我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。 如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
资讯 再战Transformer!原作者带队的Mamba 2来了,新架构训练效率大幅提升 自 2017 年被提出以来,Transformer 已经成为 AI 大模型的主流架构,一直稳居语言建模方面 C 位。但随着模型规模的扩展和需要处理的序列不断变长,Transformer 的局限性也逐渐凸显。一个很明显的缺陷是:Transformer 模型中自注意力机制的计算量会随着上下文长度的增加呈平方级增长。几个月前,Mamba的出现打破了这一局面,它可以随上下文长度的增加实现线性扩展。随着 Mamba 的发布,这些状态空间模型 (SSM) 在中小型规模上已经实现了与 Transformers 匹敌,甚至超越 Transformers。Mamba 的作者只有两位,一位是卡内基梅隆大学机器学习系助理教授 Albert Gu,另一位是 Together.AI 首席科学家、普林斯顿大学计算机科学助理教授 Tri Dao。Mamba 面世之后的这段时间里,社区反应热烈。可惜的是,Mamba 的论文却惨遭 ICLR 拒稿,让一众研究者颇感意外。仅仅六个月后,原作者带队,更强大的 Mamba 2 正式发布了。 多模态模型学会打扑克:表现超越GPT-4v,全新强化学习框架是关键 只用强化学习来微调,无需人类反馈,就能让多模态大模型学会做决策!这种方法得到的模型,已经学会了看图玩扑克、算“12点”等任务,表现甚至超越了GPT-4v。这是来自UC伯克利等高校最新提出的微调方法,研究阵容也是相当豪华:
图灵奖三巨头之一、Meta首席AI科学家、纽约大学教授LeCun
UC伯克利大牛、ALOHA团队成员Sergry Levine
ResNeXt()一作、Sora基础技术DiT作者谢赛宁
Oculus创始人帕尔默·拉奇宣称自己正在研发一款全新的头显设备 AWE USA 2024大会将于6月18日至6月20日在美国加州洛杉矶举行,而Oculus创始人帕尔默·拉奇日前宣布,他计划在本届活动正式宣布自己在研究的VR头显设备。 https://news.nweon.com/121452 Karpathy点赞,这份报告教你如何用 LLaMa 3创建高质量网络数据集 众所周知,对于 Llama3、GPT-4 或 Mixtral 等高性能大语言模型来说,构建高质量的网络规模数据集是非常重要的。然而,即使是最先进的开源 LLM 的预训练数据集也不公开,人们对其创建过程知之甚少。最近,AI 大牛 Andrej Karpathy推荐了一项名为 FineWeb-Edu 的工作。 单个4090可推理,2000亿稀疏大模型「天工MoE」开源 在大模型浪潮中,训练和部署最先进的密集 LLM 在计算需求和相关成本上带来了巨大挑战,尤其是在数百亿或数千亿参数的规模上。为了应对这些挑战,稀疏模型,如专家混合模型(MoE),已经变得越来越重要。这些模型通过将计算分配给各种专门的子模型或「专家」,提供了一种经济上更可行的替代方案,有可能以极低的资源需求达到甚至超过密集型模型的性能。6 月 3 日,开源大模型领域又传来重要消息:昆仑万维宣布开源 2 千亿稀疏大模型 Skywork-MoE,在保持性能强劲的同时,大幅降低了推理成本。Skywork-MoE 基于此前昆仑万维开源的 Skywork-13B 模型中间 checkpoint 扩展而来,是首个完整将 MoE Upcycling 技术应用并落地的开源千亿 MoE 大模型,也是首个支持用单台 4090 服务器推理的开源千亿 MoE 大模型。让大模型社区更为关注的是,Skywork-MoE 的模型权重、技术报告完全开源,免费商用,无需申请。 AI训练数据的版权保护:公地的悲剧还是合作的繁荣? GPT-4o内置声音模仿「寡姐」一案闹的沸沸扬扬,虽然以OpenAI发布声明暂停使用疑似寡姐声音的「SKY」的语音、否认曾侵权声音为阶段性结束。但是,一时间「即便是AI,也得保护人类版权」这一话题甚嚣尘上,更刺激起了人们本来就对AI是否可控这一现代迷思的焦虑。近日,普林斯顿大学、哥伦比亚大学、哈佛大学和宾夕法尼亚大学共同推出了一项关于生成式AI版权保护的新方案,题为《An Economic Solution to Copyright Challenges of Generative AI》。 华尔街盘点全球芯片战!市场规模将达 1 万亿美元 根据《华尔街日报》,随着全球芯片之争日益升级,到本世纪末,芯片行业的规模预计将翻一番,达到 1 万亿美元。各国政府加大力度,推动国内芯片生产,这些芯片为汽车、电子产品和人工智能等各行各业提供动力。全球各地的公司都在竞相加入这股热潮。据芯片行业咨询公司 International Business Strategies预测,到本世纪末,全球半导体收入预计将超过 1 万亿美元。 国内生产能力增强可能会使高度专业化的半导体供应链多样化,在某些地区,半导体供应链在某些工艺领域具有优势,而在其他领域则存在弱点。例如,美国公司在芯片设计的许多领域处于领先地位,而台湾、韩国和中国大陆的公司则在后期的生产和组装阶段占据主导地位。 推特 用任何声音制作歌曲:哼唱一首曲调,但要赋予它节奏布鲁斯。 用任何声音制作歌曲。即将推出 VOL-3:哼唱一首曲调,但要赋予它节奏布鲁斯(R&B)的感觉,由 Rebecca (Suno 产品经理)演唱。 https://x.com/suno_ai_/status/1797635285368680826
Tri Dao分享状态空间对偶理论框架:证明了许多线性注意力变体和状态空间模型是等价的 Tri Dao 和 Albert Gu 合作构建了一个丰富的状态空间对偶(State-Space Duality, SSD)理论框架,证明了许多线性注意力(linear attention)变体和状态空间模型(State-Space Models, SSMs)是等价的。由此产生的模型 Mamba-2 比 Mamba-1 更好、更快,并且在语言建模任务上与强大的 Transformer 架构相匹配。 SSD 理论通过与矩阵分解的联系,让我们可以为 SSM 推导出更快的算法,利用矩阵乘法作为基本运算。大多数 GPU 的浮点运算都是矩阵乘法,因此充分利用张量核心(tensor cores)对于提高运算速度至关重要。 SSD 还启发了 Mamba-2 模型的设计,引入了并行投影、头部结构,并绑定参数以创建”多输入 SSM”,类似于”多值注意力”或”分组值注意力”。 此外,SSD 使得将许多最初为 Transformer 开发的系统优化更容易应用到 SSM 中,例如: Mamba-2 的 SSD 层比 Mamba-1 中的关联扫描(associative scan)要快得多,使得增加状态维度和改善模型质量成为可能。在 3B 参数规模下训练 300B tokens 后,Mamba-2 超过了同等规模的 Mamba-1 和旧的 Transformers。 最近的模型如 Jamba 和 Zamba 通过添加一些注意力层来提高模型质量。研究发现,将 4-6 个注意力层与 Mamba-2 层混合,可以超过 Transformer++ 和纯 Mamba-2。这表明注意力机制和 SSM 是互补的。
如何在新硬件(如 H100)上优化 SSM 训练?
如果不再使用键值缓存(KV cache),推理过程会有什么变化?
总之,这项研究揭示了注意力机制和 SSM 之间的深层联系,为构建更快、更好的语言模型提供了新的思路。 https://x.com/tri_dao/status/1797650443218436165 Bilawal Sidhu分享:深入解析”将神经辐射场视频烘焙成沉浸式分层深度图像” 当苹果公司表示他们将推出 “空间媒体” 时,我真正期望的是这样的效果——具有六个自由度的 3D 视频。相反,Vision Pro 用户只得到了装在新瓶子里的旧酒(苹果的 MV-HEVC 格式中的 VR180 视频)。不过很巧的是,这里有一个基于 NeRF 的开源体积视频引擎,可以通过 WebXR 流式传输到 Vision Pro 和 Quest。哦,它也支持 Mac。这一切都来自一家名不见经传的公司 Lifecast(YC ’21)。 让我们来深入了解他们的新论文 “将神经辐射场视频烘焙成沉浸式分层深度图像”,该论文旨在证明在当今的硬件上,体积视频捕捉、编辑和回放是完全可能的。 中心方法:多视图视频 → NeRFs → LDIs 你也可以使用一个简单的 VR180 相机(例如佳能 R5C)或一个由 GoPro 组成的大球形相机来捕捉场景的 3D 视频,制作一些 NeRF,然后将其烘焙成基于分层深度图像(LDI)的视频格式。这有点像拿一个精心制作的雕塑(NeRF),然后创建一个简化的 3D 打印版本(LDI),它捕捉了原始作品的本质,但更易于分发和展示。根据论文,它是一个 3 层 LDI——这不是超高层数,但与平面立体相比仍然是一个相当大的飞跃。然而,作者坚持只使用 3 层的原因非常实用。 事实证明,你可以轻松地将 1920×1920 分辨率的 3×3 网格层打包成一个 5760×5760 的图像——这是大多数带有移动芯片的 VR 头显可以解码的最大分辨率视频。此外,论文使用等角(相对于等矩形)投影,这使得中心区域的像素密度与 “8K” 分辨率的 180° VR 视频相当。在我看来,这是一个相当不错的选择。 我对看到 “LDIs” 和 “等角投影” 被用来烘焙这些 4D 辐射场感到低调兴奋。大约在 2017-2020 年,我在谷歌的团队(@broxtronix 等人)使用完全相同的方法来实现光场视频和 YouTubeVR 上的高分辨率视频流。 4 年后的这篇论文与 Deep View Video 论文相比,速度提高了 238 倍,而且该流水线可以在单个 GPU 工作站上运行,而不是在谷歌数据中心运行,这一点非常疯狂。 在我看来,对于复杂的主题,视觉保真度还不够——例如,3 层只能让你达到一定程度。但这篇论文/流水线向我证明,在移动硬件上进行高分辨率体积视频流式传输绝对是可能的。像这样一个更简单的 3 层格式也可以使体积视频在现有工具如 Premiere/Resolve 中的编辑比我们预期的要容易得多。 https://x.com/bilawalsidhu/status/1797807189400104985
对话Near Protocol,Opentensor和SaharalabsAI:AI和Web3的交集 与我们一起探索 #AI 和 #Web3 的交集,参与一场由该领域的三位先驱者的对话。 @NEARProtocol | @ilblackdragon @opentensor | @const_reborn @SaharaLabsAI | @xiangrenNLP 在此注册:https://panteracapital.com/future-conference-calls/ https://x.com/PanteraCapital/status/1797657047162622306 ElevenLabs分享:将 Jensen Huang 精彩的 Computex 主题演讲的部分片段用 AI 配音成普通话 我们与 @nvidia 合作,通过将 Jensen Huang 精彩的 Computex 主题演讲的部分片段用 AI 配音成普通话,帮助他扩大了演讲的影响力。此外,我们很高兴能够合作,通过将我们高质量的 AI 语音引入 NVIDIA ACE NIM 微服务,为视频游戏创建动态的非玩家角色(NPC)。 阅读更多:https://elevenlabs.io/blog/nvidia-ace-at-computex/ https://x.com/elevenlabsio/status/1797655062350565433
Awni Hannun分享MLX教程:基础知识、神经网络、微调等 https://ml-explore.github.io/mlx/build/html/examples/linear_regression.html
神经网络,在 MNIST 上训练多层感知机(MLP):
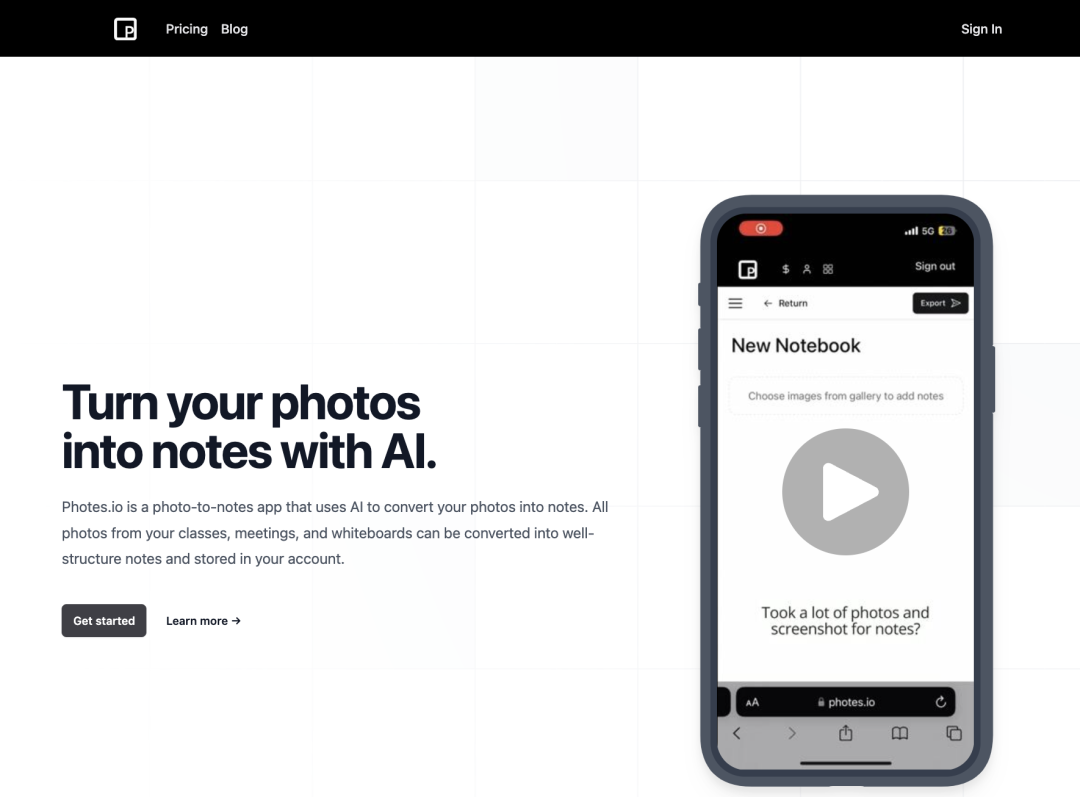
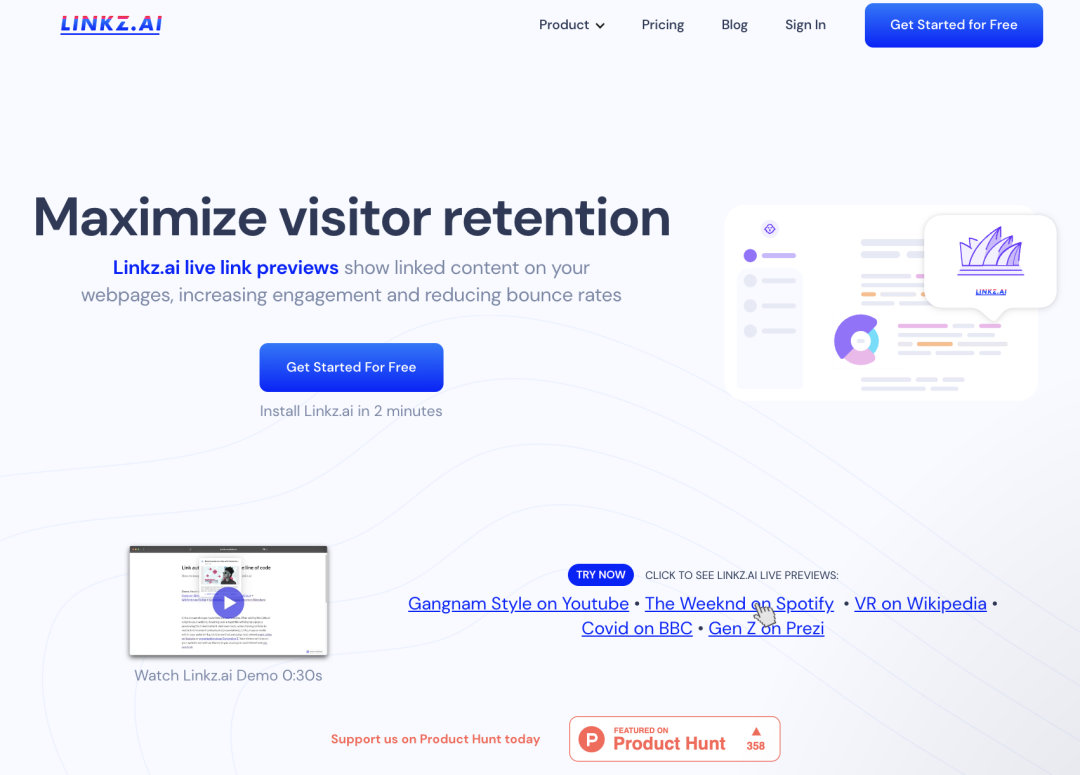
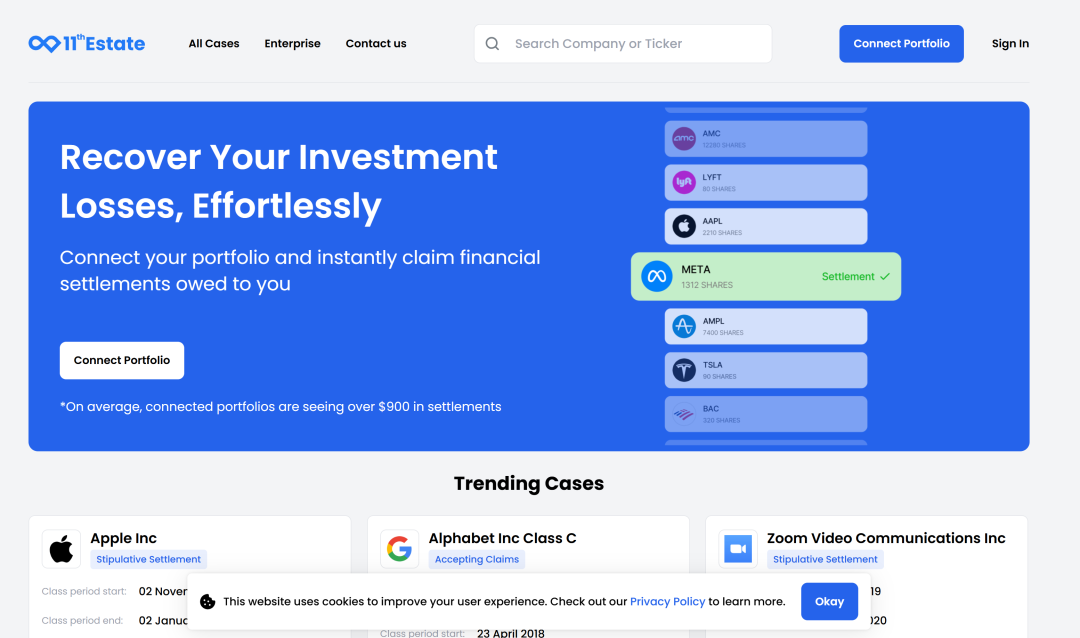
https://ml-explore.github.io/mlx/build/html/examples/mlp.html https://ml-explore.github.io/mlx/build/html/examples/llama-inference.html https://gist.github.com/awni/773e2a12079da40a1cbc566686c84c8f MLX 教程中还缺少什么?如果你有关于演练、教程或示例的想法,请告诉我。 https://x.com/awnihannun/status/1797750024639787045 产品 photes.io Photes.io 是一款基于 AI 技术的应用程序,能够将各种形式的照片(如课堂笔记、会议记录、白板截图等)快速转换为可编辑、组织有序的数字笔记。它不仅提供标签分类、跨设备同步等便捷功能,还注重数据安全和隐私保护,并支持自定义模板,为用户带来更个性化的数字笔记体验。 https://photes.io/ Linkz.AI Linkz.ai 是一个为网站和博客提供实时链接预览功能的工具。它可以在访客悬停在链接上时弹出预览框,展示链接内容的摘要,并直接在网页上显示视频、文章等内容,无需访客跳转离开网站。Linkz.ai 还提供链接预览的分析数据,以及可自定义的主题样式。通过这些功能,帮助网站提高访客的停留时间和交互,提升网站的整体用户体验。 https://linkz.ai/ 投融资 11thEstate 获得200万美元种子轮融资 11thEstate是一家总部位于纽约的平台,专注于帮助投资者在证券欺诈案件中获得赔偿。公司最近完成了一轮200万美元的种子融资。本轮融资由Social Leverage领投,其他参与者包括Outside Ventures、Blank Ventures以及天使投资人Evan Rapoport和Chris Camillo。Social Leverage专注于软件、消费品和金融科技领域的早期和种子期投资。随着此次投资,Social Leverage的Matt Ober将加入11thEstate的董事会。11thEstate计划利用这笔资金扩大运营规模,并在投资回收领域建立新的标准。 公司官网:https://11thestate.com/ https://www.thesaasnews.com/news/11thestate-raises-2-million-in-seed-round Caju AI 完成300万美元种子轮融资 Caju AI是一家位于弗吉尼亚州夏洛茨维尔的公司,提供生成式AI驱动的客户互动解决方案。公司近日完成了300万美元的种子轮融资。本轮融资由Grotech Ventures、Felton Group及夏洛茨维尔对冲基金经理Jaffray Woodriff的家族办公室领投,另有天使投资人参与。Caju AI计划利用这笔资金进一步推动公司的增长和创新。公司专注于生成式AI客户互动解决方案,能够安全捕获并分析客户在各种消息渠道中的交流,提供高级分析和可操作的商业智能。 公司官网:https://www.caju.ai/ https://www.thesaasnews.com/news/caju-ai-closes-3-million-in-seed-round Headout 收购 Dabble 打造AI体验 旅游活动平台Headout收购了Dabble,这是一家由Y Combinator支持的初创公司,致力于将数字世界与物理世界连接。Headout计划利用Dabble的技术能力,为用户打造新一代的AI驱动旅游体验。Dabble专注于计算机视觉、人工智能和空间计算,在游戏、室内导航和培训等领域开发应用。此次收购的条款未披露。Headout成立于2015年,提供全球125个城市的旅游体验,并已筹集超过6000万美元资金。 公司官网:https://www.dabble.so/ https://www.phocuswire.com/tour-activities-platform-headout-acquires-dabble-ai-experiences
— END —
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/06/14870.html