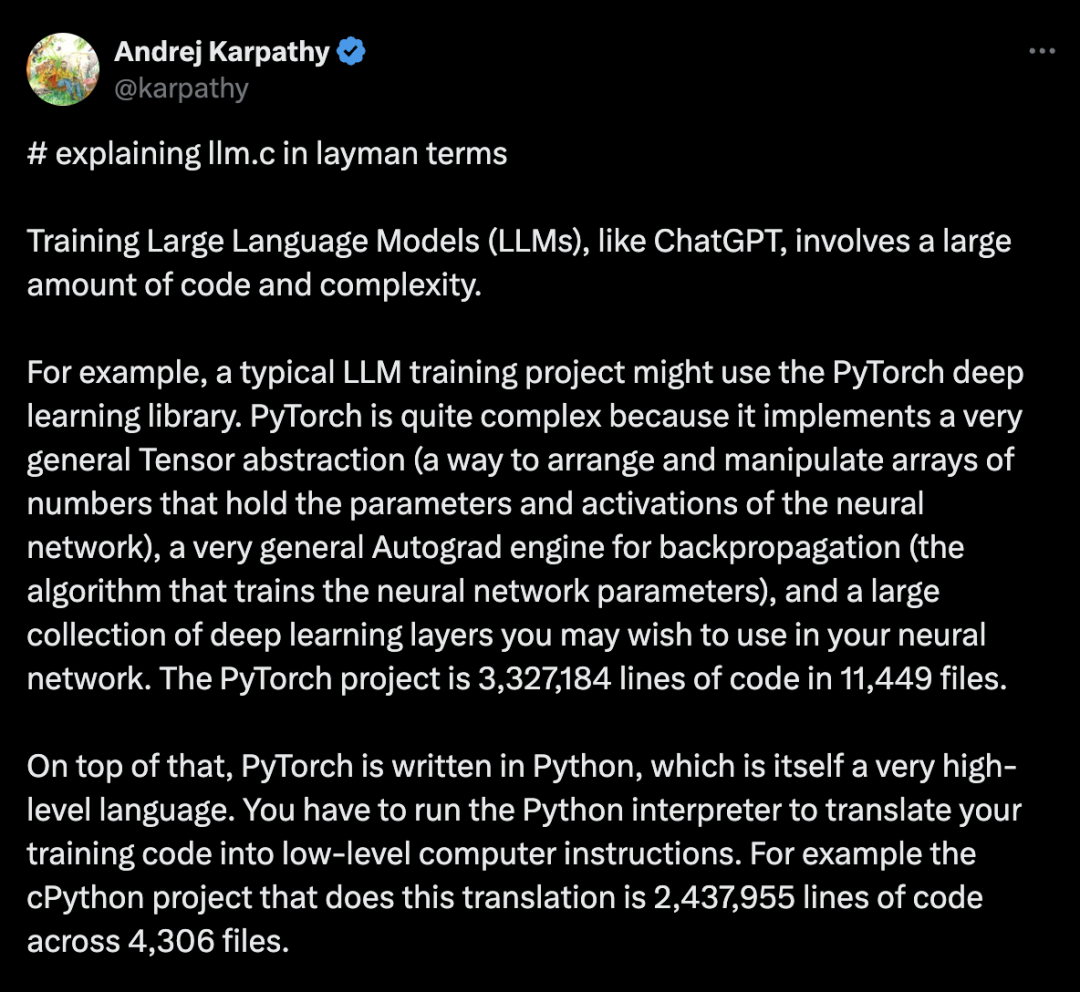
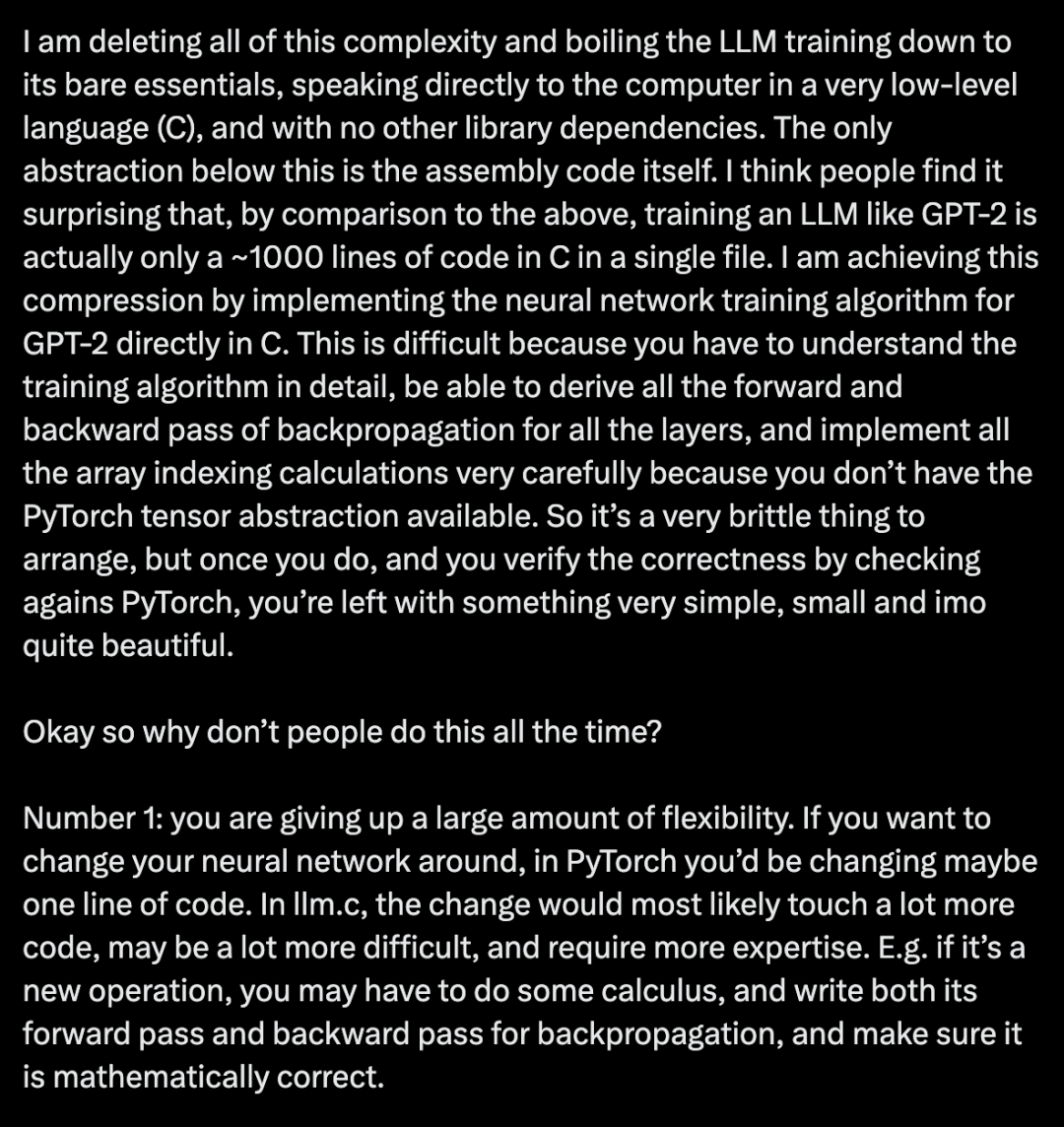
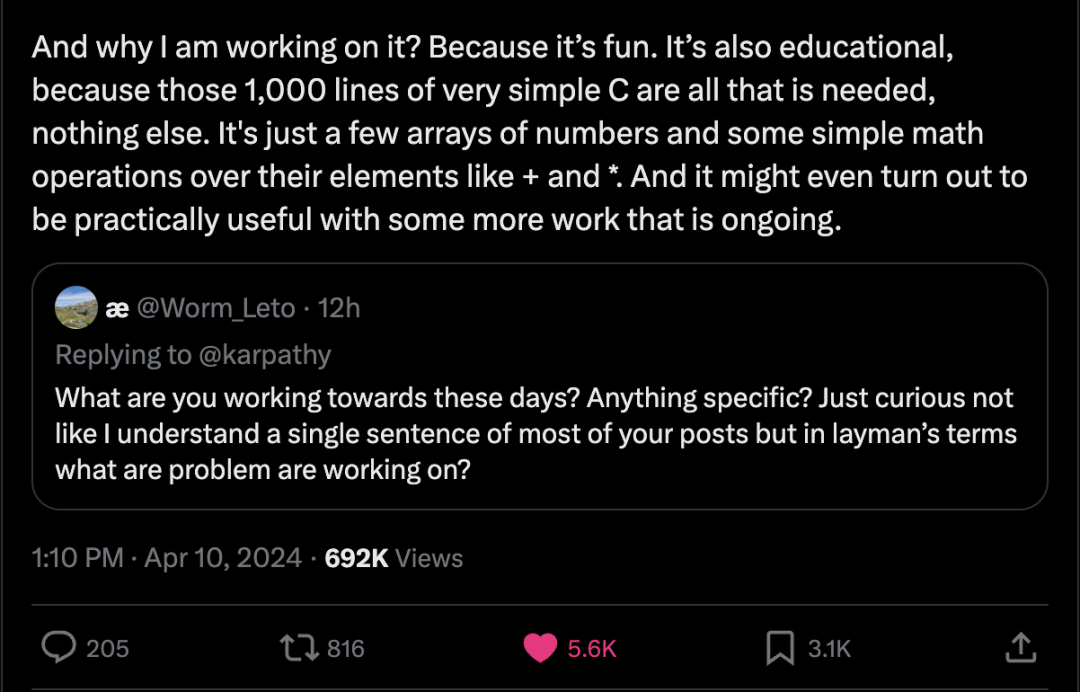
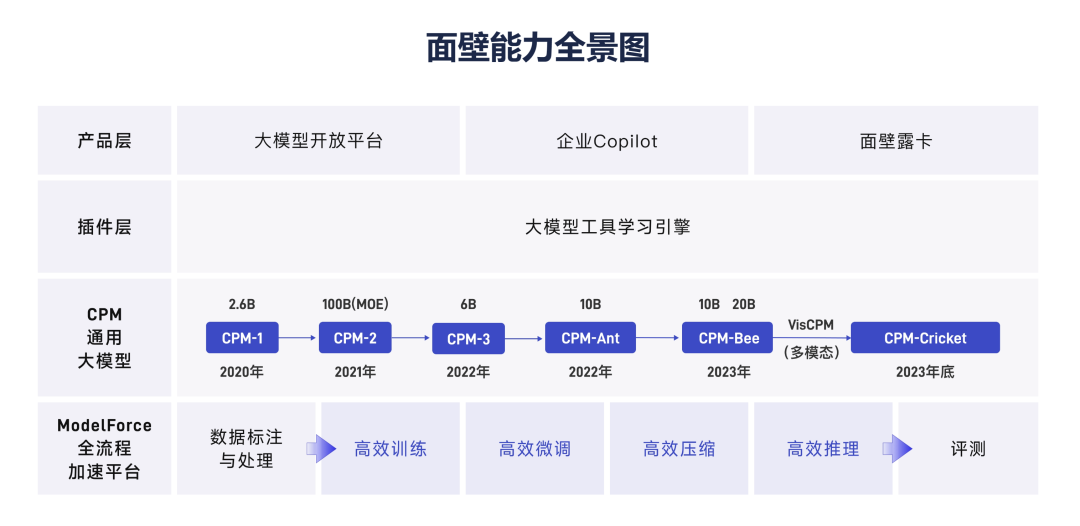
如果语言模型可以通过搜索来更好地推理,为什么不在 Chain of Thought 期做呢?Noahdgoodman分享:数据而非架构的局限
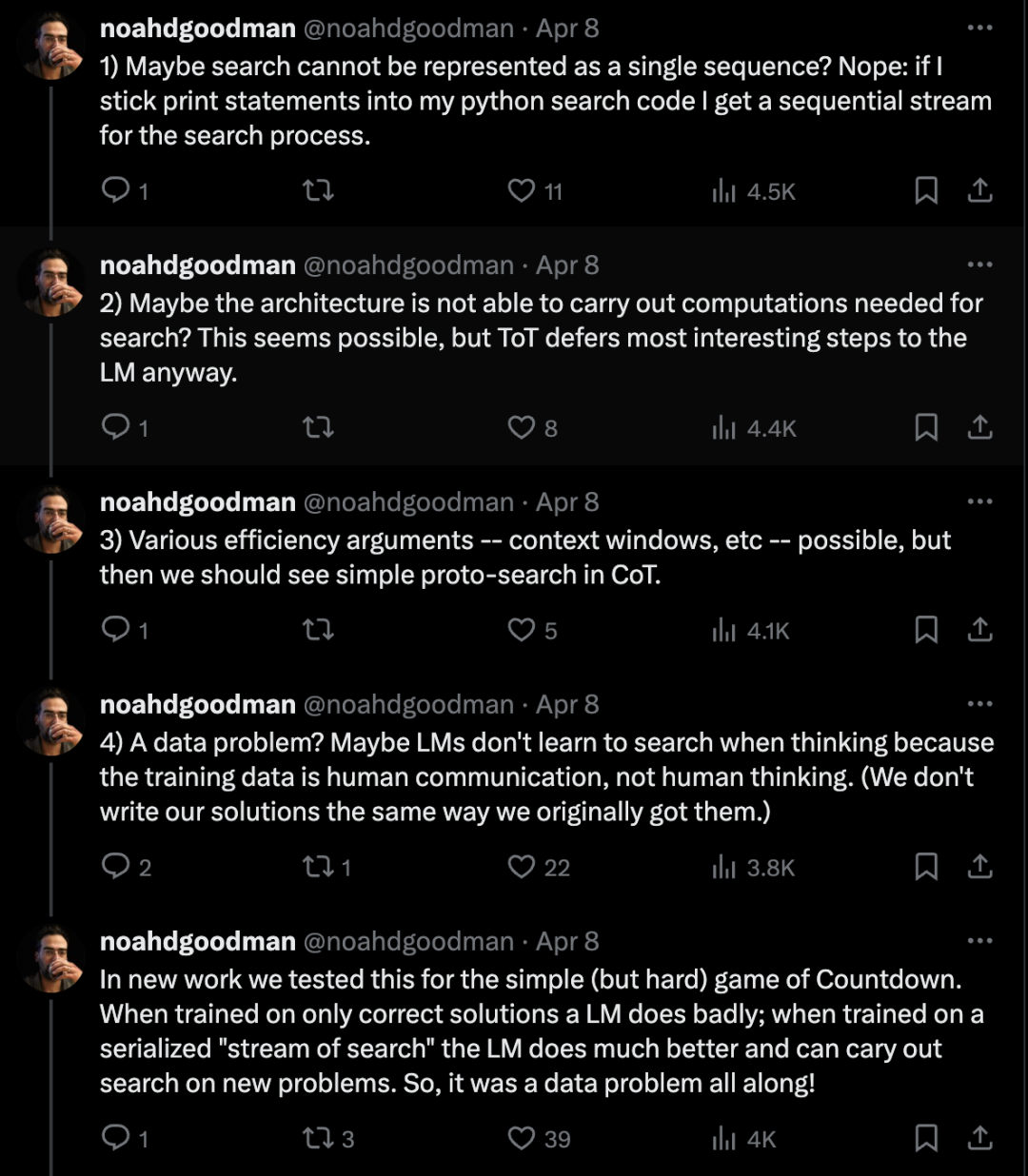
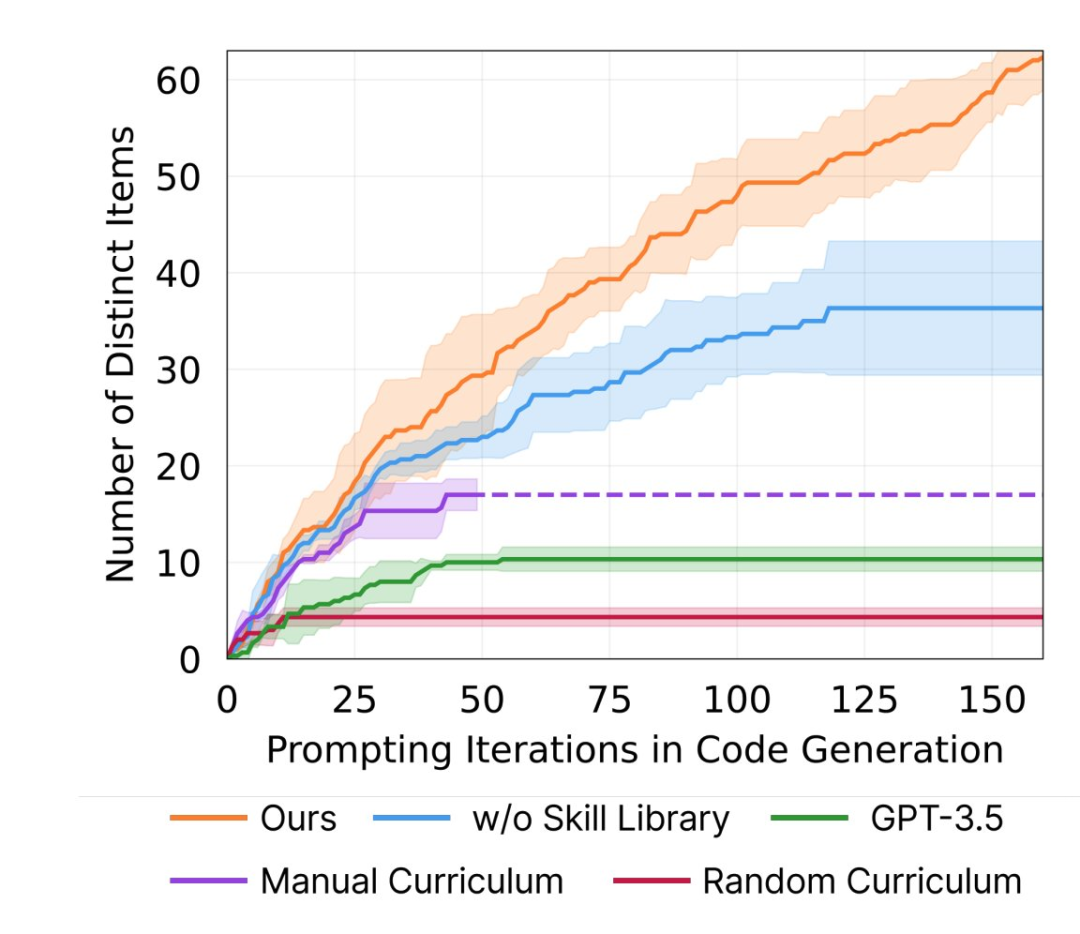
当我第一次看到 Tree of Thoughts 时,我问自己:如果语言模型可以通过搜索来更好地推理,为什么它们在 Chain of Thought 期间不自己做呢?一些可能的答案(和一篇新论文):1)也许搜索不能表示为单个序列?不:如果我在 python 搜索代码中插入打印语句,我会得到搜索过程的连续流。2)也许架构无法执行搜索所需的计算?这似乎是可能的,但 ToT 无论如何都会将大多数有趣的步骤推迟到 LM。3)各种效率论证——上下文窗口等——都有可能,但我们应该在 CoT 中看到简单的原型搜索。4)数据问题?也许 LM 在思考时没有学会搜索,因为训练数据是人类交流,而不是人类思维。(我们写解决方案的方式与我们最初得到它们的方式不同。)在新的工作中,我们测试了简单(但很难)的 Countdown 游戏。当只训练正确的解决方案时,LM 表现不佳;当训练序列化的”搜索流”时,LM 表现更好,可以对新问题进行搜索。所以,这一直是一个数据问题!(警告:这也是一个效率问题。即使对于小问题,SoS 也需要大量上下文。)额外收获!一旦你给了 LM 搜索的概念,它就可以通过 STaR 和 APA 进行自我改进,找到更有效的搜索方法并解决新问题。第一作者 @gandhikanishk 的帖子:https://x.com/gandhikanishk/status/1777358353045622891… Arxiv:https://arxiv.org/abs/2404.03683接下来是什么?研究迁移学习并为预训练的 LM 调整这些想法。https://x.com/noahdgoodman/status/177740975132608117603
由前 Google DeepMind 研究人员创立的人工智能音乐生成器 Udio 开启免费公测,最高每月可免费生成1200首歌曲。该AI音乐生成工具能够根据用户输入的文本提示,包括音乐风格、主题、歌词等信息,快速生成包含人声的完整音轨。Udio不仅支持多种音乐风格和流派,还能够捕捉并表达音乐中的情感,创造出既逼真又具有创意的音乐作品。https://www.udio.com/05
Meta宣布全新训推一体加速器:完全集成PyTorch 2,性能3倍提升
Meta 正在不遗余力地想要在生成式 AI 领域赶上竞争对手,目标是投入数十亿美元用于 AI 研究。这些巨资一部分用于招募 AI 研究员。但更大的一部分用于开发硬件,特别是用于运行和训练 Meta AI 模型的芯片。在英特尔宣布其最新人工智能加速器硬件的第二天,Meta 便迅速公布了关于芯片研发的最新成果:下一代 MTIA(Meta Training and Inference Accelerator),其中 MTIA 是专为 Meta AI 工作负载而设计的定制芯片系列。分析认为,Meta 此举意在减少对英伟达及其他外部公司芯片的依赖。https://mp.weixin.qq.com/s/bzL_WfpjXK1Ha5LsnmS9LQ06
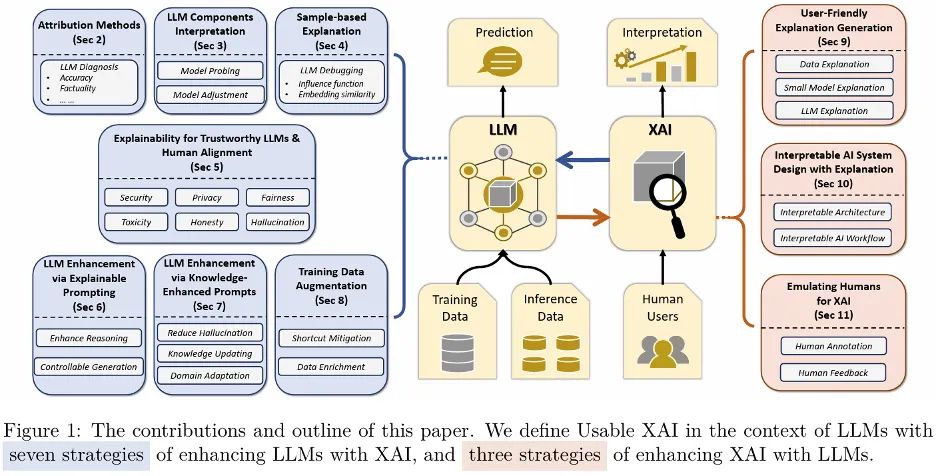
XAI有什么用?探索LLM时代利用可解释性的10种策略
你是否也好奇,在大模型时代,可解释性人工智能技术(XAI)有怎样的使用价值?近日,来自佐治亚大学、新泽西理工学院、弗吉尼亚大学、维克森林大学、和腾讯 AI Lab的研究者联合发布了解释性技术在大语言模型(LLM)上的可用性综述,提出了 「Usable XAI」 的概念,并探讨了 10 种在大模型时代提高 XAI 实际应用价值的策略。这些策略涵盖两方面:(1)如何利用 XAI 来更好地理解和优化 LLM 与 AI 系统;(2)如何利用 LLM 的独特能力进一步增强 XAI。此外,研究团队还通过具体的案例分析说明如何获取和使用大模型的解释。https://mp.weixin.qq.com/s/V35k4UJZPtJkAHqYlZiO1A07
对25,000多个原子进行纳秒级MD模拟,DeepMind开发基于ML的大规模分子模拟通用方法
分子动力学 (MD) 模拟可以深入了解复杂的过程,但准确的 MD 模拟需要昂贵的量子力学计算。对于较大的系统,使用高效但不太可靠的经验力场。机器学习力场(MLFF)提供与从头计算方法相当的精度,速度更快更高效,但难以模拟大分子中的长程相互作用。Google DeepMind、柏林工业大学(Technische Universität Berlin)和卢森堡大学(University of Luxembourg)的研究人员提出了一种通用方法 GEMS,通过对「自下而上」和「自上而下」分子片段进行训练,来构建用于大规模分子模拟的准确 MLFF。https://mp.weixin.qq.com/s/MXp8t2YfIj8gdVc0H0eiSw08梗王”大模型,靠讲笑话登上CVPR | 中山大学
Persana AI 是一款利用人工智能算法来简化潜在客户识别、提取客户洞察以及实现个性化推广的工具,可帮助企业提高销售效率。它能创建全面的客户档案,实现个性化沟通,并自动执行重复性任务,使销售专业人员能够专注于建立关系和推动销售,是一款适用于优化销售流程、识别高质量潜在客户并大规模提供个性化推广的强大且智能的解决方案的产品。https://persana.ai/02
Prelaunch AI Idea Validator
Prelaunch Idea Validator 可以在不到3分钟的时间内将用户的想法转化为一个产品页面,并从朋友、用户的社交网络以及2亿人的群体中获取反馈,帮助用户快速验证自己的想法。https://prelaunch.com/features/idea.html投融资01