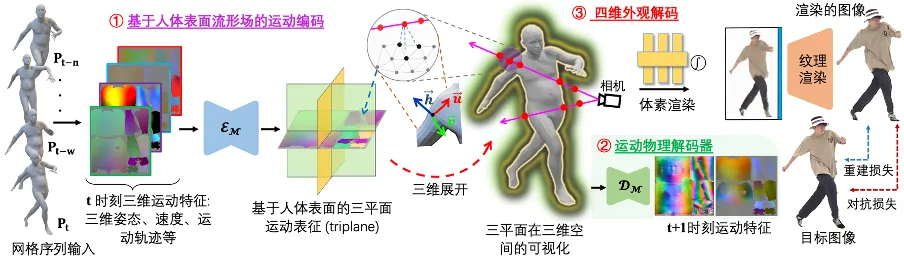
AI 操纵的战斗机又一次进化了!近日,美国 DARPA 透露称,去年 9 月一架由 F-16 改装而成的 AI 验证机,有史以来首次成功地在视距内与人类飞行员进行空中缠斗(俗称狗斗),让我们看到了人工智能在空战领域的应用前景。该验证机代号为 X-62A VISTA,是一架 F-16D(Block 30)双座飞机,人类飞行员同样驾驶一架 F-16 战斗机。在对抗中,DARPA 称,虽然 X-62A VISTA 上的人类飞行员可以接管 AI 系统,但在任何时候都不需要激活安全开关。从视频中可以看到,两架战斗机展示了「高视角机头对机头交战」,逼近时相对速度达到 1200 英里 / 时(约 1931 公里 / 时),两机最近时相距仅为约 610 米。对抗过程中验证了 AI 驾驶战机的防御机动、攻击时缠斗等战斗技能,不过遗憾的是 DARPA 没有透露哪架飞机赢得此次战斗。对此,有人表示终于嗅到了「终结者」的味道。https://mp.weixin.qq.com/s/EAKZPDc1MJnG6fXd3F2DpQ03
星海图高继扬:人形机器人不是具身智能的唯一答案
具身智能已经成为人工智能领域最值得期待的一大赛道之一。现在,智能机器人已经可以自主实现咖啡拉花、搬箱子、叠被子,甚至能够像人与人一样通过自然语言交互,理解人类的意图并做出调整。国内外众多科技公司正在推动机器人变得更加 “智能”,希望它最终可以完成各种任务,能与环境交互感知,拥有自主规划、决策、行动、执行能力。但以终为始,什么样的路径才有可能推动具身智能产品抵达如此高度的智能?星海图 CEO 高继扬(提出了他们的路径想法:对现阶段的具身智能产品而言,代表智能的 “大脑” 比代表执行的 “身体” 更为重要。如果要抵达具身智能的终局,需要针对具体场景推出合适的产品,完成商业闭环,从而得到更多来自物理世界的数据,最终不断提高机器人的 “智能” 程度。https://mp.weixin.qq.com/s/onUEdlmvwrjzJ5sWuobAqQ044
刚刚,a16z 提拔了一位华人女性合伙人负责 12.5 亿美元 AI 基础设施基金!她还是 ElevenLabs 投资人
Jennifer Li 于 2018 年加入 a16z,本周升任为 a16z 第 27 位普通合伙人,在 30 岁出头就达到了这一职业里程碑,将在 a16z 新成立的 12.5 亿美元 AI 基础设施基金扮演关键角色,该基金由资深普通合伙人 Martin Casado管理。据悉,Jennifer Li 在中国北方长大,后移居美国攻读更高学位,拥有卡内基梅隆大学软件工程硕士学位和伦斯勒理工学院技术管理硕士学位。https://mp.weixin.qq.com/s/sqnQCEWUTj3yp2GybgJxwg05
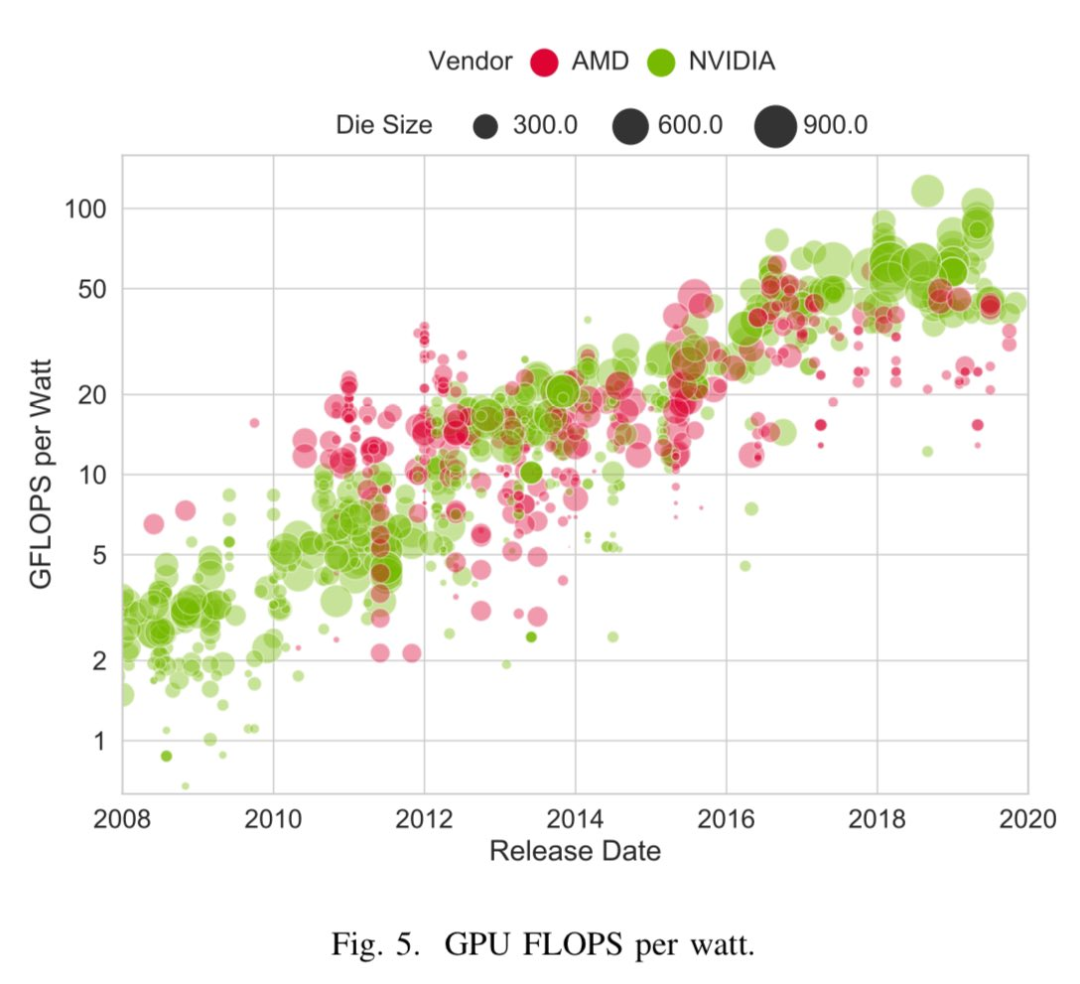
在这个大模型不断创造新成就的时代,我们通常对机器学习模型有一个直观认知:越大越好。但事实果真如此吗?近日,Google Research 一个团队基于隐扩散模型(LDM)进行了大量实验研究,得出了一个结论:更大并不总是更好(Bigger is not Always Better),尤其是在预算有限时。近段时间,隐扩散模型和广义上的扩散模型取得的成就不可谓不耀眼。这些模型在处理了大规模高质量数据之后,可以非常出色地完成多种不同任务,包括图像合成与编辑、视频创建、音频生成和 3D 合成。尽管这些模型可以解决多种多样的问题,但要想在真实世界应用中大规模使用它们,还需要克服一大障碍:采样效率低。该团队通过实验研究了规模大小的变化对 LDM 的性能和效率的影响,其中关注重点是理解 LDM 的规模扩展性质对采样效率的影响。他们使用有限的预算从头开始训练了 12 个文生图 LDM,参数量从 39M 到 5B 不等。https://mp.weixin.qq.com/s/qmVEhCRlpwC6EnALGuGAhA07
Parny 旨在帮助 IT 和技术团队更高效地管理紧急信号,并确保处理紧急情况尽可能顺利和协作的 SaaS 服务。它提供了将所有监控工具的警报整合到一个简化的仪表板中、在警报触发时立即向值班人员发起实时电话、利用 AI 提供快速解决方案建议、使用独特的 #SocialOps 界面促进团队协作,以及通过全面的分析获得有价值的见解来提高运营效率等功能。https://parny.io/03
Open Agent Studio
Open Agent Studio 是一款桌面应用程序,旨在解决当前RPA(机器人流程自动化)工具中存在的基本障碍。该产品提供了一些新颖的功能和技术突破,包括引入了强大的新型RPA概念,如“语义目标”;Agent Recorder 可记录鼠标点击/移动和按键操作,以便使用准确的语义目标重新构建自动化图形;Live Agents 可以自动化常见流程,并根据屏幕上下文智能地建议自动化任务;Prompt To No-Code Graph 可以将开放式自动化提示转换为自定义无代码图形等。此外,Open Agent Studio 还介绍了一些关键的技术突破,包括语义目标的使用、自己的多模态模型Atlas-2、与浏览器的Websocket服务器集成等。https://www.openagent.studio