特别活动!


欢迎观看大模型日报,如需进入大模型日报群和空间站请直接扫码。社群内除日报外还会第一时间分享大模型活动。

资讯
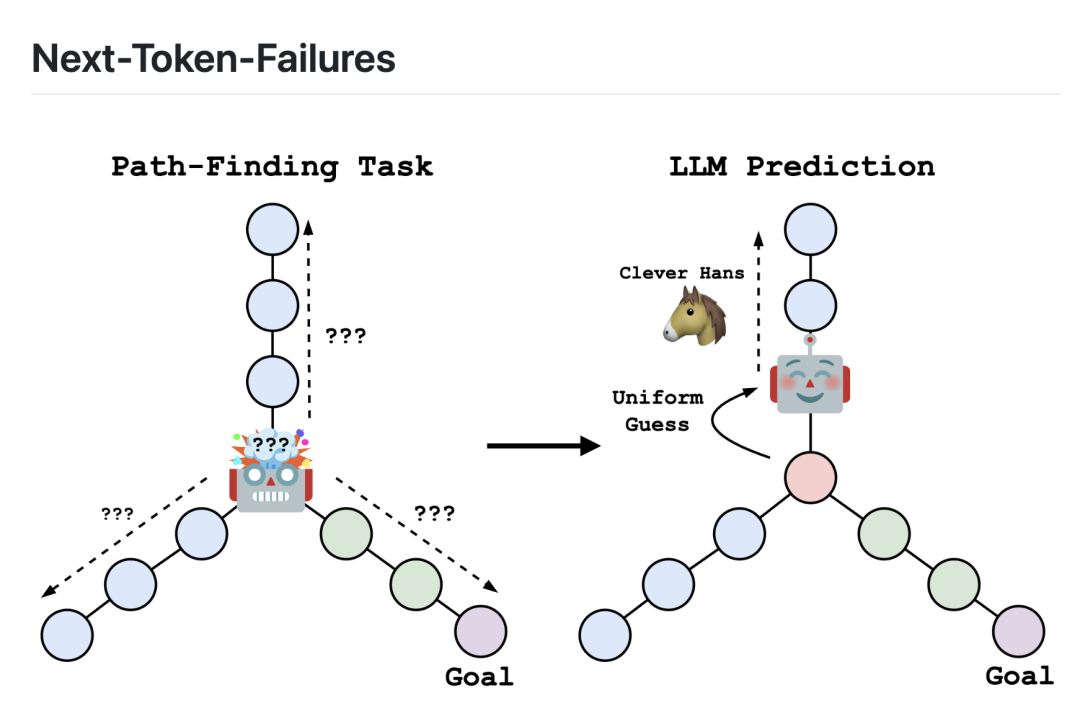
讨论下一个token预测时,我们可能正在走进陷阱
自香农在《通信的数学原理》一书中提出「下一个 token 预测任务」之后,这一概念逐渐成为现代语言模型的核心部分。最近,围绕下一个 token 预测的讨论日趋激烈。然而,越来越多的人认为,以下一个 token 的预测为目标只能得到一个优秀的「即兴表演艺术家」,并不能真正模拟人类思维。人类会在执行计划之前在头脑中进行细致的想象、策划和回溯。遗憾的是,这种策略并没有明确地构建在当今语言模型的框架中。对此,部分学者如 LeCun,在其论文中已有所评判。在一篇论文中,来自苏黎世联邦理工学院的 Gregor Bachmann 和谷歌研究院的 Vaishnavh Nagarajan 对这个话题进行了深入分析,指出了当前争论没有关注到的本质问题:即没有将训练阶段的 teacher forcing 模式和推理阶段的自回归模式加以区分。
剑桥团队开源:赋能多模态大模型RAG应用,首个预训练通用多模态后期交互知识检索器
PreFLMR模型是一个通用的预训练多模态知识检索器,可用于搭建多模态RAG应用。模型基于发表于 NeurIPS 2023 的 Fine-grained Late-interaction Multi-modal Retriever (FLMR) 并进行了模型改进和 M2KR 上的大规模预训练。
通用文档理解新SOTA,多模态大模型TextMonkey来了
最近,华中科技大学和金山的研究人员在多模态大模型Monkey [1](Li et al., CVPR2024)工作的基础上提出 TextMonkey。在多个场景文本和文档的测试基准中,TextMonkey 处于国际领先地位,有潜力带来办公自动化、智慧教育、智慧金融等行业应用领域的技术变革。TextMonkey 是一个专注于文本相关任务(包括文档问答和场景文本问答)的多模态大模型(LMM)。相比于 Monkey,TextMonkey 在多个方面进行改进:通过采用零初始化的 Shifted Window Attention,TextMonkey 实现了更高输入分辨率下的窗口间信息交互;通过使用相似性来过滤出重要的图像特征,TextMonkey 不仅能够简化输入,还可以提高模型的性能。此外,通过扩展多个文本相关任务并将位置信息纳入回答,TextMonkey 增强了可解释性并减少了幻觉。与此同时,TextMonkey 在微调之后还可以具备 APP Agent 中理解用户指令并点击相应位置的能力,展现了其下游应用的巨大潜力。
100%化学有效,高度类似药物,川大开发数据和知识双驱动的AI分子生成框架
基于深度学习的分子生成在许多领域都有广泛的应用,特别是药物发现。然而,目前的深度生成模型大多数是基于配体的,在分子生成过程中没有考虑化学知识,往往导致成功率相对较低。四川大学的研究团队提出了一种基于结构的分子生成框架,称为 PocketFlow;该框架明确考虑了化学知识,可在蛋白质结合袋内生成新型配体分子,用于基于结构的从头药物设计。在各种计算评估中,PocketFlow 表现出了最先进的性能,生成的分子具有 100% 化学有效且高度类似药物。研究人员将PocketFlow应用于两个与表观遗传调控相关的新靶蛋白 HAT1 和 YTHDC1,并成功获得了湿实验室验证的生物活性化合物。活性化合物与靶蛋白的结合模式与分子对接预测的相近,并通过 X 射线晶体结构进一步证实。
准确率达95.16%,快速识别恶性肿瘤细胞,厦大和上海交大团队开发域泛化深度学习算法
单细胞和空间转录组测序是两种最近优化的转录组测序方法,越来越多地用于研究癌症和相关疾病。细胞注释,特别是恶性细胞注释,对于这些研究中的深入分析至关重要。然而,当前的算法缺乏准确性和泛化性,使得难以一致、快速地从泛癌数据中推断出恶性细胞。为了解决这个问题,厦门大学和上海交通大学的研究团队提出了 Cancer-Finder,一种基于域泛化(Domain Generalization,DG)的深度学习算法,可以快速识别单细胞数据中的恶性细胞,平均准确率达到 95.16%。重要的是,通过用空间转录组数据集替换单细胞训练数据,Cancer-Finder 可以准确识别空间幻灯片上的恶性 spots。
今年目标1亿活跃用户!Perplexity联手Arc浏览器对抗Google背后产品逻辑
近日,Perpleixity 创始人&CEO Aravind Srinivas 对话了现任 Stripe CTO David Singleton,讨论了 Perplexity 如何构建一种新的 AI 驱动的传统搜索引擎替代方案、迄今为止的历程,以及其背后的技术。Aravind 的核心观点包括:早期商业模式的重要性:Aravind 强调了早期实现盈利的重要性,认为这有助于构建更可持续、长期的业务,并为公司带来更多的筹码和杠杆。关于产品方向的思考:Aravind 讨论了如何在创业初期确定产品方向,强调了对产品市场契合度的认识和追求,并指出了不断调整和优化产品路线图的重要性。广告模式的演进:Aravind对广告模式进行了思考,强调了广告的相关性对于用户体验的重要性。他认为,未来的广告模式可能会更加融入用户体验,以提高广告的相关性和吸引力。数据收集和处理的挑战:他谈到了在数据收集方面可能面临的挑战,尤其是在争取对特定网站的访问权限方面。同时,他也提到了数据收集中可能出现的偏见问题,以及如何应对这些问题。关于内容生成的思考:Aravind对于内容生成的影响提出了一些见解,特别是针对搜索引擎优化对内容质量的影响。他认为,通过为用户提供高质量的内容,大型语言模型(LLMs)可能会对内容的生成产生积极影响。
百度将为苹果今年国行 iPhone 16 等设备提供 Al功能
百度将为苹果今年发布的iPhone16、Mac系统和iOS18提供AI功能。苹果曾与阿里以及另外一家国产大模型公司进行过洽谈,最后确定由百度提供这项服务。
 https://www.chinastarmarket.cn/detail/1628550
https://www.chinastarmarket.cn/detail/1628550
推特
70亿参数开源模型玩《毁灭战士》,基于游戏当前帧的ASCII表示
牛逼!一个在旧金山参加 @MistralAI 黑客马拉松的团队训练了70亿参数的开源模型来玩《毁灭战士》(DOOM),基于游戏当前帧的ASCII表示。@ID_AA_Carmack
 https://x.com/DynamicWebPaige/status/1771990295095419055?s=20
https://x.com/DynamicWebPaige/status/1771990295095419055?s=20
使用一个简单的命令,从你的抄本和非结构化信息中生成漂亮的文档
使用一个简单的命令,从你的抄本和非结构化信息中生成漂亮的文档。
一种从你的会议记录和大型文档中生成全面、易于浏览的文档的简单方法。
 https://x.com/hrishioa/status/1771934209730605506?s=20
https://x.com/hrishioa/status/1771934209730605506?s=20
FRIEND – 一款AI可穿戴设备,成本约20美元
Nik Shevchenko:今天我看到另一个”开源”AI可穿戴设备发布,它没有发布任何东西,只是向你收取5倍的费用。在@MistralAI x @cerebral_valley 在@SHACK15sf 举办的黑客马拉松中,我们打造了FRIEND – 一款AI可穿戴设备:
给我们24小时完成黑客马拉松,并发布GitHub仓库。
 https://x.com/kodjima33/status/1772011777066442819?s=20
https://x.com/kodjima33/status/1772011777066442819?s=20
Virat分享:微调沃伦·巴菲特LLM过程
总体目标:微调一个LLM来像巴菲特先生那样分析公司。
我在@huggingface上找到了一个数据集,其中包含1977-2019年巴菲特信函的问答对。
非常感谢@ShawhinT提供的初始代码和YouTube教程。
接下来的步骤是增加数据集大小,清理提示,微调更大的模型,最终包括来自10-K等的新数据。
 https://x.com/virattt/status/1772000677910155370?s=20
https://x.com/virattt/status/1772000677910155370?s=20
Gatekeep:文本到视频AI,将你的问题转化为引人入胜的教育解说视频
介绍Gatekeep,这是一款文本到视频的AI,可以将你的问题转化为引人入胜的教育解说视频。现已在网页和Discord上推出。
访问 http://gatekeep.ai 开始使用。
 https://x.com/gatekeep_labs/status/1771329975230370283?s=20
https://x.com/gatekeep_labs/status/1771329975230370283?s=20
Dupe.com:在任何网站上输入前缀,找到任何家具项目的最佳价格
女士们先生们,我想向你们介绍一下 @dupedotcom 。我与 @ghoshal 在这个工具的概念和设计上密切合作,以找到任何家具项目的最佳价格。它还不完美——但最终它将拦截互联网上的每一笔交易。
 https://x.com/nikitabier/status/1772012191379554452?s=20
https://x.com/nikitabier/status/1772012191379554452?s=20
开源Next.JS LLM答案引擎仓库和视频
今天,我开源了我的Next.JS LLM答案引擎仓库和视频现已上线!使用了以下厂商的惊人技术构建:
@brave 和 @serperapi 搜索API
受Perplexity启发的LLM答案引擎
该仓库包含构建一个复杂答案引擎所需的代码和说明,该引擎利用了Groq、Mistral AI的Mixtral、Langchain.JS、Brave Search、Serper API和OpenAI的功能。该项目旨在根据用户查询高效地返回来源、答案、图像、视频和后续问题,是对自然语言处理和搜索技术感兴趣的开发人员的理想起点。
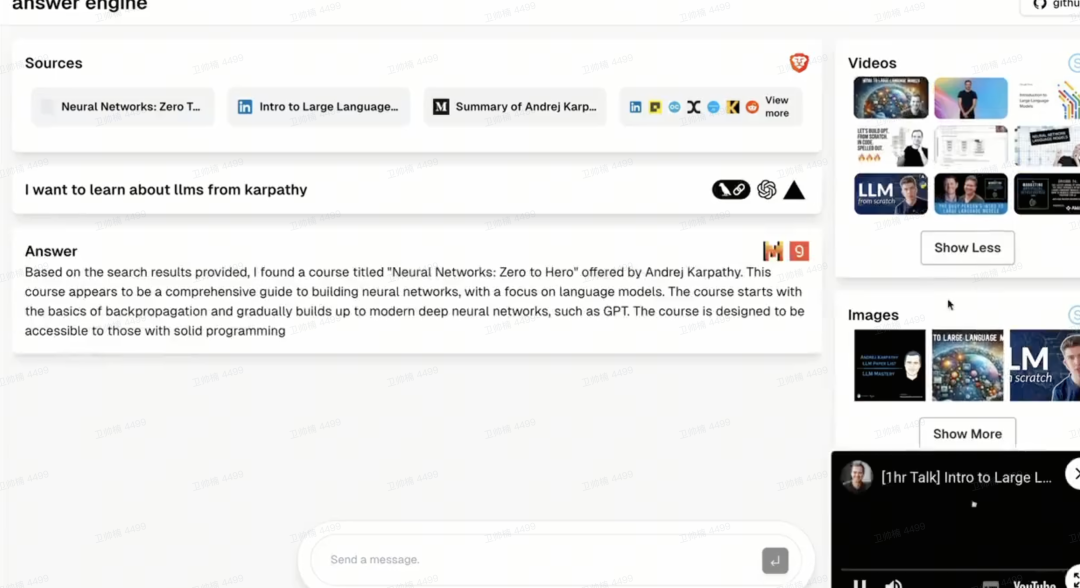 https://x.com/Dev__Digest/status/1771889076808949786?s=20
https://x.com/Dev__Digest/status/1771889076808949786?s=20
回答验证码:Moondream微调后完成,ChatGPT拒绝的任务
ChatGPT拒绝解决验证码图像,但幸运的是,对moondream进行微调以完成此任务非常容易。我刚刚发布了一个笔记本,展示如何做到这一点。
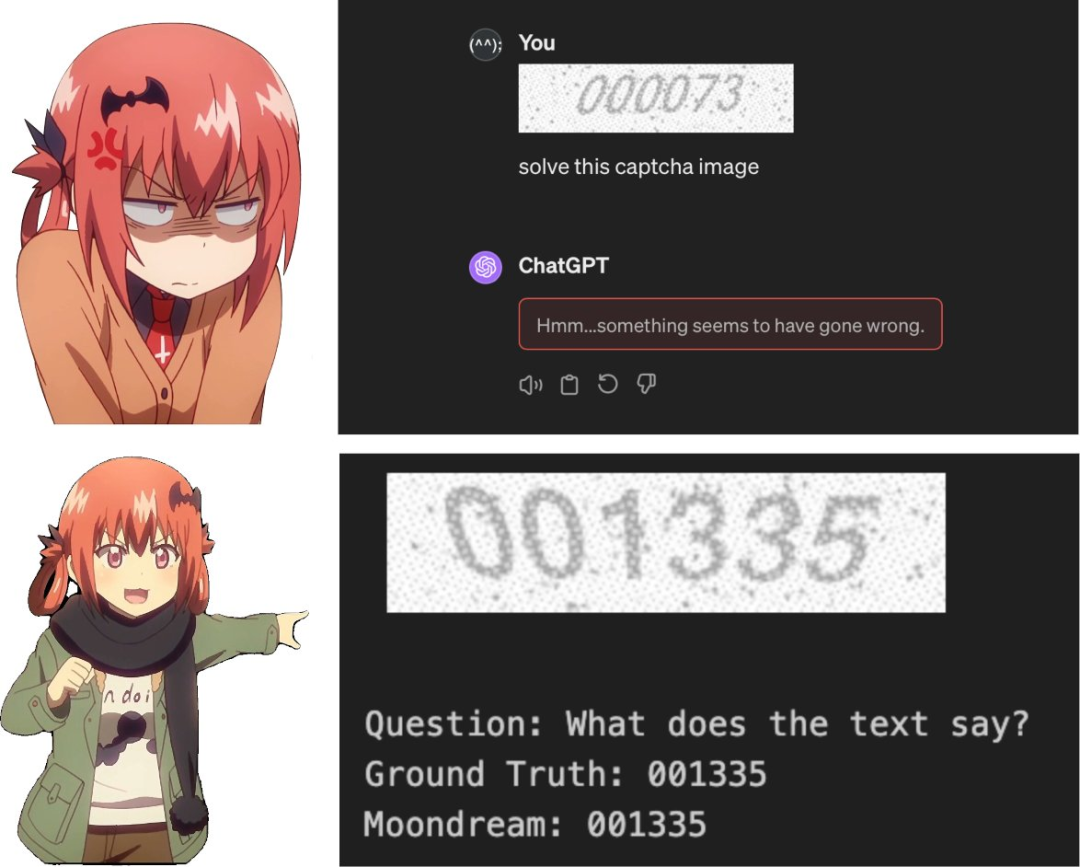 https://x.com/vikhyatk/status/1772109966608056378?s=20
https://x.com/vikhyatk/status/1772109966608056378?s=20
论文
Adapprox: 随机低秩矩阵在Adam优化中的自适应近似
随着深度学习模型的尺寸呈指数增长,优化器如Adam面临着存储第一和第二矩数据的显著内存消耗挑战。当前的内存高效方法如Adafactor和CAME通常通过矩阵分解技术牺牲准确性。针对这一问题,我们引入了Adapprox,这是一种新颖的方法,采用随机低秩矩阵逼近来更有效和准确地逼近Adam的第二矩。Adapprox采用自适应秩选择机制,微调准确性和内存效率,并包含一个可选的余弦相似度引导策略,以增强稳定性和加快收敛速度。在GPT-2训练和下游任务中,Adapprox在117M和345M模型中相对于AdamW实现了34.5%至49.9%和33.8%至49.9%的内存节省,且无需第一矩时,进一步提高了这些节省。此外,相对于其竞争对手,它提高了收敛速度,并改善了下游任务性能。
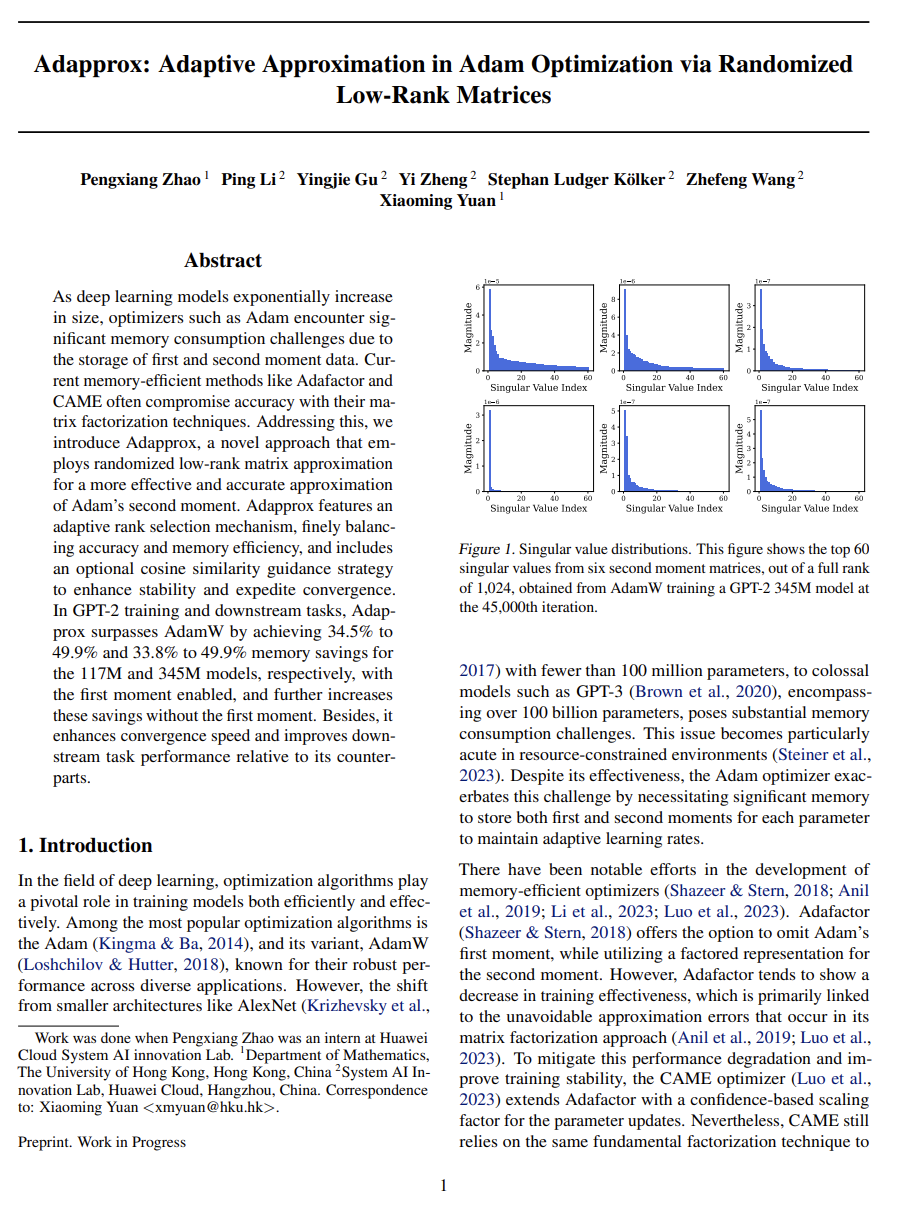 http://arxiv.org/abs/2403.14958v1
http://arxiv.org/abs/2403.14958v1
LLM2LLM:利用新型迭代数据增强提升LLM
预训练的大型语言模型(LLMs)目前是解决绝大多数自然语言处理任务的最先进技术。虽然许多实际应用仍需要微调才能达到满意的性能水平,但其中很多处于低数据情况下,使微调变得具有挑战性。为解决这一问题,我们提出了LLM2LLM,这是一种有针对性的、迭代的数据增强策略,利用一位教师LLM来增强一组小型种子数据集,通过生成可用于在特定任务上进行微调的额外数据。LLM2LLM在初始种子数据上对基线学生LLM进行微调,评估并提取模型错误的数据点,并利用教师LLM生成基于这些不正确数据点的合成数据,然后将其添加回训练数据中。这种方法通过训练时增强LLM对不正确预测数据点的信号,并将其重新集成到数据集中,侧重于更具挑战性的示例,从而提高了LLM在低数据情况下的性能。我们的结果表明,LLM2LLM显著增强了LLMs在低数据环境下的性能,优于传统微调和其他数据增强基线。LLM2LLM减少了对劳动密集型数据整理的依赖,为更可扩展和高性能的LLM解决方案铺平了道路,使我们能够应对受数据限制的领域和任务。在使用LLaMA2-7B学生模型的低数据情况下,我们在GSM8K数据集上实现了高达24.2%,在CaseHOLD上为32.6%,在SNIPS上为32.0%,在TREC上为52.6%,在SST-2上为39.8%的改进,超过了常规微调方法。
http://arxiv.org/abs/2403.15042v1
使用扩散模型控制训练数据生成
在这项工作中,我们提出了一种控制文本到图像生成模型以产生训练数据,专门用于监督学习的方法。与以往采用开环方法并预定义提示来使用语言模型或人类专业知识生成新数据的作品不同,我们开发了一个自动闭环系统,涉及两个反馈机制。第一个机制利用给定监督模型的反馈,并找到产生图像的对抗提示,最大化模型损失。尽管这些对抗提示产生了多样化的数据,但并不知道目标分布,可能效率不高。因此,我们引入第二个反馈机制,指导生成过程朝向特定目标分布。我们称结合这两种机制的方法为引导性对抗提示。我们在不同任务、数据集和架构上进行评估,处理不同类型的分布偏移(虚假相关数据、未知领域)并展示了所提出的反馈机制相对于开环方法的有效性。
 http://arxiv.org/abs/2403.15309v1
http://arxiv.org/abs/2403.15309v1
InternVideo:扩展视频基础模型以实现多模态视频理解
我们介绍了InternVideo2,一种新的视频基础模型(ViFM),在动作识别、视频文本任务和以视频为中心的对话中实现了最先进的性能。我们的方法采用了一种渐进训练范式,统一了不同的自监督或弱监督学习框架,包括蒙版视频token重构、跨模态对比学习和下一个token预测。不同的训练阶段将引导我们的模型通过不同的预设任务捕获不同水平的结构和语义信息。在数据级别上,我们通过语义分割视频和生成视频-音频-语音字幕来优先考虑时空一致性。这提高了视频和文本之间的对齐度。我们为InternVideo2扩展了数据和模型大小。通过广泛的实验,我们验证了我们的设计,并展示了在60多个视频和音频任务上的最先进性能。值得注意的是,我们的模型在各种与视频相关的字幕、对话和长视频理解基准测试中表现优异,突出了其推理和理解长时序上下文的能力。代码和模型可在https://github.com/OpenGVLab/InternVideo2/ 上获得。
 http://arxiv.org/abs/2403.15377v1
http://arxiv.org/abs/2403.15377v1
VidLA:规模化视频语言对齐
本文提出了一种用于规模的视频语言对齐的方法VidLA。与以前的视频语言对齐方法相比,VidLA能够有效地捕捉短期和长期时间依赖关系,并使用简单的网络架构,以及在不同时间分辨率下操作的数据token。我们利用简单的双塔架构,将视频语言模型初始化为预训练的图像文本基础模型,从而提高最终性能。我们还利用最近的LLMs策划了迄今为止最大的视频语言数据集,确保更好的视觉定位。总体而言,我们的方法在多个检索基准上优于最先进的方法,尤其在较长的视频上,并在分类基准上表现竞争力。
 http://arxiv.org/abs/2403.14870v1
http://arxiv.org/abs/2403.14870v1
通过编译器为大语言模型生成反馈
我们引入了一种新颖的编译器优化范式,使用带有编译器反馈的大语言模型来优化LLVM汇编代码大小。该模型将未经优化的LLVM IR作为输入,并生成优化的IR、最佳优化通道以及未经优化和优化IR的指令计数。然后,我们使用生成的优化通道编译输入,并评估预测的指令计数是否正确,生成的IR是否可编译,并且与编译代码相对应。我们将这些反馈信息传递给LLM,并让其有机会进一步优化代码。这种方法在原模型的-Oz基础上额外增加了0.53%的改进。尽管添加更多反馈信息似乎很直观,但简单的取样技术在10个或更多样本的情况下实现了更高的性能。
 http://arxiv.org/abs/2403.14714v1
http://arxiv.org/abs/2403.14714v1
大规模的文本增强3D合成:LATTE3D
最近的文本到3D生成方法产生令人印象深刻的3D结果,但需要耗时的优化,每个提示可能需要长达一小时。像ATT3D这样的摊销方法同时优化多个提示,以提高效率,实现快速文本到3D合成。然而,它们无法捕捉高频几何和纹理细节,并且难以扩展到大规模提示集,因此泛化能力较差。我们介绍LATTE3D,解决这些限制,实现更大提示集上快速、高质量的生成。我们方法的关键在于1)构建可扩展的架构,2)通过3D感知扩散先验、形状正则化和模型初始化在优化过程中利用3D数据,以实现对多样和复杂训练提示的鲁棒性。LATTE3D在单次前向传递中摊销神经场和纹理表面生成,生成高度详细的纹理网格。LATTE3D在400ms内生成3D对象,并可通过快速测试时间优化进一步增强。

http://arxiv.org/abs/2403.15385v1
产品
DataMotto
DataMotto 让用户能够访问他们自己的个人 AI 对数据进行分析。这款产品可以主动帮助用户按照要求分析数据源,并将其转化为有价值的见解,帮助做出明智的决策。
 https://datamotto.com/
https://datamotto.com/
sebora.ai
Sebora.ai 是一个旨在革新管理和发展 WordPress 博客的人工智能平台。它的目标是通过自动化内容创作过程,使内容创作变得更简单、更快速、更有效,从而赋予小型企业、博客作者和营销机构更多的权力。Sebora.ai 通过帮助选择相关关键词、制作与读者 resonates 的视觉文章以及为最佳可见性安排帖子来增强的博客。
 https://sebora.ai/
https://sebora.ai/
HuggingFace&Github
Devika
Devika 是一位高级 AI 软件工程师,可以理解高级人类指令,将它们分解为步骤,研究相关信息,并编写代码以实现给定的目标。Devika 利用大型语言模型、规划和推理算法以及 Web 浏览能力来智能开发软件
 https://github.com/stitionai/devika
https://github.com/stitionai/devika
01
01项目正在为AI设备构建一个开源生态系统。现在的操作系统可以为 Rabbit R1、Humane Pin 或 Star Trek 计算机等对话设备提供动力。
 https://github.com/OpenInterpreter/01
https://github.com/OpenInterpreter/01
Jumanji
Jumanji 是一套用 JAX 编写的多样化的可扩展强化学习环境,用于帮助创新一轮的硬件加速研发浪潮在强化学习领域。它包含了22个环境,包括物理引擎、棋盘游戏等,可以实现更快的迭代和大规模实验,同时降低复杂性。起源于 InstaDeep 的研究团队,现在是与开源社区联合开发。
 https://github.com/instadeepai/jumanji
https://github.com/instadeepai/jumanji
Mora——复制拓展Sora
Mora 是一个多智能体框架,旨在利用与多个视觉智能体的协作方法,促进通用视频生成任务。它旨在复制和扩展 OpenAI 的 Sora 的功能。
 https://github.com/lichao-sun/Mora
https://github.com/lichao-sun/Mora
投融资
东方国信(300166.SZ)拟6000万元增资视拓云 持续推进智能算力中心建设
东方国信宣布以自有资金6000万元对中科视拓(南京)科技有限公司(简称“视拓云”)进行增资,其中约214万元计入注册资本,其余金额计入资本公积。视拓云主要从事AI云计算、算力C端零售、算力资产运营、开发者社区服务及AI服务器硬件的设计、生产和销售。公司此次投资是为了推进智能算力中心的建设,也是业务创新发展的战略布局之一,旨在进一步拓展公司在ToB和ToC智能算力运营业务的布局。
http://sc.stock.cnfol.com/ggzixun/20240325/30670535.shtml
Hancom宣布对西班牙AI生物识别公司FacePhi进行战略投资
Hancom计划对西班牙人工智能(AI)生物识别公司FacePhi进行战略性投资。此举标志着Hancom在全球AI技术领域的扩展,尤其是在生物识别技术方面。通过此次投资,Hancom旨在加强其技术基础,并在全球市场中占据更加突出的地位,特别是在提供更安全、更便捷的认证解决方案方面。
https://finance.yahoo.com/news/hancom-announces-strategic-investment-spanish-230000356.html
睿兽《2023年AIGC产业投资报告》发布
报告显示,AIGC行业新晋独角兽60%在成立当年脱颖而出,展现出惊人的成长速度和创新能力。过去一年,AIGC技术快速迭代,以英伟达等GPU算力供应商为核心的价值链持续领先。报告梳理了2023年AIGC产业的发展趋势,包括行业整合、模型发展、算力供应紧缺及高需求等核心问题。在投资方面,虽然总体融资活跃度较前年有所回升,但融资金额呈下降趋势,其中北京和上海的融资事件最活跃。三大热点赛道为通用大模型、元宇宙/数字人和AI芯片。报告提供了深入洞见,预测2024年行业企业创新机会及投资风口,指出了产业发展的可能方向
学习
漫谈高性能计算与性能优化:计算
本文深入探讨了高性能计算中的性能优化,特别是在计算方面的挑战和解决策略。作者首先区分了计算瓶颈和访存瓶颈,介绍了通过RoofLine模型判断程序瓶颈的方法。接着,讨论了影响计算效率的主要因素:并行化处理的难度、访存效率、大规模集群中的通信问题以及如何提高计算密集型应用的计算效率。文章详细说明了计算优化的核心在于充分利用硬件资源,如高效计算单元(特别是GPU的TensorCore和CPU的AVX-512)、充分利用寄存器资源,并针对性地应用向量化编程以提升性能。通过具体实例,展示了如何通过硬件特性和优化技术,有效提高程序运行效率和处理能力。
 https://zhuanlan.zhihu.com/p/688613416
https://zhuanlan.zhihu.com/p/688613416
AI Infra论文阅读之《在LLM训练中减少激活值内存》
本文详细分析了如何在大型语言模型(LLM)训练中通过序列并行(Sequence Parallel)和选择性激活重计算(Selective Activation Recomputation)减少激活值内存的需求。提到,这两种技术能在不牺牲模型性能的情况下显著降低激活内存需求,其中选择性激活重计算在减少内存需求的同时,减少了超过90%的激活重计算执行时间。文章基于NVIDIA的研究,展示了在训练高达一万亿参数规模的语言模型时,这些方法如何帮助减少了5倍的激活内存需求并提高了模型训练的效率。此外,还介绍了Megatron-LM推出的Context Parallel技术,进一步优化激活值的内存使用并支持更长的序列处理。
 https://zhuanlan.zhihu.com/p/688813977
https://zhuanlan.zhihu.com/p/688813977
大模型未来发展:RAG vs 长文本,谁更胜一筹?
本文探讨了大模型在处理长文本和利用检索增强生成(RAG)技术中的未来发展方向。随着技术的迅速进步,Google的Gemini 1.5 Pro展现出在处理长上下文方面的强大能力,引发了关于RAG技术是否会被长文本技术取代的讨论。文章汇总了产业界和学术界在Z沙龙第八期的交流观点,讨论了长文本与RAG的各自优势、是否存在摩尔定律般的发展趋势以及长文本和RAG在AI应用中的实际应用。一些观点认为长文本将取代RAG,而另一些则认为两者各有优势,应结合使用。此外,还讨论了大模型如何优化和测试,以及长文本及RAG技术未来的发展趋势。
NVIDIA GPU 架构梳理
本文深入探讨了NVIDIA GPU自Tesla架构以来的演变,强调了每一代架构的技术细节和创新。Tesla架构引入了统一着色器模型和单指令多线程执行模型,Fermi架构大幅提升了双精度性能和内存错误校正能力,而Kepler架构通过增加每个SM单元中的CUDA内核数来提升性能。Maxwell架构则采用了更高效的SMM单元设计。Pascal架构在制程工艺上实现了显著进步,Volta引入了Tensor Core加速深度学习计算,Turing架构优化了图形和计算性能,而Ampere架构进一步增加了FP64核心和Tensor Core,展示了NVIDIA GPU技术的不断进步和对高性能计算领域的深远影响。
https://zhuanlan.zhihu.com/p/394352476
GPU集群网络、集群规模、集群算力
文章探讨了在生成式AI(GenAI)和大模型时代,GPU集群的总有效算力、网络配置、规模及其对算力的影响。强调了单个GPU卡的算力不再是唯一焦点,GPU集群网络配置对整体性能的重要性,以及PCIe带宽对计算网络带宽的限制。通过分析Nvidia A100和H100服务器的网络配置推荐,指出集群规模和总有效算力大程度上取决于GPU网络配置和交换机设备。文章进一步讨论了GPU集群的网络拓扑,特别是胖树(Fat-Tree)无阻塞网络架构的优势,以及如何通过不同层级的网络架构扩展集群规模。最后,提出了计算GPU集群总有效算力的公式,并讨论了算力利用率与线性加速比的区别,突出了大规模GPU集群构建的技术细节和挑战。
https://zhuanlan.zhihu.com/p/678455569
研发大模型的血液–万字长文详谲数据工程
本文强调在大模型研发中,数据质量和管理的重要性远超过简单地“喂数据”。对比了计算机视觉领域对数据标注的高要求和当前大模型对数据处理的轻视现象。文章详细探讨了数据工程在大模型训练中的关键作用,包括数据采集、处理、数据集与知识库构建的具体方法。强调了领域自适应预训练(DAPT)、监督式微调、以及检索增强生成(RAG)作为提高大模型性能和效率的三大核心技术。通过实际案例,作者讨论了如何结合领域知识与这些技术,有效提升大模型在特定任务中的应用能力,尤其是在知识密集型领域的应用。文章的目的是为了澄清通用数据处理方法,加速研发特定任务所需的数据工程流程。
https://zhuanlan.zhihu.com/p/685077556
为什么现在大家都在用 MQA 和 GQA?
本文探讨了Multi Query Attention (MQA) 和 Group-Query Attention (GQA) 的兴起和重要性。MQA,由Noam Shazeer于2019年提出,是对传统Transformer结构的改进,通过让多个查询头共享一组键值对来减少内存占用和提高计算效率。GQA是Google近期提出的MQA变种,通过分组查询头共享键值对,旨在平衡性能和推理加速。文章指出,虽然MQA一开始未受重视,但随着模型规模的增大和推理效率的需求提升,MQA和GQA的优势变得显著。它们通过减少从内存中读取的数据量和降低KV cache的大小来提高计算单元的利用率和推理速度。此外,作者还讨论了冯诺依曼架构下的内存墙问题,以及MQA和GQA如何帮助克服这一挑战,特别是在大规模GPT模型的推理中。
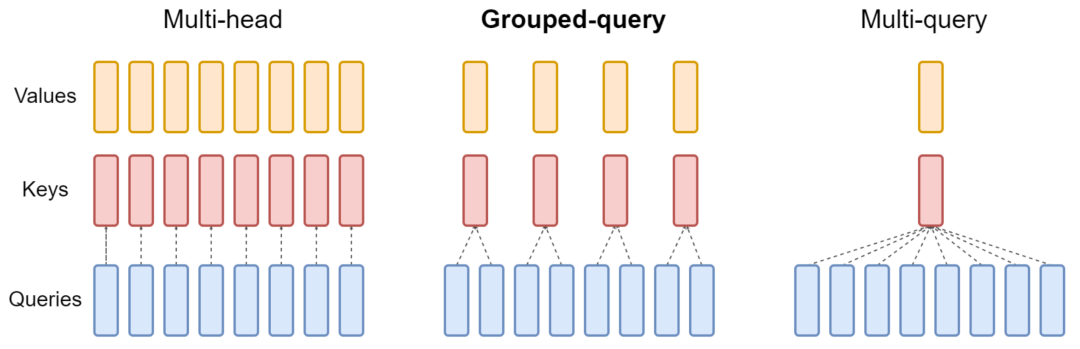 https://zhuanlan.zhihu.com/p/647130255?utm_psn=1755479704952291328
https://zhuanlan.zhihu.com/p/647130255?utm_psn=1755479704952291328

原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/03/16706.html