


AIGC系列分享是整数智能推出的一个全新分享系列,在这个系列中,我们将介绍与AIGC概念相关的有趣内容。AIGC系列主要分为以下几篇文章:
-
AIGC的数据集构建方案分享系列
-
从文本创建艺术,AI图像生成器的数据集是如何构建的 -
ChatGPT的数据集构建方案(敬请期待) -
未完待续……
最近,“AI绘画”吸引了很多人的目光,而“AI绘画”在近期取得如此巨大进展的原因之一得益于Stable Diffusion的开源。
 引自Imagen官网
引自Imagen官网
01 什么是文图生成技术
 文本描述:A small cabin on top of a snowy mountain in the style of Disney, artstation
文本描述:A small cabin on top of a snowy mountain in the style of Disney, artstation
文图生成技术的研究开始于2010年中期,伴随着深度学习技术的发展而进步。截至2023年2月,目前已知的最先进的文生图模型有:OpenAI的DALL-E2、Google的ImageGen和StableilityAI的Stable Diffusion。这些模型生成的图片已经开始接近真实照片以及人类所绘艺术作品的质量。
在深度学习兴起之前,搭建文本到图像模型的尝试仅限于通过排列现有的组件图像进行拼贴,例如从剪切画数据库中选择图像形成类似于拼贴画的图像。随着深度学习的发展,越来越多的机构提出基于深度学习的文生图模型。
2015年,由多伦多大学研究人员提出第一个现代化文生图模型:alignDRAW。它使用带有注意力机制的循环变分自动编码器来扩展之前的DRAW架构,使其能以文本序列作为输入。尽管alignDRAW生成的图片是模糊,不逼真的,但是该模型能够归纳出训练数据中没有的物体。并且可以适当地处理新的文本描述,例如:“停车标识在蓝天上飞”。这表明该模型在一定程度上可以理解语言描述,并生成新的东西,而不是仅仅在“回放”训练集中的数据。
 文本描述:停车标识在蓝天上飞,引自aligenDRAW论文
文本描述:停车标识在蓝天上飞,引自aligenDRAW论文

文本描述:穿着圣诞衣的企鹅
同年4月份,OpenAI宣布了新版本的DALL-E2,宣称它可以从文本描述中生成照片般逼真的图像。与DALL-E相比,DALL-E2在速度、图像质量、训练数据集以及语言理解能力都有了显著改进。不过有时候模型也会出现错误。比如DALL-E2就无法区分:“黄色的书和红色的花瓶”。
 文本描述:黄色的书和红色的花瓶,左边图片由Imagen生成,右边图片由DALL-E2生成,引自Imagen论文
文本描述:黄色的书和红色的花瓶,左边图片由Imagen生成,右边图片由DALL-E2生成,引自Imagen论文
2022年5月,Google推出Imagen。它是一种文本到图像(text-to-image)扩散模型(diffusion model),具有前所未有的逼真度和深度的语言理解。Imagen建立在大型Transformer语言模型理解文本语义的能力之上,依赖于扩散模型生成高保真的图像。Imagen表明了以下四点结论:
-
冻结大型预训练模型的文本编码器对于文本到图像任务非常有效 -
缩放预训练文本编码器的大小比缩放扩散模型的大小更重要 -
提出一种新的阈值扩散采样器,可以使用非常大的无分类器指导权重 -
引入了一种新的高效的U-Net架构,其计算效率更高,内存效率更高,收敛速度更快
 文本描述:A brain riding a rocketship heading towards the moon,引自Imagen官网
文本描述:A brain riding a rocketship heading towards the moon,引自Imagen官网 文图生成样例,引自Stable Diffusion论文
文图生成样例,引自Stable Diffusion论文同年11月,OpenAI发布了Stable Diffusion 2.0。与最初的v1版本相比,Stable Diffusion 2.0版本使用全新的文本编码器(OpenCLIP)训练文本到图像模型,这大大提高了生成图像的质量。此版本的文生图模型可以生成默认分辨率为512×512像素以及768×768像素的图像。此外,该模型在LAION-Aesthetics(LAION-5B的美学子集)进行训练。与v1版本不同的是,v2版本使用LAION的NSFW(色情和性内容过滤器)过滤掉了数据集中的成人内容。
 文本描述:一只戴墨镜的兔子
文本描述:一只戴墨镜的兔子
 左图:128×128低分辨率的图片,右图:512×512高分辨率的图片,引自Stable Diffusion 2.0官网
左图:128×128低分辨率的图片,右图:512×512高分辨率的图片,引自Stable Diffusion 2.0官网
除了完成基本的文生图任务、超分辨率任务之外,Stable Diffusion 2.0还可以玩转很多其他任务。比如Stable Diffusion 2.0 在v1版本图像到图像(image-to-image)的特性之上,提出深度引导的稳定扩散模型(depth-guided stable diffusion):depth2img。它使用现有模型推断输入图像的深度,然后使用文本和深度信息生成新的图像。
 depth2img,引自Stable Diffusion 2.0官网
depth2img,引自Stable Diffusion 2.0官网
此外,Stability AI团队在Stable Diffusion 2.0的基础上提出一个新的文本引导的图像模型。这可以智能且快速地切换图像中的部分内容。
 图像修补模型生成的图像,引自Stable Diffusion 2.0官网
图像修补模型生成的图像,引自Stable Diffusion 2.0官网
同年12月,OpenAI发布了Stable Diffusion 2.1版本(公司效率不可谓不高),主要作了以下3点提升。
-
调整过滤器,增加数据量:在2.0版本中,为了防止色情内容和名人肖像的滥用,Stability AI使用LAION的NSFW(色情和性内容过滤器),过滤了成人内容。但是,该过滤器过于保守,这导致一些模棱两可的图像惨遭“和谐”,这减少模型训练数据集中的人物数量。因此,2.1版本调整了过滤器(可以涩涩,但仍然去除绝大多数涩涩内容)
-
加强非标准分辨率图像渲染:该版本的模型显著提升了建筑、室内设计、野生动物和景观场景方面的图像质量,可以为用户提供美丽的远景和史诗般的宽屏图像
-
加强反向提示词:它允许用户告诉模型不生成什么,用于消除不需要的细节,使得生成的图像更加精致
 文本描述:A mecha robot in a favela in expressionist style,左图:v1.0版本,右图v2.1版本
文本描述:A mecha robot in a favela in expressionist style,左图:v1.0版本,右图v2.1版本
在大致了解文图技术之后,大家是不是想要了解图文生成模型的原理以及如何构建训练数据集呢?别急,下面,我们将以Stable Diffusion为例子,以图文的方式带着大家一起掀开Stable Diffusion的面纱。
 Stable Diffusion text-to-image示意图,引自Jay Alammar博客
Stable Diffusion text-to-image示意图,引自Jay Alammar博客
Stable Diffusion是个比较杂合的系统,主要由三个核心模块组成:
-
Text Encoder(文本编码器)
-
Image Information Creator(图像信息生成器)
-
Image Decoder(图像生成器)
 Stable Diffusion模块示意图,引自Jay Alammar博客
Stable Diffusion模块示意图,引自Jay Alammar博客
Text Encoder(文本编码器)
该模块负责处理语义信息。通常是利用CLIP(v1版本)、OpenCLIP(v2版本)等模型将人类语言(文字)编码为计算机语言(语义向量)。训练CLIP(OpenCLIP)则需要一个图文配对的数据集。
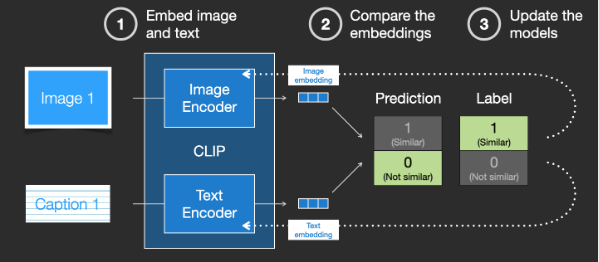 CLIP训练流程图,引自Jay Alammar博客
CLIP训练流程图,引自Jay Alammar博客
Image Infomation Creator(图片信息生成器)
该模块负责生成图片隐变量。其核心则是一个多次迭代的去噪过程,即训练一个去噪的扩散模型。模型的输入是一个带噪声的图片隐变量(含语义向量),通过扩散模型,逐步去除隐变量中的噪声(模型的预测目标是噪声),最终得到去除噪声的隐变量(加噪图减去噪声)。训练这个扩散模型,则需要一个“去噪”数据集。
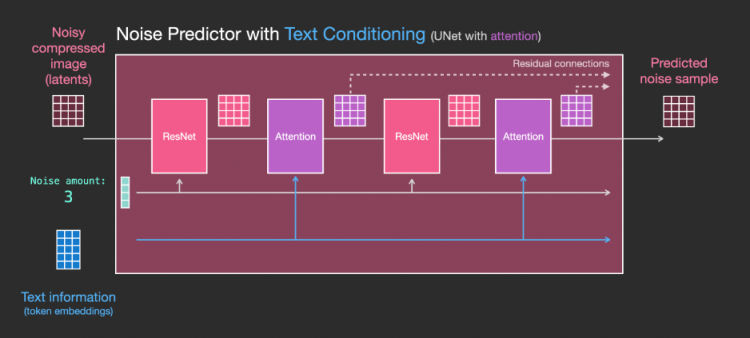 噪声预测器,引自Jay Alammar博客
噪声预测器,引自Jay Alammar博客