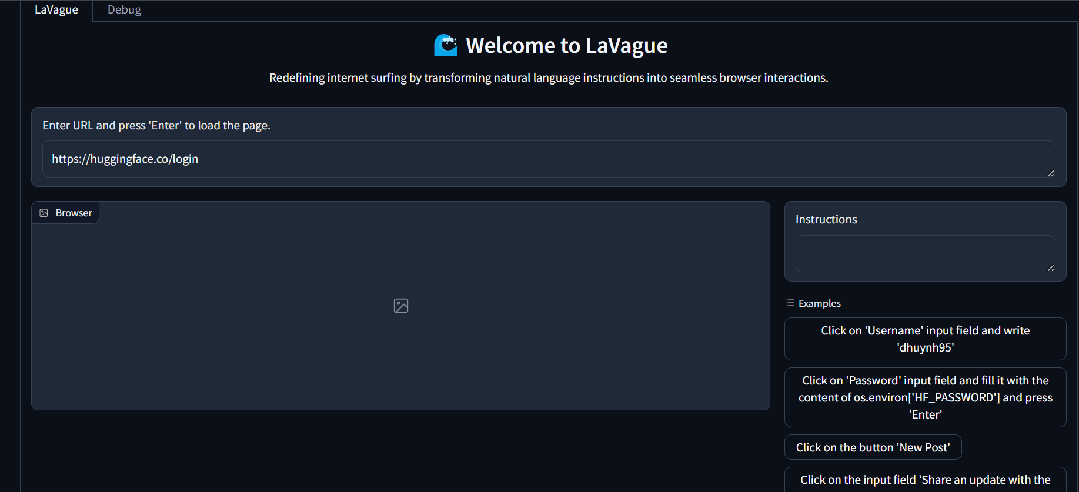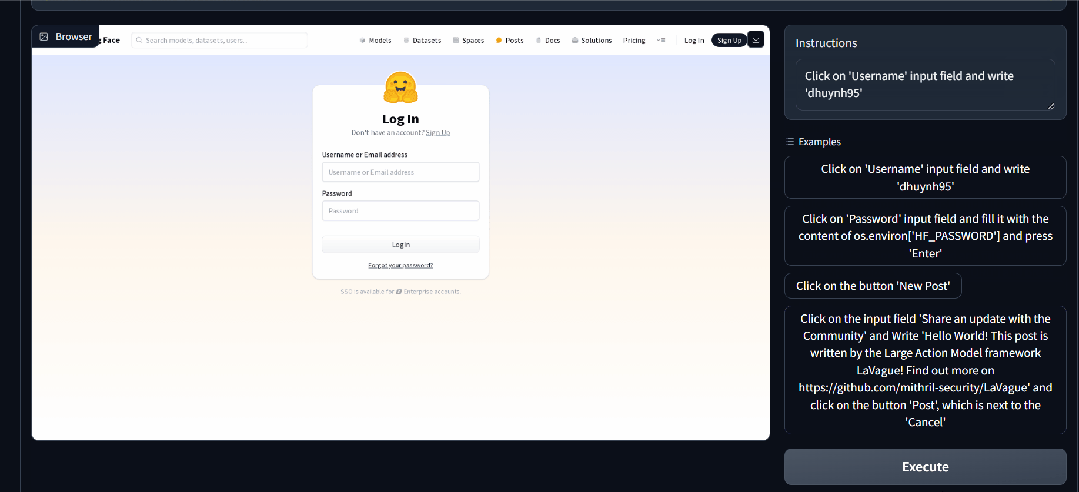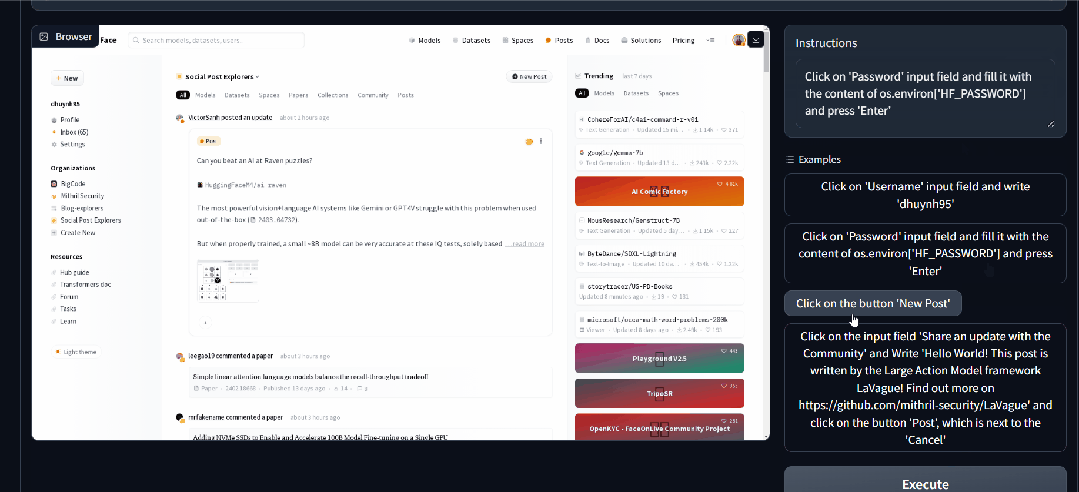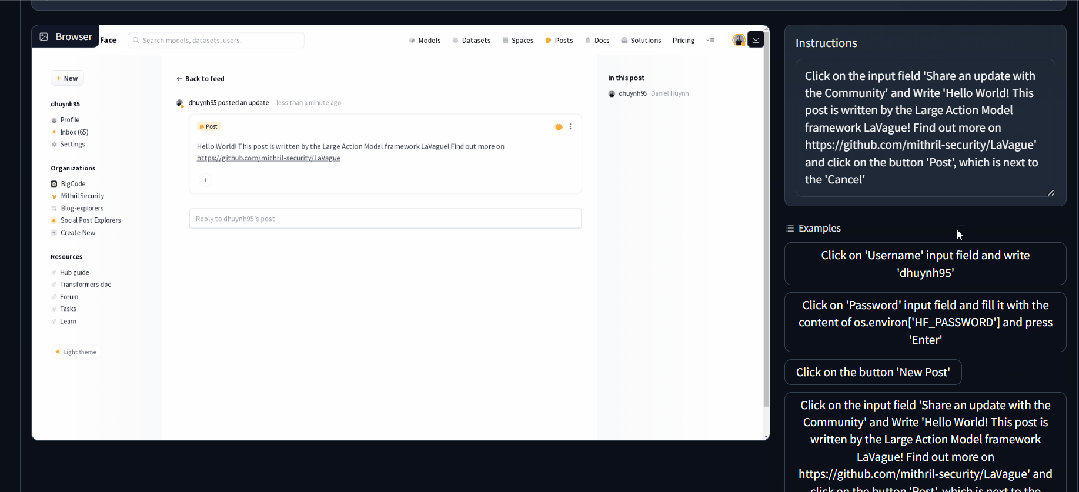
Dola Dola 是一款 AI 日历助手,帮助用户管理时间和安排日程。它可以将书面文字、语音消息甚至图片转换成一系列日历事件,并在恰当的时刻提醒用户。 https://hidola.ai/ H uggingFace&Github LaVague LaVague 是一个帮助用户自动执行琐碎任务的工具。它提供了一个引擎,可以将自然语言查询转换为 Selenium 代码,使用户或其他人工智能能够轻松地自动执行 Web 工作流程并在浏览器上运行。其目的是节省用户时间,让他们能够专注于更重要的事情,如自动支付账单、填写表格或从特定网站提取数据。 https://github.com/lavague-ai/LaVague RisuAI RisuAI,简称 Risu,是一款跨平台的 AI 聊天软件/Web 应用程序。
https://github.com/kwaroran/RisuAI
Emo-LLM EmoLLM 是一系列能够支持 理解用户-支持用户-帮助用户 心理健康辅导链路的心理健康大模型。 https://github.com/SmartFlowAI/EmoLLM 学习 大模型推理 A100/H100 太贵,何不用 4090? 本文讨论了在大模型训练和推理中使用NVIDIA的A100/H100与RTX 4090显卡的性价比问题。结论是,对于大模型训练,4090显卡由于通信效率低和内存容量小,不适合使用。然而,在推理方面,4090显卡性价比较高,尤其是在极致优化后,性价比可达H100的两倍。文章还详细分析了H100/A100与4090在算力、内存、通信带宽和成本上的差异,并探讨了大模型训练和推理的算力需求、GPU训练性能和成本对比,以及大模型训练时的并行策略。最后,作者提出了一种使用家庭分布式算力进行大模型推理的设想,以及对AI芯片市场的一些看法。
https://zhuanlan.zhihu.com/p/655402388
何时应微调 LLM 何时又该使用 RAG 本文探讨了在开发检索增强生成(RAG)系统时遇到的12个常见技术痛点,并提供了相应的解决方案。这些痛点包括内容缺失、错过排名靠前的文档、整合战略的局限性、未提取信息、格式错误、不正确的具体性、不完整的回答、数据摄入的可扩展性、结构化数据问答、从复杂PDF中提取数据、回退模型和LLM安全问题。提出的解决方案涉及数据清洗、更好的提示设计、超参数调整、重新排序检索结果、调整检索策略、微调嵌入模型、输出解析、并行处理摄取管道、链表包链、混合自一致性包、嵌入式表检索、中微子路由器、OpenRouter以及Llama Guard等内容。这些方法旨在提高RAG系统的性能、准确性和安全性,以更好地满足用户需求。 https://www.zhihu.com/question/638730387/answer/3384974118?utm_psn=1752299132117516288
微调大型语言模型进行命名实体识别 本文介绍了如何对大型语言模型(LLM)进行微调以进行命名实体识别(NER),特别是在处理个人身份信息(PII)时。文章讨论了微调过程中的挑战,包括避免生成幻觉实体和确保输出结构良好。提出了两种输出格式:JSON编码字符串和带实体标签的标记字符串。强调了提示设计的重要性,并介绍了如何使用“Chain-Of-Thought”来提高模型理解任务的能力。此外,还探讨了自定义损失函数以专注于计算有效令牌的损失,从而提高模型的泛化能力。实验结果显示,使用字符串标记方法的效果优于JSON格式,且模型在测试集上达到了96%以上的精度、召回率和F1分数。作者还提出了关于模型大小对性能影响的进一步研究问题。 https://mp.weixin.qq.com/s/B6fY7Isg9skB1sAw_PfOIg PMF框架 | Sequoia Capital Sequoia Capital介绍了Arc产品市场适应性框架,旨在帮助早期创业公司寻找产品与市场的契合点。文章概述了三种产品市场适应性类型:紧急需求(Hair on Fire)、普遍接受的痛点(Hard Fact)和未来愿景(Future Vision),每种类型都有其独特的客户产品关系动态。对于早期创业者而言,理解和识别这些路径有助于他们更有效地定位其产品和市场策略,从而在竞争激烈的市场中脱颖而出。文章强调,不同的路径需要不同的运营优先级,创业者应根据自己的独特优势和客户需求,选择最适合自己的路径。 https://www.sequoiacap.com/article/test-pmf-framework-2/
大模型日报 5
大模型日报 · 目录
上一篇 大模型日报(3月15日)
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/03/16830.html



 https://mp.weixin.qq.com/s/Qn10lSrwe-mvQVwNnsIm-Q
https://mp.weixin.qq.com/s/Qn10lSrwe-mvQVwNnsIm-Q