
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。

资讯
马斯克称将为 xAI 购买约 30 万块英伟达 AI 芯片,预估至少花费 90 亿美元
 https://www.ithome.com/0/772/818.htm
https://www.ithome.com/0/772/818.htmAMD 公布新一代AI芯片MI350系列,推理性能大幅增涨
 https://www.tmtpost.com/7113626.html
https://www.tmtpost.com/7113626.htmlStability Al 将在6 月 12 日 开放 Stable Diffusion 3 权重下载
 https://mp.weixin.qq.com/s/mG9L6mr21eS9g8vNBRfZLw
https://mp.weixin.qq.com/s/mG9L6mr21eS9g8vNBRfZLw清北爸爸李永乐都搞不定的事情,这个隐身的大模型在发起挑战
 https://mp.weixin.qq.com/s/ojHT_p4invctJkbuusGq_g
https://mp.weixin.qq.com/s/ojHT_p4invctJkbuusGq_g斯坦福爆火Llama3-V竟抄袭国内开源项目,作者火速删库
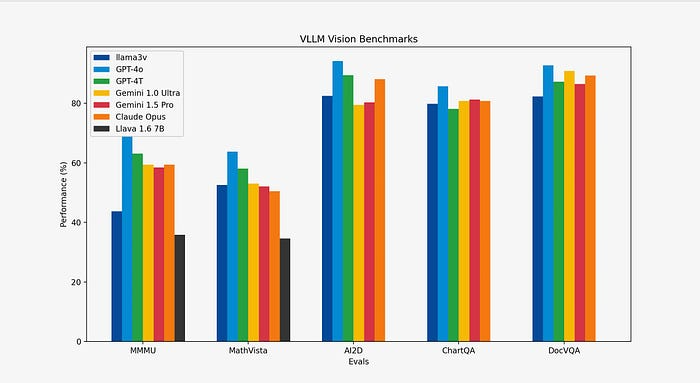 https://mp.weixin.qq.com/s/nsp9tdS5SnX-7htsndKVcw
https://mp.weixin.qq.com/s/nsp9tdS5SnX-7htsndKVcw不同数据集有不同的Scaling law?而你可用一个压缩算法来预测它
 https://mp.weixin.qq.com/s/sNQIe_jE30lciwP0uRhLEg
https://mp.weixin.qq.com/s/sNQIe_jE30lciwP0uRhLEg推特
Karpathy推荐FineWeb-Edu:高质量的LLM数据集,从原始的15万亿FineWeb标记过滤到1.3万亿最高(教育)质量的标记
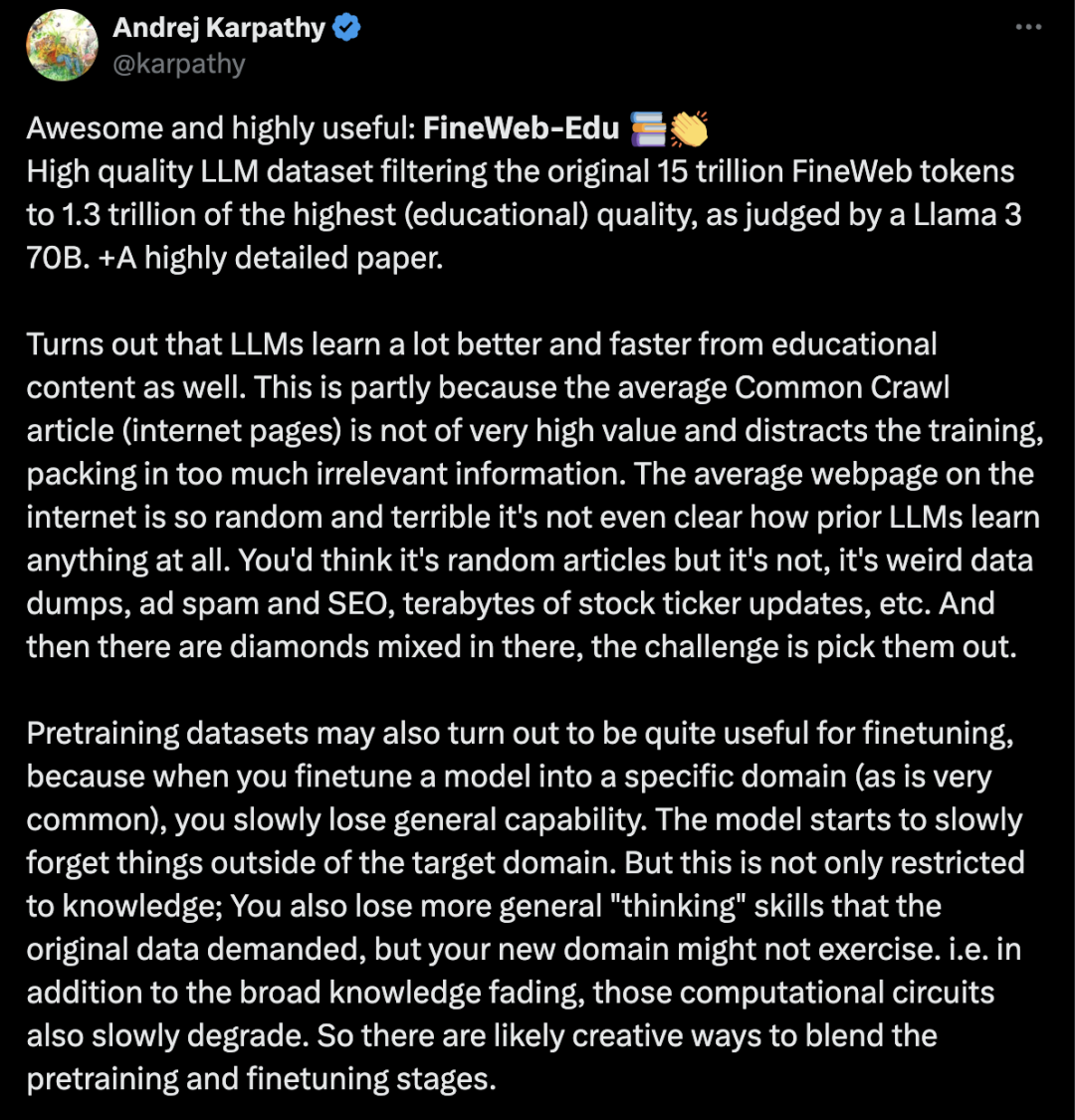 https://x.com/karpathy/status/1797313173449764933
https://x.com/karpathy/status/1797313173449764933Karpathy大神推特达100万粉丝,Jim Fan带头庆祝
 https://x.com/DrJimFan/status/1797344372754883063
https://x.com/DrJimFan/status/1797344372754883063真正利用AI来自动化枯燥的工作:Ben Tossell讨论AI自动化,Ben’s Bites,Makerpad,以及低/无代码AI
 https://x.com/OfficialLoganK/status/1797318660446400782
https://x.com/OfficialLoganK/status/1797318660446400782谷歌分享围绕任何学术论文创建类似NPR的讨论:科学传播的一些很酷的可能性
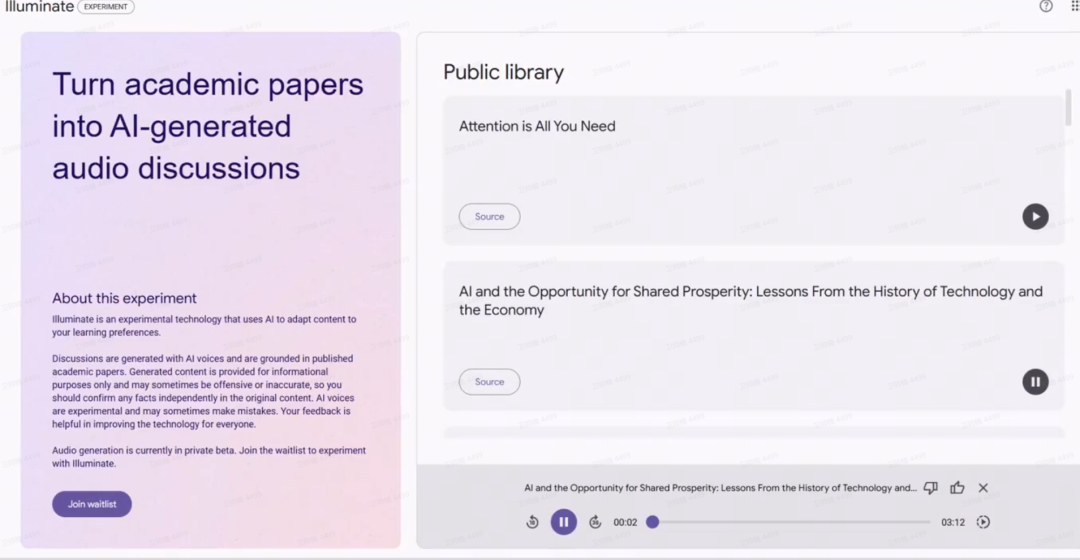 https://x.com/emollick/status/1797000655833350185
https://x.com/emollick/status/1797000655833350185
Ashpreet Bedi分享:AWS上使用LLM OS
-
使用gpt-4o作为协调不同资源的LLM -
使用@streamlit或@FastAPI进行服务 -
容器化以在Docker或ECS上运行
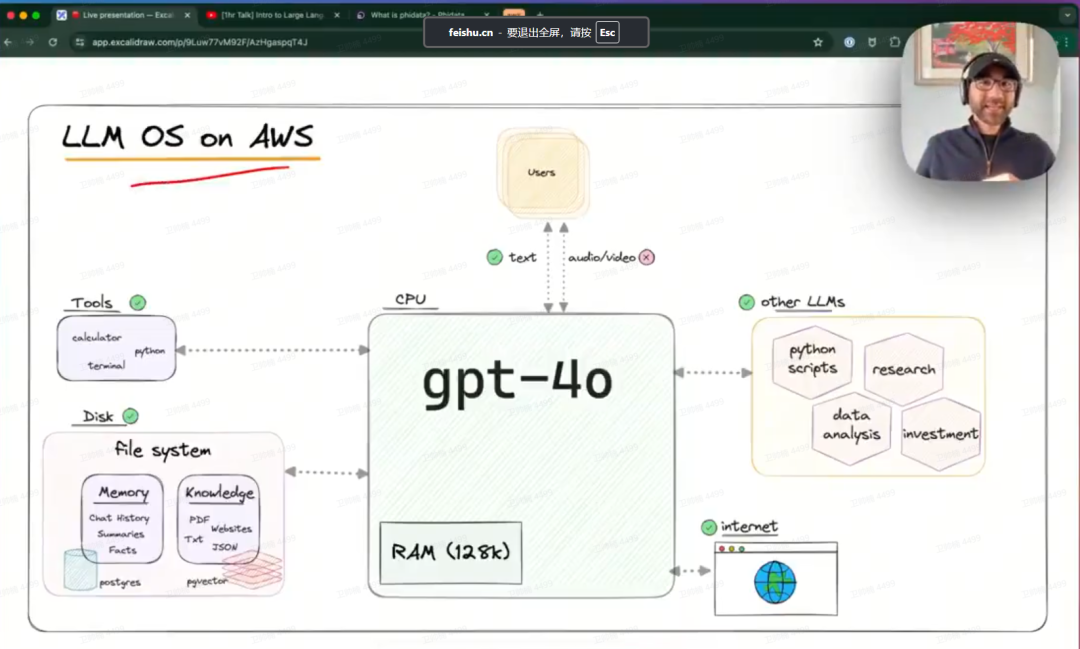 https://x.com/ashpreetbedi/status/1797320918274068700
https://x.com/ashpreetbedi/status/1797320918274068700
产品
rusher.ai
 https://rusher.ai/
https://rusher.ai/Rencoach
 https://rencoach.com/
https://rencoach.com/原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/06/14903.html
