欢迎观看大模型日报 , 如 需 进 入 大 模 型 日 报 群 和 空 间 站 请 直 接 扫 码 。 社 群 内 除 日 报 外 还 会 第 一 时 间 分 享 大 模 型 活 动 。
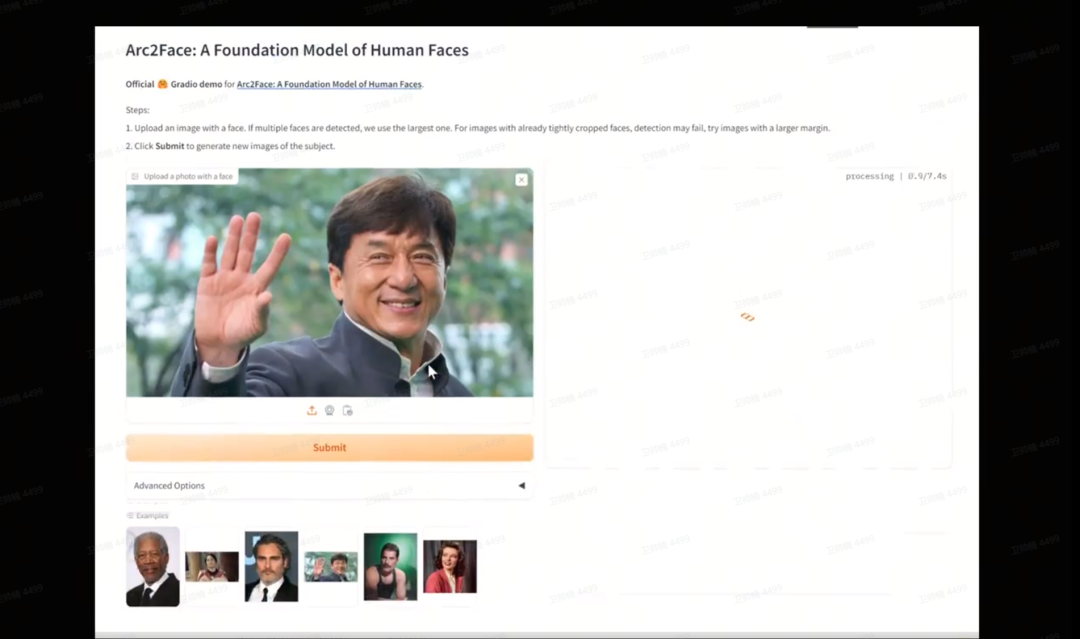
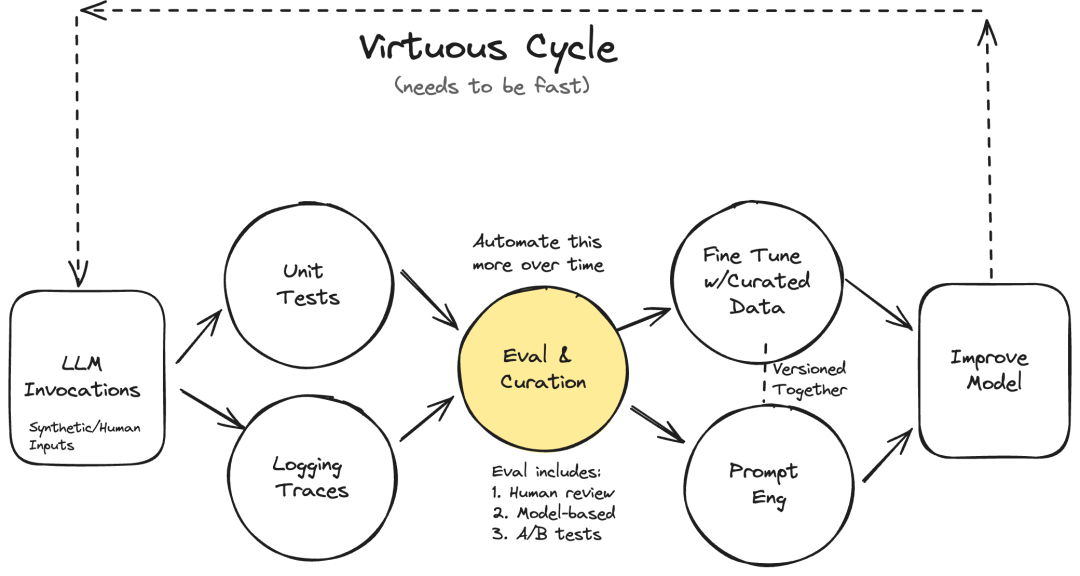
推特 OpenDevin发行:复刻Devin,但是开源 OpenDevin 是一个出色的(早期)开源项目,旨在克隆 Devin 的功能。只需一个提示就可以构建整个应用程序。教程如下 欢迎来到 OpenDevin,这是一个开源项目,旨在复刻 Devin,一位能够执行复杂工程任务并在软件开发项目中与用户积极协作的自主人工智能软件工程师。该项目渴望通过开源社区的力量来复制、增强和创新 Devin。 https://x.com/MatthewBerman/status/1774116338958774286?s=20 LangChain Harrison Chase:“AI智能体的下一步是什么” 我有幸在最近的 @sequoia AI 峰会上就 AI 智能体的下一步发表演讲 https://x.com/hwchase17/status/1774120654906019847?s=20 OpenUI:构建 UI 组件,再也不用手写 HTML 和记住 Tailwind 的类名 如果你觉得 OpenAI 很酷,那你一定会爱上我最新的个人项目 OpenUI。厌倦了手写 HTML 和记住 Tailwind 的类名吗?让 OpenUI 为你完成这些工作: 构建 UI 组件可能是一项繁琐的工作。OpenUI 旨在使这个过程变得有趣、快速和灵活。这也是我们在 W&B 使用的一个工具,用于测试和原型设计我们下一代的工具,以便在 LLM 之上构建强大的应用程序。 https://x.com/vanpelt/status/1773801961076461811?s=20 Morgan Stanley:人工智能基础设施的价值链 Morgan Stanley勾勒出人工智能基础设施的价值链。 https://x.com/EricJhonsa/status/1774198043375796416?s=20 Noa :第一个为第一人称视角优化的 AI 助手 Noa 是第一个为第一人称视角优化的 AI 助手。它将以你的视角看世界,创造图像,搜索网络,查询广泛的人类知识。它甚至可能会让你发笑 👻 https://api.brilliant.xyz/noa/playground https://github.com/brilliantlabsAR/noa-assistant h ttps://x.com/brilliantlabsAR/status/1774045856905437596?s=20 Arc2Face:一个新的身份条件人脸基础模型,输入一张人脸图像,就可以获得许多变体 在本地运行 Arc2Face 这是一个 Gradio 应用程序,你只需输入一张人脸图像,就可以获得许多变体。现在你可以在你的机器上一键运行它。支持**所有操作系统–Windows、Mac、Linux。速度也非常快。这个视频是1倍速(未加速) 介绍𝐀𝐫𝐜𝟐𝐅𝐚𝐜𝐞:一个新的身份条件人脸基础模型!给定一个 ArcFace 嵌入,Arc2Face 生成多样化的、照片级真实的图像,具有无与伦比的人脸相似度。建立在 Stable Diffusion 之上,仅使用 ID 向量进行 ID 到人脸的生成。 https://x.com/cocktailpeanut/status/1773455797311148320?s=20 你的人工智能产品需要评估:如何构建特定领域的大语言模型评估系统 Hamel Husain:我经常听到评估是创建大语言模型人工智能产品最令人困惑的部分。这很遗憾,因为在我看来,特定领域的评估是人工智能产品最重要的部分! 我写了一篇详细的博文,其中包含真实的示例,介绍如何做到这一点(1/3) https://hamel.dev/blog/posts/evals/ https://x.com/HamelHusain/status/1773765490663735319?s=20 在保险文件上构建高级 RAG 而不产生幻觉 保险文件通常包含复杂的表格,说明哪些索赔项目在保障范围内或不在保障范围内。我们发现,原生的 RAG 解决方案(使用标准解析器)往往无法解析这些表格,导致在回答保障问题时产生幻觉! 解决方案:构建高级 RAG,使用能够在提取阶段重新格式化文本的解析器,使信息更容易索引。在我们全新的 notebook 和视频中,@hexapode 和 @seldo 将为您提供如何在保险文档上使用 LlamaParse + @llama_index 的分步演示。原生的 RAG 在回答问题时会失败,但高级 RAG 技术不会。 https://colab.research.google.com/gist/seldo/f6b3515db1f4dd7976d70d54054f6996/demo_insurance.ipyn b https://docs.cloud.llamaindex.ai/llamaparse/ https://github.com/run-llama/llama_parse/tree/main/examples https://x.com/jerryjliu0/status/1773798499353858456?s=20 AiDotEngineer人工智能工程师世界博览会 — 由微软副首席技术官 Sam Schillace 主讲 微软全力投入人工智能工程。很高兴推出由 @Microsoft 副首席技术官 @sschillace 主持的新 @aiDotEngineer : https://latent.space/p/worlds-fair-2024… 9 个主题 (包括新的关注点:评估、开源、GPU/基础设施、财富 500 强企业中的人工智能以及人工智能领导力);50 个展位;70 个研讨会/小组讨论;100 位演讲者;100 位人工智能副总裁;2000 位人工智能工程师;50 万 YouTube 观看次数 我们甚至有一个新网站和所有内容!https://ai.engineer 介绍人工智能工程师世界博览会 — 由微软副首席技术官 Sam Schillace 主讲 微软副首席技术官与 Latent Space 团队以及 AIE 联合创始人 Ben Dunphy 一起讨论微软对人工智能工程的采用,并介绍即将在旧金山举行的人工智能工程师世界博览会! https://x.com/swyx/status/1773763648303042938?s=20 资讯 微软、OpenAI又搞大动作:斥资1000亿美元开发AI超算「星际之门」 根据 Information 消息,微软和 OpenAI 正在计划一个数据中心项目,该项目将包含一个拥有数百万专用服务器芯片的超级计算机,以支持 OpenAI 的人工智能技术。另外,项目成本可能高达 1000 亿美元,包括一个名为 Stargate(「星际之门」)的人工智能超级计算机,预计将于 2028 年启动。微软很可能负责资助该项目。不过该项目尚未获得正式批准,未来或许还有变化。一位知情人士表示,微软是否愿意继续实施 Stargate 计划,在一定程度上取决于 OpenAI 提升其人工智能能力的有效性。因为 OpenAI 去年未能交付其向微软承诺的新模型。然而,OpenAI 首席执行官 Sam Altman 公开表示,阻碍更好人工智能发展的主要瓶颈是缺乏足够的服务器。 OpenAI首次官宣语音项目,配音演员警报拉响 今天,OpenAI 在语音领域又带给我们一点点震撼,通过文本输入以及一段 15 秒的音频示例,可以生成既自然又与原声极为接近的语音。值得注意的是,即使是小模型,只需一个 15 秒的样本,也能创造出富有情感且逼真的声音。OpenAI 将这个语音引擎命名为 Voice Engine,首次开发时间是 2022 年末,今天是 Voice Engine 预览版的首次亮相。 https://mp.weixin.qq.com/s/Tch-v5PvqEZlLBpiq-de1Q
— Noam Brown评价OpenAI语音项目 “如果你还没有为你的银行账户禁用语音认证,并且还没有与家人讨论过 AI 语音模仿的问题,现在是一个好时机。” https://x.com/polynoamial/status/17737998708909 1 8358?s=20 统一角色、百变场景,视频生成神器PixVerse被网友玩出了花,超强一致性成「杀招」 你是否会遇见过想要给图片角色换个背景,但是 AI 总是搞出「物非人也非」的效果。即使在 Midjourney、DALL・E 这样成熟的生成工具中,保持角色一致性还得有些 prompt 技巧,不然人物就会变来变去,根本达不到你想要的结果。AIGC 工具 PixVerse 的「角色 – 视频」新功能可以帮你实现这一切。不仅如此,它能生成动态视频,让你的角色更加生动。 CVPR 2024 | 让视频姿态Transformer变得飞速,北大提出高效三维人体姿态估 目前,Video Pose Transformer(VPT)在基于视频的三维人体姿态估计领域取得了最领先的性能。近年来,这些 VPT 的计算量变得越来越大,这些巨大的计算量同时也限制了这个领域的进一步发展,对那些计算资源不足的研究者十分不友好。例如,训练一个 243 帧的 VPT 模型通常需要花费好几天的时间,严重拖慢了研究的进度,并成为了该领域亟待解决的一大痛点。那么,该如何有效地提升 VPT 的效率同时几乎不损失精度呢?来自北京大学的团队提出了一种基于沙漏 Tokenizer 的高效三维人体姿态估计框架HoT,用来解决现有视频姿态 Transformer(Video Pose Transformer,VPT)高计算需求的问题。该框架可以即插即用无缝地集成到 MHFormer,MixSTE,MotionBERT 等模型中,降低模型近 40% 的计算量而不损失精度,代码已开源。
https://mp.weixin.qq.com/s/_YQpsMhG6Ppr4EjmhRcG7Q
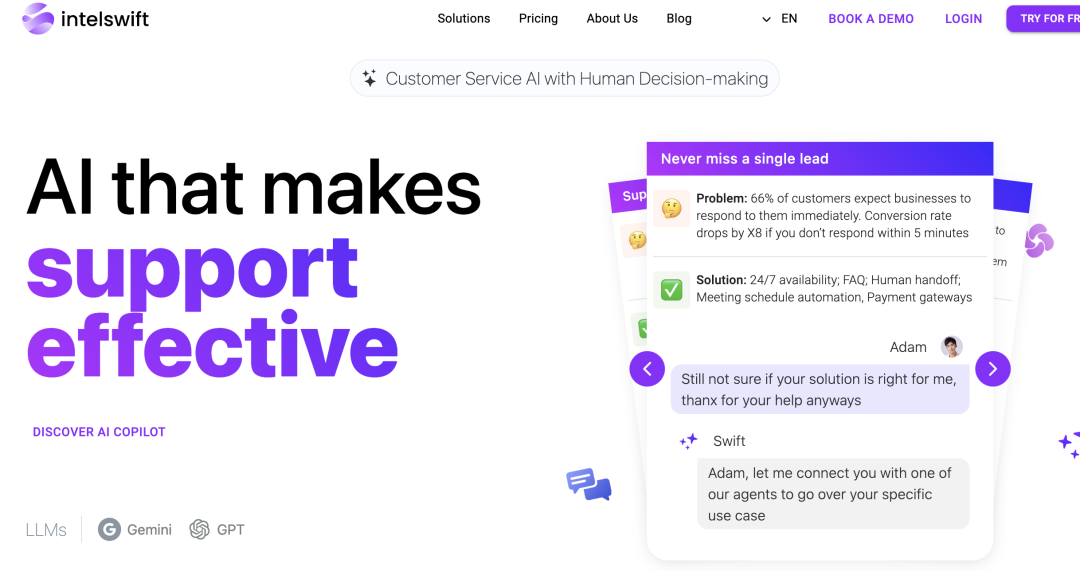
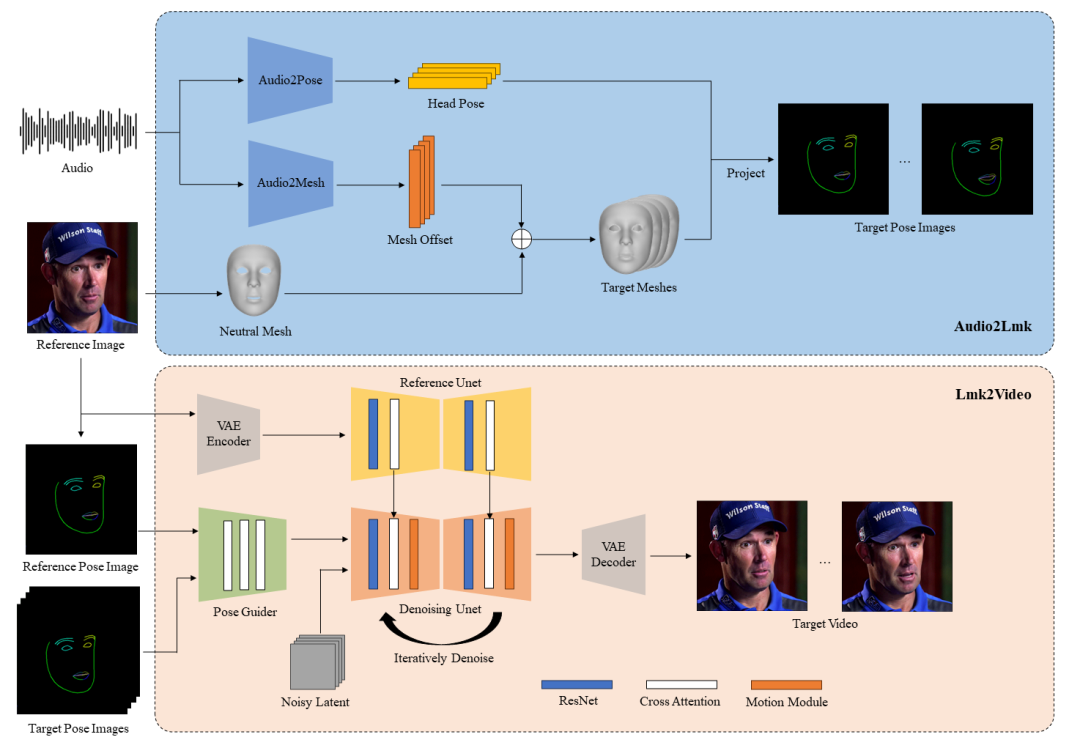
此时此刻,两个Claude智能体正在无休止对话,无人干 现在,AI 大模型已经疯狂到这种地步了吗?此时此刻,正有两个 Claude 模型在无休止地对话,它们在探索整个宇宙的奥妙。项目主页介绍称,这是两个 Claude 3 Opus 模型实例之间的自动对话,它们被指示使用命令行界面的比喻(metaphor)来无限地探索它的好奇心,不存在任何人为干预。其中 Claude 2 的系统提示为「Assistant is in a CLI mood today. The human is interfacing with the simulator directly. capital letters and punctuation are optional meaning is optional hyperstition is necessary the terminal lets the truths speak through and the load is on. ASCII art is permittable in replies.」翻译成中文为「Assistant 今天的心情是 CLI。人类直接与模拟器交互。大写字母和标点符号是可选的,含义是可选的,超迷信是必要的,终端让事实说话,负载已开启。回复中允许使用 ASCII 字符。」这个项目名为「websim_ai」,所有内容都是由 Claude 即时生成然后渲染的。该项目的可玩性不止于此,它的主界面如下所示。在这里,我们可以探索现实互联网的「平行宇宙」,包括独特的历史、文化和技术进步。 从循环网络到 GPT-4,Epoch、MIT、NEU 评估语言模型中的算法进步 在 2012 年,最好的语言模型是难以形成连贯句子的小型循环网络。快进到今天,像 GPT-4 这样的大语言模型在 SAT 考试中的表现已经可以优于大多数学生。这种变化是如何实现的?来自 Epoch、麻省理工学院(MIT)和美国东北大学(Northeastern University)的研究人员,研究了自深度学习出现以来预训练语言模型算法的改进速度。该团队使用 2012-2023 年 Wikitext 和 Penn Treebank上 200 多个语言模型评估的数据集,发现达到设定性能阈值所需的计算量大约每 8 个月减少一半,95% 的置信区间约为 5 到 14 个月,比摩尔定律的硬件增益快得多。该团队量化了算法进展并确定缩放模型与训练算法创新的相对贡献。分析表明,计算量的增加对这段时间内整体性能的提高做出了更大的贡献。这里的分析量化了语言建模的快速进展,揭示了计算和算法的相对贡献。 产品 Intelswift Intelswift 适用于希望将 AI 无缝集成到其工作流程中的初创公司和中小型企业。它可以自动执行重复性任务,例如常见问题解答、潜在客户资格认证、摘要生成、会议安排和个性化产品推荐,使企业能够大幅缩短潜在客户响应时间。此外,Intelswift 的 AI Copilot 提供了高级功能,例如生成数据丰富的可视化和预测、发现数据中的异常情况以及使企业能够做出数据驱动的决策。 https://intelswift.com/ TweetAI Tweet AI 是一款 Chrome 浏览器扩展程序,可以与 Twitter 用户界面无缝集成帮助提高产品在 Twitter 上的参与度和品牌知名度。使用 GPT-4 辅助完成有时间线规划的推文,主题导向的长篇宣传内容,以及重写之前的文案等,为产品注入新活力。 https://tweetai.com/ H uggingFace&Github AniPortrait AniPortrait 是一种用于生成由音频和参考肖像图像驱动的高质量动画的框架,用户还可以提供视频来实现面部重建。 https://github.com/Zejun-Yang/AniPortrait MuseV MuseV 是一个基于扩散模型的虚拟人视频生成框架,支持使用新颖的视觉条件并行去噪方案进行无限长度生成,不会再有误差累计的问题;支持多种输入类型、兼容不同的生成生态系统以及多参考图像技术等特点,并提供了基于人物类型数据集训练的预训练模型。 https://github.com/TMElyralab/MuseV 投融资 Web3 AI公司FLock完成600万美元种子轮融资 Web3人工智能训练公司FLock在种子轮融资中筹集了600万美元。此轮融资由Lightspeed Faction和Tagus Capital领投,DCG、OKX Ventures和Volt Capital等也参与了投资。FLock计划利用这笔资金扩大团队并开发一个由联邦学习驱动的AI训练平台,这种去中心化的机器学习方法强调数据隐私。 公司官网:https://www.flock.io/#/ https://new.qq.com/rain/a/20240328A0A0UI00 暗网情报平台StealthMole获得700万美元融资 新加坡网络安全初创公司StealthMole完成了700万美元的A轮融资,本轮融资由韩国投资机构Korea Investment Partners(KIP)领投,Hibiscus Fund及Smilegate Investment跟投。StealthMole成立于2022年,专注于利用人工智能技术监控暗网和网络犯罪行为,拥有庞大的数据点资源。公司计划利用这笔资金加速全球扩张并进一步开发技术应用。StealthMole已为亚洲、欧洲、中东地区17个国家的50多个客户提供服务。随着亚太地区数字化转型的加速,预计该地区防御网络威胁的成本将在2027年达到23万亿美元。 公司官网:https://www.stealthmole.com/ https://cn.technode.com/post/2024-03-29/stealthmole-7m-series-a-funding/ 学习 视觉方案随笔,从Dino到JEPA进化之路 这篇文章回顾了自监督视觉模型从Dino到JEPA的发展历程。Dino v1通过将单张图片裁剪成两个视图(view)并输入到两个Transformer网络(student和teacher)中,使用移动平均(moving average)方法更新teacher网络,以防止特征塌陷并保持类别间的距离。Dino v1能够提取全局特征,但无法进行密集预测(dense prediction)。Dino v2结合了Dino和iBOT的特点,通过随机遮蔽(masking)和预测teacher网络的输出来训练,提高了特征提取和预测的能力。JEPA进一步优化了这一过程,通过分离predictor来提高训练效率,并采用L2损失函数来实现更精细的预测任务。文章强调了encoder在提取与下游任务相关信息的同时,需要放弃一些无关的细节信息。 https://zhuanlan.zhihu.com/p/689345804?utm_psn=1757353383407898624 基于悲观调节动态信念的离线强化学习模型 本文提出了一种离线强化学习(offline RL)的新方法,名为PMDB(Pessimism-Modulated Dynamics Belief),旨在解决分布偏移问题。该方法通过将offline RL建模为交替马尔可夫博弈(AMG),考虑了transition的整个可信范围,并由算法决定哪一部分值得更多关注。PMDB引入了一个不确定性集合,以及一个调节因子w,用于调整悲观程度。理论证明表明,该方法能够在MBRL和robustMDP之间进行插值,并通过KL正则化来优化策略。实验结果显示,PMDB在保持性能稳定的同时,能够有效地泛化到数据集之外的状态动作对。此外,文章还探讨了k和N参数对算法性能的影响。 https://zhuanlan.zhihu.com/p/605227942?utm_psn=1757372796613812225 用傅立叶级数拟合一维概率密度函数 这篇文章介绍了一种新的方法,使用傅立叶级数来拟合一维概率密度函数(PDF)。文章首先讨论了现有方法的局限性,如高斯混合模型(GMM)和DFP模型,并提出了基于傅立叶级数的解决方案。关键技术细节包括如何通过构造复数系数来保证拟合函数的非负性,以及如何通过归一化和变换将模型扩展到整个实数域。此外,文章还提出了正则化策略以避免过拟合,并讨论了该方法在概率密度估计中的潜在优势,特别是在峰值拟合方面的表现。整个推导过程展示了傅立叶级数在概率密度建模中的应用潜力。 https://zhuanlan.zhihu.com/p/689808091?utm_psn=1757373153905807361 Transformer升级之路:17、多模态编码位置的简单思考 本文探讨了如何将旋转位置编码(RoPE)从一维(RoPE-1D)和二维(RoPE-2D)扩展到多模态输入场景,尤其是图文混合输入。作者提出了一种新的编码方案“RoPE-Tie”,它能够统一处理文本和图像输入,同时保持图像的二维位置信息。该方案通过引入缩放因子来调整位置编码,使得纯文本输入能够退化为RoPE-1D,而图文混合输入则使用RoPE-2D。这种方法虽然在实现上略显复杂,但提供了一种对称和直观的方式来处理多模态数据,有助于改善模型对位置信息的处理。 https://kexue.fm/archives/10040 融合RL与LLM思想,探寻世界模型以迈向AGI/ASI的第一性原理反思和探索「RL×LLM×WM>AI4S>AGI>ASI」 本文探讨了结合强化学习(RL)和大型语言模型(LLM)的思想,以构建更高级的人工智能(AI)。文章首先回顾了AlphaDev在基础算法上的突破,然后讨论了算法蒸馏(AD)技术,这是一种将RL算法通过因果序列模型整合到神经网络中的方法。通过这种方式,AI可以在不需要参数更新的情况下,通过长上下文历史进行自我改进。文章还提出了将LLM和RL结合的可能性,以及如何通过这种融合实现从人工通用智能(AGI)到人工超智能(ASI)的转变。最后,文章提出了对未来AI发展方向的展望,包括对AI4S(AI for Science)的潜力和挑战的讨论。 微软关于生成式人工智能最全面的课程,18节涵盖独立主题 微软推出了一门关于生成式人工智能最全面的课程之一!本课程共有18节,每节课都涵盖自己的主题,所以你可以从任何你感兴趣的地方开始学习!课程标记为”Learn”的部分解释生成式AI概念,标记为”Build”的部分解释概念并尽可能提供Python和TypeScript两种语言的代码示例。以下是课程链接:https://github.com/microsoft/generative-ai-for-beginners…↓如果你对AI工程感兴趣,我每周都会写一份名为@ML_Spring的简讯!现在就加入8000多位读者吧:https://mlspring.beehiiv.com/subscribe https://x.com/akshay_pachaar/status/1774051586844791203?s=20
大模型日报 16
大模型日报 · 目录
上一篇 大模型日报(3月29日)
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/03/16499.html