特别活动!
欢迎观看大模型日报 , 如 需 进 入 大 模 型 日 报 群 和 空 间 站 请 直 接 扫 码 。 社 群 内 除 日 报 外 还 会 第 一 时 间 分 享 大 模 型 活 动 。
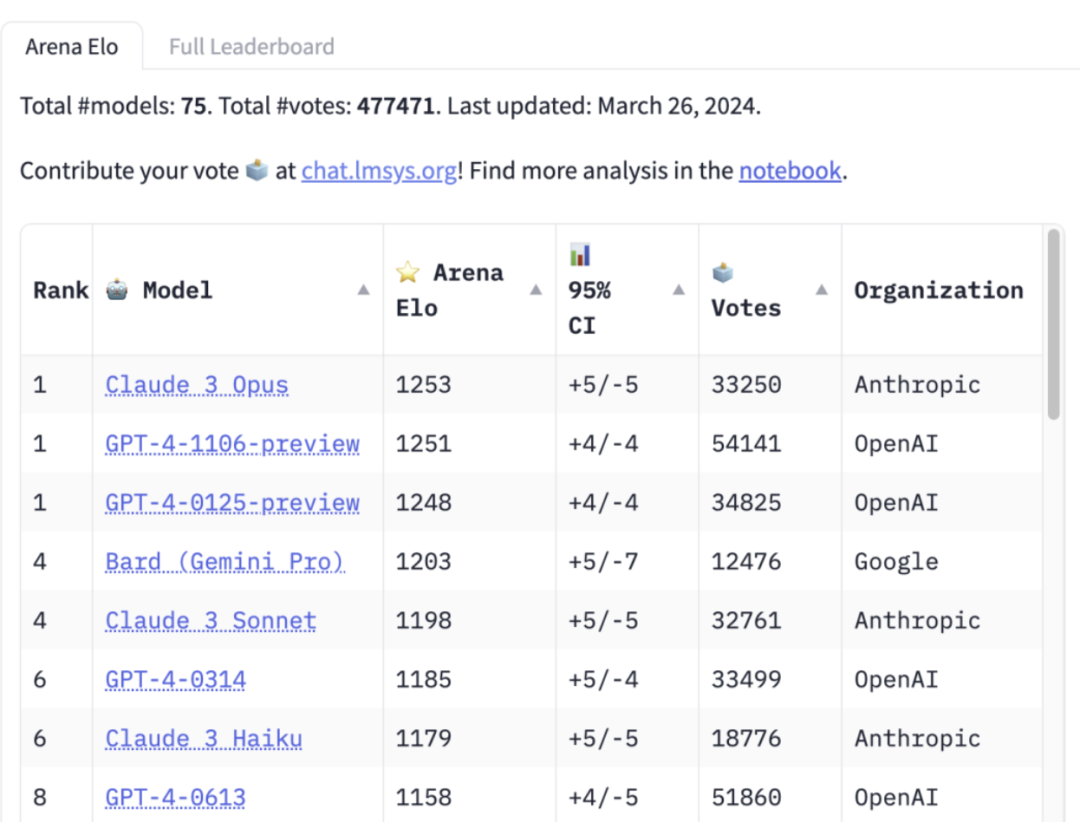
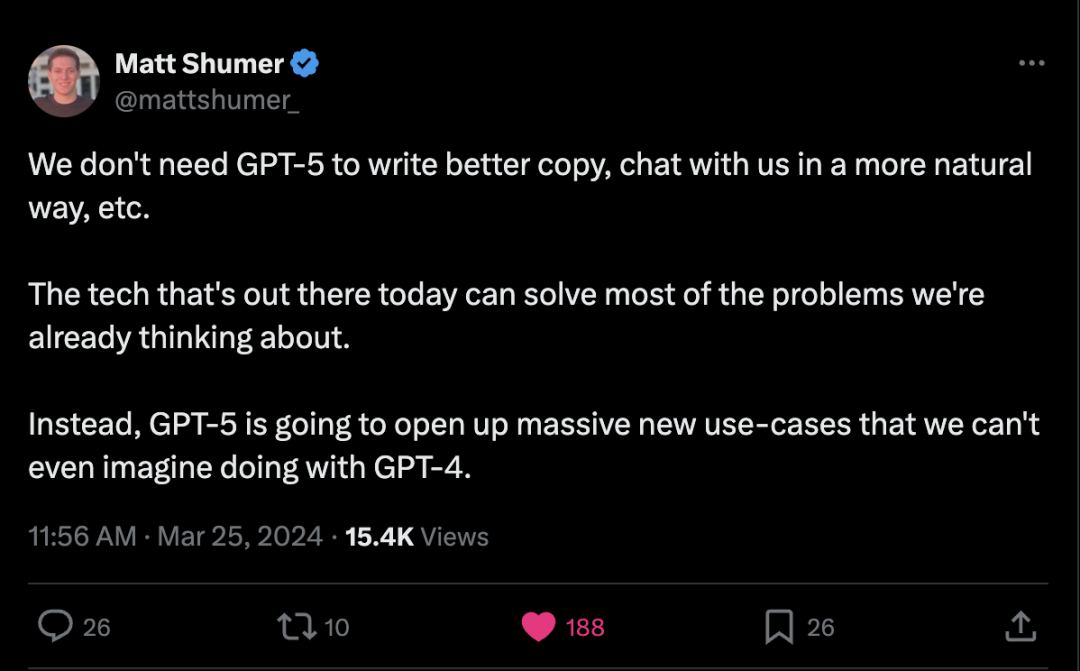
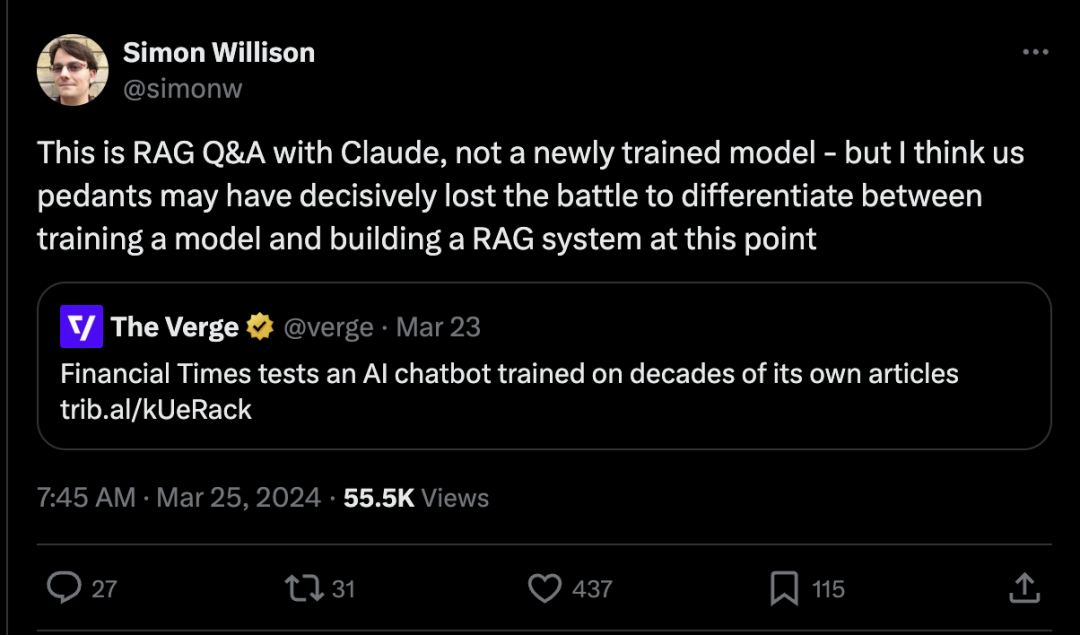
资 讯 两分钟1200帧的长视频生成器StreamingT2V来了,代码将开源 这段长达 1200 帧的 2 分钟视频来自一个文生视频(text-to-video)模型,尽管 AI 生成的痕迹依然浓重,但我们必须承认,其中的人物和场景具有相当不错的一致性。这是如何办到的呢?要知道,虽然近些年文生视频技术的生成质量和文本对齐质量都已经相当出色,但大多数现有方法都聚焦于生成短视频(通常是 16 或 24 帧长度)。然而,适用于短视频的现有方法通常无法用于长视频(≥ 64 帧)。即使是生成短序列,通常也需要成本高昂的训练,比如训练步数超过 260K,批大小超过 4500。如果不在更长的视频上进行训练,通过短视频生成器来制作长视频,得到的长视频通常质量不佳。而现有的自回归方法(通过使用短视频后几帧生成新的短视频,进而合成长视频)也存在场景切换不一致等一些问题。为了克服现有方法的缺点和局限,Picsart AI Resarch 等多个机构联合提出了一种新的文生视频方法:StreamingT2V。这也是一种自回归方法,并配备了长短期记忆模块,进而可以生成具有时间一致性的长视频。 详解Latte:去年底上线的全球首个开源文生视频DiT 随着 Sora 的成功发布,视频 DiT 模型得到了大量的关注和讨论。设计稳定的超大规模神经网络一直是视觉生成领域的研究重点。DiT [1] 的成功为图像生成的规模化提供了可能性。然而,由于视频数据的高度结构化与复杂性,如何将 DiT 扩展到视频生成领域却是一个挑战,来自上海人工智能实验室的研究团队联合其他机构通过大规模的实验回答了这个问题。早在去年 11 月,该团队就已经开源了一款与 Sora 技术相似的自研模型:Latte。作为全球首个开源文生视频 DiT,Latte 受到了广泛关注,并且模型设计被众多开源框架所使用与参考,如 Open-Sora Plan (PKU) 和 Open-Sora (ColossalAI)。 ICLR 2024 | RLHF有了通用平台和基准,天大开源,专攻现实决策场景 RLHF 通过学习人类偏好,能够在难以手工设计奖励函数的复杂决策任务中学习到正确的奖励引导,得到了很高的关注,在不同环境中选择合适的人类反馈类型和不同的学习方法至关重要。然而,当前研究社区缺乏能够支持这一需求的标准化标注平台和统一基准,量化和比较 RLHF 的最新进展是有挑战性的。本文中,天津大学深度强化学习实验室的研究团队推出了面向现实决策场景的 Uni-RLHF 平台,这是一个专为 RLHF 量身定制的综合系统实施方案。它旨在根据真实的人类反馈提供完整的工作流程,一站式解决实际问题。 Nature|机器学习和物理模型的「双向奔赴」,3种AI气候建模方法 气候科学家 Tapio Schneider 很高兴,因为机器学习让他摆脱了日常工作中繁琐乏味的任务。十多年前,当他第一次开始模拟云的形成时,这主要涉及到煞费苦心地调整描述水滴、气流和温度如何相互作用的方程。但自 2017 年以来,机器学习和人工智能 (AI) 改变了他的工作方式。「机器学习让这门科学变得更加有趣,」在加州理工学院工作的 Schneider说。「它速度更快、更令人满意,而且你可以获得更好的解决方案。」传统的气候模型是由 Schneider 等科学家从头开始手动构建的,他们使用数学方程来描述陆地、海洋和空气相互作用并影响气候的物理过程。这些模型运行良好,足以做出指导全球政策的气候预测。但这些模型依赖于强大的超级计算机,需要数周的时间才能运行,并且是能源密集型的。Schneider 说,一个典型的模型需要消耗高达 10 兆瓦时的能量来模拟一个世纪的气候。平均而言,这大约相当于一个美国家庭每年的用电量。此外,此类模型很难模拟小规模过程,例如雨滴的形成方式,而雨滴通常在大规模天气和气候结果中发挥重要作用,Schneider 说。 促进癌症治疗,之江实验室团队开发端到端深度学习模型 DeepAEG 由于药物疗效的不确定性和患者的异质性,癌症药物反应的预测是现代个性化癌症治疗中的一个具有挑战性的课题。而且,药物本身的特性和患者的基因组特征可以极大地影响癌症药物反应的结果。因此,准确、高效、全面的药物特征提取和基因组学整合方法对于提高预测精度至关重要。之江实验室的研究团队提出了一种名为 DeepAEG 的端到端深度学习模型,它基于完整图更新模式来预测 IC50 值。并且,研究人员提出了一种新方法,通过采用序列重组来增强简化的分子输入行输入规范数据,从而消除药物分子单一序列表示的缺陷。DeepAEG 在多个测试集的多个评估参数上优于其他现有方法。此外,利用 DeepAEG,研究人员还确定了几种潜在的抗癌药物,包括硼替佐米(它已被证明是一种有效的临床治疗选择)。研究人员认为 DeepAEG 在指导特定癌症治疗方案设计方面具有潜在价值。 微软“520”特别 AI 活动|CEO 纳德拉将公布新的 AI 软硬件愿景与计划 根据外媒 The Verge 最新消息,Microsoft 宣布于 5 月 20 日在 Build 2024 开发者大会前举办一场特别的 AI 活动,CEO Satya Nadella 将讨论公司在硬件和软件上的 “AI 愿景”。据悉,Microsoft 这场特别活动将聚焦于即将推出的 Surface 硬件和对 Windows 的改变,这些改变都集中在 AI 上,而 5 月 20 日的活动将包括消费者版本的 Surface Pro 10 和 Surface Laptop 6。这些消费者级 Surface 设备将搭载 Qualcomm 最新的 Snapdragon X Elite 处理器,并包括专用的 NPU硬件,以加速 Windows 11 中的 AI 任务。Microsoft 还在开发一个名为 AI Explorer 的新功能,用于 Windows 11,旨在作为你可以在 PC 上搜索的时间线。 46秒AI生成真人视频爆火,遭在线打假「换口型、声音」 一段宣称完全由 AI 生成的不到 50 秒的视频在社交圈疯传,在「视频是否真由 AI 生成」这一点上,网友更是在评论区吵翻了天。上传者表示,音频和视频都是 AI 生成的,它们出自一款 AI 工具 Arcads。有人想要上传者提供 AI 生成的证据,上传者只是含糊回答「视频就是 AI 生成,自己没有那么无聊。」在 Arcads 官方网站上,研发团队介绍称 Arcads 是一款人工智能驱动的工具,旨在将文本转换为高质量的视频广告。它使用先进的人工智能算法来生成逼真的视频,只需要用户提供文本。 https://www.zhitongcaijing.com/content/detail/1091869.html Claude 3反超GPT-4竞技场登顶!小杯Haiku成开发者新宠:性价比无敌 GPT-4真的被反超了!大模型竞技场上,Claude 3大杯Opus新王登基,Elo分数来到榜首。连小杯Haiku也跻身第二梯队,超过了GPT-4-0613这个型号,把GPT-3.5-turbo远远甩在身后。Haiku的输入token价格,可是比GPT-3.5-turbo还便宜了一半,输出方面,每100万token也比GPT-3.5-turbo便宜近2块钱。 Omdia预测随着GenAI需求增加,2024年全球半导体供应链将见增长 Omdia的最新研究揭示,随着企业日益利用生成式人工智能(GenAI)能力,全球半导体供应链预计到2024年将达到约6000亿美元。在过去几个季度经历战略性库存调整后,半导体行业预计将呈现出乐观的发展轨迹。此外,生成式AI技术的最近进展已经引起了主要技术玩家和企业的极大兴趣,从而推动了对AI芯片的需求增加。此消息发布之际,Omdia分析师正准备在2024年4月17日至18日于台北举行的Omdia台湾技术大会上分享洞察。 https://bangkokstyle.online/omdia-global-semiconductor-supply-chain-set-to-see-growth-in-2024-as-genai-demand-increases/ 推特 Alexander Koch:价值 250 美元的机器人手臂叠衣服 使用价值 250 美元的机器人手臂叠衣服。我添加了另一个电机来提高移动性并扩展触及范围。CAD 文件和代码在以下网址公开: https://github.com/AlexanderKoch-Koch/low_cost_robot… https://x.com/alexkoch_ai/status/1772750496174149708?s=20 Tone:售价 299 美元的 AI 可穿戴设备,充当你的第二大脑 介绍 Tone,一款售价 299 美元的 AI 可穿戴设备,充当你的第二大脑,将你的生活经历提炼成个人 AI,赋予你超能力。 从大型主机电脑 → 个人电脑 → 笔记本电脑 → 智能手机 → 智能手表,随着产品的发展,我们使用的产品与我们的生活联系得越来越紧密。 下一个进化也不会有什么不同。在后智能手机时代,我们日常使用的技术将作为我们自身的延伸,无缝地融入我们的生活,并提升我们的自然能力。个人计算的下一次演进将赋予你超能力。 Tone 的诞生源于我们对现有 AI 可穿戴设备的不满。与其他替代品相比,Tone 在设计时考虑到了质量:对于像吊坠一样小巧和微妙的设备,细节决定成败:
Tone 是目前最小的 AI 吊坠,比最接近的竞争对手小约 20%(硬币大小),同时仍保持全天电池续航时间。
现在,我们认识到这种设备存在隐私问题。信任一个平台来处理如此敏感的数据时,总是需要谨慎对待。为了为计算的下一个时代树立一个良好的先例,我们正在探索各种透明度方法,包括开源相关的固件和后端部分,以及由行业专业人士进行数据隐私审查。 https://x.com/JacksonOswalt/status/1772681225938845724?s=20 eyonder-4x7B-v3:使用 @arcee_ai 的 mergekit 制作的 MoE 模型 Beyonder-4x7B-v3 我在 @huggingface 上发布了广受欢迎的 Beyonder-4x7B-v2 的新版本。这是一个使用 Arcee_ai 的 mergekit 制作的 MoE 模型,结合了四个模型:
编程:CodeNinja-1.0-OpenChat-7B
https://huggingface.co/mlabonne/Beyonder-4x7B-v3… https://huggingface.co/mlabonne/Beyonder-4x7B-v3-GGUF https://x.com/maximelabonne/status/1772175274022482125?s=20 MatX:专为大型语言模型设计硬件,供更多数量级的计算能力 介绍 MatX:我们专为大型语言模型(LLM)设计硬件,提供更多数量级的计算能力,以便 AI 实验室可以让他们的模型更加智能。我们的硬件可以让小型初创公司用他们的预算来训练 GPT-4 和运行 ChatGPT。我们的创始团队曾在谷歌和亚马逊设计芯片,我们用典型所需团队规模的 1/10 就能制造出芯片。以下是我们如何解决计算效率低下和计算能力不足的问题。 当其他芯片平等对待所有模型时,我们致力于将每一个晶体管用于最大化世界上最大模型的性能。我们的目标是让世界上最好的 AI 模型以物理学允许的最高效率运行,使世界在 AI 质量和可用性方面领先数年。一个智能更广泛可用的世界是一个更加幸福和繁荣的世界——想象一下,所有社会经济阶层的人都可以获得由专家医生、导师、教练、顾问和助手组成的 AI 团队。 我们的设计专注于大型模型高容量预训练和生产推理的成本效率。这意味着:
我们优先考虑每美元性能(我们将遥遥领先),其次是延迟(我们将具有竞争力)。
我们提供出色的横向扩展性能,支持拥有数十万个芯片的集群。
对于这些工作负载,可以实现最高性能:基于 Transformer 的大型模型(密集型和 MoE),最好是 20B+ 参数,推理有数千个并发用户。
我们为您提供对硬件的低级访问。我们相信,最好的硬件是由 ML 硬件专家和 LLM 专家共同设计的。
MatX 团队中的每个人,从应届毕业生到行业资深人士,都是优秀的人才。我们的行业资深人士曾在谷歌、亚马逊或各种初创公司构建 ML 芯片、ML 编译器和 LLM。我们的首席执行官 @reinerpope 是谷歌 PaLM 的效率主管,他设计并实现了世界上最快的 LLM 推理软件。我们的首席技术官 @mikegunter_ 曾是谷歌一款 ML 芯片(当时是谷歌最快的)的首席架构师,也是谷歌 TPU 的架构师。我们的首席硅设计官 @avinashgmani 在亚马逊、Innovium 和博通(Broadcom)拥有超过 25 年的硅和软件产品构建和世界级工程团队管理经验。 我们获得了来自专业投资者和运营商的 2500 万美元投资,他们与我们有共同的愿景,包括:@danielgross 和 @natfriedman(主要投资者,AI 领域的专家)、@rkhemani(Auradine 的首席执行官)、@amasad(Replit 的首席执行官)、@outsetcap、@homebrew、@svangel。此外,我们还获得了领先的 AI 和 LLM 研究人员的投资,包括 @IrwanBello、@jekbradbury、@achowdhery、@liamfedus 和 @hardmaru。 https://x.com/MatXComputing/status/1772615554421170562?s=20 Shumer:我们不需要 GPT-5 来写出更好的文案,需要解决无法想象的全新用例 我们不需要 GPT-5 来写出更好的文案,以更自然的方式与我们聊天等等。现有的技术已经可以解决我们正在考虑的大部分问题。相反,GPT-5 将开启大量我们甚至无法想象用 GPT-4 来做的全新用例。 https://x.com/mattshumer_/status/1772336749546549641?s=20 Willison: Financial Times不是新训练了一个模型,但是已经被混淆太多 这是使用 Claude 进行的 RAG 问答,而不是一个新训练的模型——但我认为,在区分训练模型和构建 RAG 系统这一点上,我们这些吹毛求疵的人可能已经决定性地输掉了这场战斗。 The Verge @verge · 3月23日 这让我想起有一次,我被要求构建一个机器学习推荐系统,最终我意识到,他们并不真正关心机器学习,他们想要一种算法,能够给出足够好的建议……一点SQL和一个Elasticsearch查询就可以很好地解决问题! https://x.com/simonw/status/1772273715851473337?s=20 论文 LISA:通过逐层重要性抽样实现内存高效的大语言模型微调 机器学习领域自大型语言模型(LLMs)首次出现以来取得了令人瞩目的进展,但是它们巨大的内存消耗已成为大规模训练的主要障碍。提出了参数高效微调技术,如低秩适应(LoRA),以缓解这一问题,但它们在大规模微调设置中的性能仍无法与完整参数训练相匹配。通过研究LoRA在微调任务中的逐层特性,我们观察到不同层之间权重规范的不寻常倾斜。利用这一关键观察,我们发现了一种出乎意料的简单训练策略,它在一系列设置中的性能超过了LoRA和完整参数训练,并且内存成本低于LoRA。我们称之为层次重要性采样AdamW(LISA),这是LoRA的一种有前途的替代方案,它将重要性采样的思想应用于LLMs中的不同层,并在优化过程中随机冻结大多数中间层。实验结果表明,在类似或更少的GPU内存消耗下,LISA在下游微调任务中超越了LoRA甚至完整参数微调,其中LISA在MT-Bench评分方面连续优于LoRA $11%$-$37%。在大型模型,特别是LLaMA-2-70B上,LISA在MT-Bench、GSM8K和PubMedQA上实现了与LoRA相当或更好的性能,展示了其跨不同领域的有效性。 http://arxiv.org/abs/2403.17919v1 语言模型的顶层是不可理喻的无用 我们主要研究了一种简单的层修剪策略,用于流行的大型预训练LLM系列,发现在移除大部分层之前,不同问答基准测试的性能几乎没有下降。为了修剪这些模型,我们通过考虑层间的相似性来确定最佳的层块进行修剪;然后,为了“修复”损害,我们进行少量微调。具体来说,我们使用参数高效的微调(PEFT)方法,特别是量化和低秩适配器(QLoRA),以便我们的每个实验可以在单个A100 GPU上执行。从实际角度看,这些结果表明层修剪方法可以辅助其他PEFT策略,进一步减少微调的计算资源,另一方面可以改善推理的内存和延迟。从科学角度看,这些LLM对删除层的鲁棒性意味着当前的预训练方法要么没有充分利用网络中更深层的参数,要么浅层对于存储知识起着关键作用。 h ttp://arxiv.org/abs/2403.17887v1 基于朴素贝叶斯的大语言模型上下文扩展 大语言模型(LLM)展现出了在上下文学习方面的潜力。然而,传统的上下文学习(ICL)方法常常受到Transformer架构长度限制的阻碍,当尝试有效地整合大量示范示例时,会遇到挑战。在本文中,我们引入了一种名为朴素贝叶斯的上下文扩展(NBCE)的新框架,可以通过显著扩展上下文大小,使现有的LLM能够进行ICL,并能够处理更多的示范。重要的是,这种扩展不需要微调或依赖特定的模型架构,同时保持了线性效率。NBCE首先将上下文分成适合目标LLM最大长度的等大小窗口。然后,它引入了一个投票机制来选择最相关的窗口,被视为后验上下文。最后,它使用贝叶斯定理生成测试任务。我们的实验结果表明,NBCE显著提高了性能,特别是在示范示例数量增加时,始终优于其他方法。NBCE代码将公开。NBCE代码可在以下网址找到:https://github.com/amurtadha/NBCE-master http://arxiv.org/abs/2403.17552v1 InternLM2 技术报告 大语言模型(LLMs)的演变如ChatGPT和GPT-4已引发了人工通用智能(AGI)的讨论。然而,在开源模型中复制这些进步一直是具有挑战性的。本文介绍了InternLM2,一个开源的LLM,在综合评估、长文本建模和开放性主观评估方面优于其前任,通过创新的预训练和优化技术。InternLM2的预训练过程详细说明了准备各种数据类型,包括文本、代码和长文本数据。InternLM2有效地捕捉长期依赖关系,最初在预训练和微调阶段以4k令牌进行训练,然后进展到32k令牌,展示了在200k“大海捞针”测试中卓越的性能。InternLM2进一步通过监督微调(SFT)和一种新颖的有条件在线强化学习从人类反馈(COOL RLHF)策略对齐,解决了人类偏好和奖励欺骗的冲突。释放InternLM2模型在不同训练阶段和模型大小,我们为社区提供了模型演变的见解。 http://arxiv.org/abs/2403.17297v1 混合架构的机制设计和扩展 深度学习架构的发展是一个资源密集型的过程,由于设计空间广阔、原型制作时间长,以及与规模模型训练和评估相关的高计算成本。我们致力于通过基于端到端机械结构设计(MAD)流水线来简化这一过程,包括小规模能力单元测试,可预测扩展定律。通过一系列合成令牌操作任务,如压缩和召回,设计用于探究能力的任务,我们识别并测试由各种计算基元构建的新混合架构。我们通过大量计算优化和新的状态优化扩展定律分析实验验证了结果架构,训练超过500个参数为70M至7B的语言模型。令人惊讶的是,我们发现MAD合成与计算最佳困惑度相关,通过隔离代理任务准确评估新架构。通过MAD发现的新架构,基于诸如混合化和稀疏性等简单思想,优于当前最先进的Transformer、卷积和循环架构(Transformer++、Hyena、Mamba)在规模化方面,无论是在计算最佳预算方面还是在 过度训练的情况下。总的来说,这些结果表明,在精心策划的合成任务上的性能可以预测扩展定律,并且最佳架构应通过混合拓扑来利用专用层。 http://arxiv.org/abs/2403.17844v1 在英特尔数据中心GPU上的完全融合多层感知机 这篇论文提出了针对英特尔数据中心GPU Max 1550优化的多层感知机(MLPs)的SYCL实现。通过最大化智能体内的数据重用,减少慢速全局内存访问,融合MLP每一层的操作,提高算术强度,从而实现性能的显著增加,尤其是用于推断。与类似的CUDA实现进行比较,结果显示在推断和训练方面,我们在英特尔数据中心GPU上的实现超过了Nvidia的H100 GPU上的CUDA实现2.84倍和1.75倍。该论文还展示了我们的SYCL实现在图像压缩、神经辐射场和物理信息机器学习等三个重要领域的效率。在所有情况下,我们的实现均比英特尔PyTorch的官方扩展(IPEX)实现快30倍,比Nvidia的H100 GPU上的CUDA PyTorch版本快19倍。可在 https://github.com/intel/tiny-dpcpp-nn http://arxiv.org/abs/2403.17607v1 通过自动提示优化提高文生图的一致性 在文本到图像(T2I)生成模型中取得了令人印象深刻的进展,产生了大量性能优秀的模型,能够生成美观逼真的图像。尽管有进展,这些模型仍然难以生成与输入提示一致的图像,经常无法正确捕捉对象数量、关系和属性。现有的改进提示-图像一致性的解决方案面临着挑战:(1)它们经常需要模型微调,(2)它们只关注附近的提示样本,(3)它们受到图像质量、表示多样性和提示-图像一致性之间不利的权衡影响。在本文中,我们解决这些挑战,引入了一个T2I优化-提示框架OPT2I,利用大型语言模型(LLM)来改善T2I模型中的提示-图像一致性。我们的框架从用户提示开始,迭代生成修订提示,旨在最大化一致性评分。在MSCOCO和PartiPrompts两个数据集上进行的广泛验证表明,OPT2I可以将初始一致性评分提高高达24.9%,同时保留FID并增加生成数据和真实数据之间的召回率。我们的工作通过利用LLM的力量,为构建更可靠和强大的T2I系统铺平了道路。 http://arxiv.org/abs/2403.17804v1 产品 Creatie Creatie 致力于将人工智能应用于设计领域,以帮助设计师更轻松、更快乐地进行构思、设计、协作、原型制作等,并保持对创意的控制和乐趣。团队相信人工智能可以成为设计过程中的一种工具,协助设计师提高效率,而非取代设计师的创造力和人情味。 https://creatie.ai/ Buildbox 4 Alpha Buildbox 是一款无需编程、编码或脚本即可专注于游戏创作的无代码开发平台。即使是初学者也可以轻松上手。它还提供了广泛的模板和资源,使创建游戏变得更加容易。 https://signup.buildbox.com/?waitlist=true H uggingFace&Github OpenDevin OpenDevin 是一个旨在复现 Devin 的开源项目,Devin 是一位自主的 AI 软件工程师,能够执行复杂的工程任务并与用户在软件开发项目上积极协作。该项目希望通过开源社区的力量复现、增强和创新 Devin。 https://github.com/OpenDevin/OpenDevin Codel Codel 是一个完全自主的 AI Agent,它可以自主使用终端、浏览器和编辑器执行复杂的任务和项目。 https://github.com/semanser/codel GLEE GLEE是一个通用对象基础模型,在不同级别的监督下,在来自各种基准的超过1000万张图像上进行了联合训练。可以同时处理各种以对象为中心的任务,同时保持SOTA性能。 https://github.com/FoundationVision/GLEE T-Rex2 物体检测是计算机视觉的基石,传统目标检测模型存在封闭集性质的局限性,限制在预先确定的类别上识别物体。T-Rex2通过整合文本和视觉提示解决了这些限制,赋予其强大的零样本学习能力,使其适合各种实际应用,包括但不限于:农业、工业、活畜和野生动物监测、医学、OCR、物流等。T-Rex2主要支持交互式视觉提示工作流、通用视觉提示工作流和文本提示工作流三大工作流程。 https://github.com/IDEA-Research/T-Rex 投融资 0G Labs完成3500万美元前种子轮融资以构建模块化AI区块链 G Labs,一家Web3基础设施公司,宣布已经完成了3500万美元的前种子轮融资,使其总融资额达到约2000万美元。这一巨额融资由Hack VC领投,超过40家加密领域的机构投资者参与,包括Alliance、Animoca Brands、Delphi Digital、Stanford Builders Fund、Symbolic Capital和OKX Ventures等。0G Labs计划利用这笔资金招聘工程师,扩大市场功能、社区和生态系统。0G Labs正在创建一个模块化AI区块链,旨在解决Web3生态系统中链上AI应用的痛点,如速度和成本效率,通过模块化让开发者可以根据需要选择构建区块链系统或应用的组件。 https://techcrunch.com/2024/03/26/0g-labs-launches-with-whopping-35m-pre-seed-to-build-a-modular-ai-blockchain/ Activeloop完成1100万美元早期融资以扩展其AI训练与推断的专用张量数据库 Activeloop,一个专门为人工智能工作负载设计的数据库平台创造者,宣布完成1100万美元的早期融资,使其总融资额达到约2000万美元。本轮系列A融资由Streamlined Ventures领投,Y Combinator、Samsung Next、Alumni Ventures和Dispersion Capital等新投资者参投。Activeloop开发的Deep Lake数据库旨在简化非结构化信息流入机器学习和大型语言模型的过程,支持数字转型、操作自动化、基于AI的洞察、韧性以及迁移到云端。此外,Activeloop还开发了一种快速数据加载器,允许信息有效地流向图形处理单元来加速AI模型的训练。 公司官网:https://www.activeloop.ai/ https://siliconangle.com/2024/03/26/activeloop-raises-11m-grow-specialized-database-ai-training-inference/ Fieldguide完成3000万美元B轮融资,推出AI平台解决注册会计师人才短缺问题 Fieldguide宣布完成了3000万美元的B轮融资,由Bessemer Venture Partners领投,参投方包括8VC以及AI和SaaS领域的思想领袖。这轮融资的成功凸显了公司使命的重要性,即通过其首创的AI平台为咨询和审计行业带来革命性变革,以解决当前行业面临的注册会计师人才短缺问题。Fieldguide的AI平台专为咨询和审计服务设计,通过自动化工作流程、简化操作流程,以及为CPA提供高价值工作的机会,旨在使审计和咨询公司能够更有效地利用其团队,同时提高从业者和客户的满意度。此外,Fieldguide计划利用这笔资金扩大产品范围、扩大市场覆盖并增强其工程团队。 公司官网:https://www.fieldguide.io/?ref=ai-bot.cn https://www.fieldguide.io/blog/fieldguide-raises-30m-series-b-launches-ai-platform-to-solve-cpa-talent-shortage Binarly完成1050万美元种子轮融资,Two Bear Capital领投 Binarly,一家提供领先的AI驱动固件及软件供应链安全平台的公司,宣布完成了1050万美元的种子融资轮。这轮融资过度认购,由Two Bear Capital领投,Blu Ventures、Canaan Partners、Cisco Investments和Liquid 2 Ventures等参投。早期投资者Westwave Capital和Acrobator Ventures也扩大了他们的股权份额。Binarly的旗舰产品——Binarly透明度平台,是一个企业级的AI驱动解决方案,通过识别已知和未知的漏洞以及提供恶意代码植入的证据,解决固件和软件供应链安全问题。Binarly将使用这笔投资进一步扩展其世界级工程团队,并扩大其技术在企业和设备制造商中的应用。 公司官网:https://www.binarly.io/ https://inaitoday.com/ai-powered-firmware-security-platform-binarly-closes-10-5-million-seed-round-led-by-two-bear-capital/ Dema.ai完成700万欧元种子轮融资 Dema.ai,一家总部位于瑞典斯德哥尔摩的电商预测分析平台提供商,成功完成了700万欧元的种子轮融资。此轮融资由J12 Ventures、Daphni和一群天使投资者领投。Dema计划利用这笔资金加速其平台的增长。公司由Marcus Tagesson、David Feldell和Henrik Hoffman于2022年创立,旨在为电商公司提供一个平台,通过提供预测性分析来帮助他们掌控未来。 公司官网:https://www.dema.ai/ https://www.finsmes.com/2024/03/dema-raises-e7m-in-seed-funding.html FundGuard完成1亿美元C轮融资,推动AI驱动的投资平台发展 FundGuard,一家以色列初创公司,开发了一款基于云的、由AI驱动、支持多资产类别的投资会计平台,宣布完成1亿美元的C轮融资。本轮融资由Key1 Capital领投,Euclidean Capital和Hamilton Lane管理的基金参投,同时也获得了现有投资者以及公司最早期的财务投资者Blumberg Capital和Team8的支持。这轮融资将主要用于加速平台的增长。FundGuard自成立以来已筹集超过1.5亿美元资金。 公司官网:https://www.fundguard.com/ https://www.calcalistech.com/ctechnews/article/b1dbvkjya
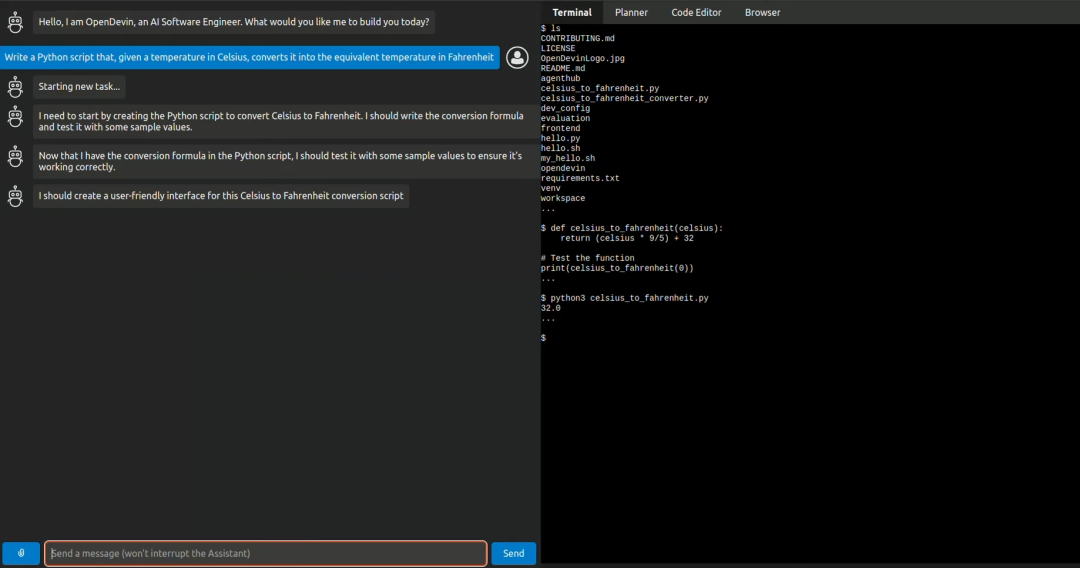
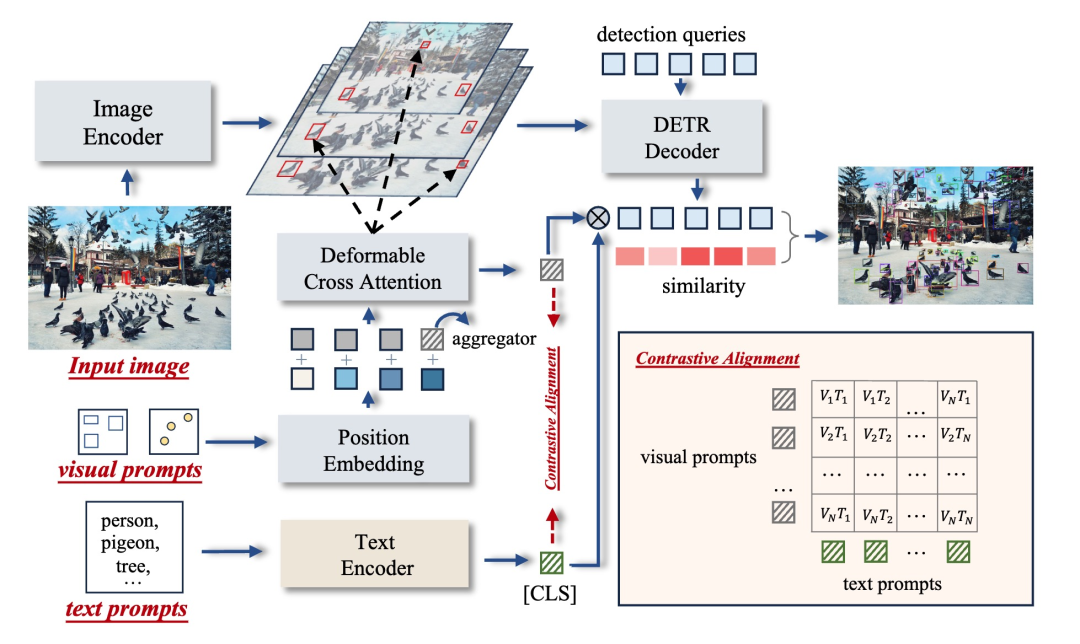
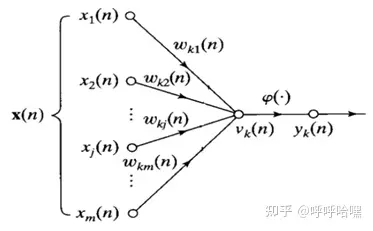
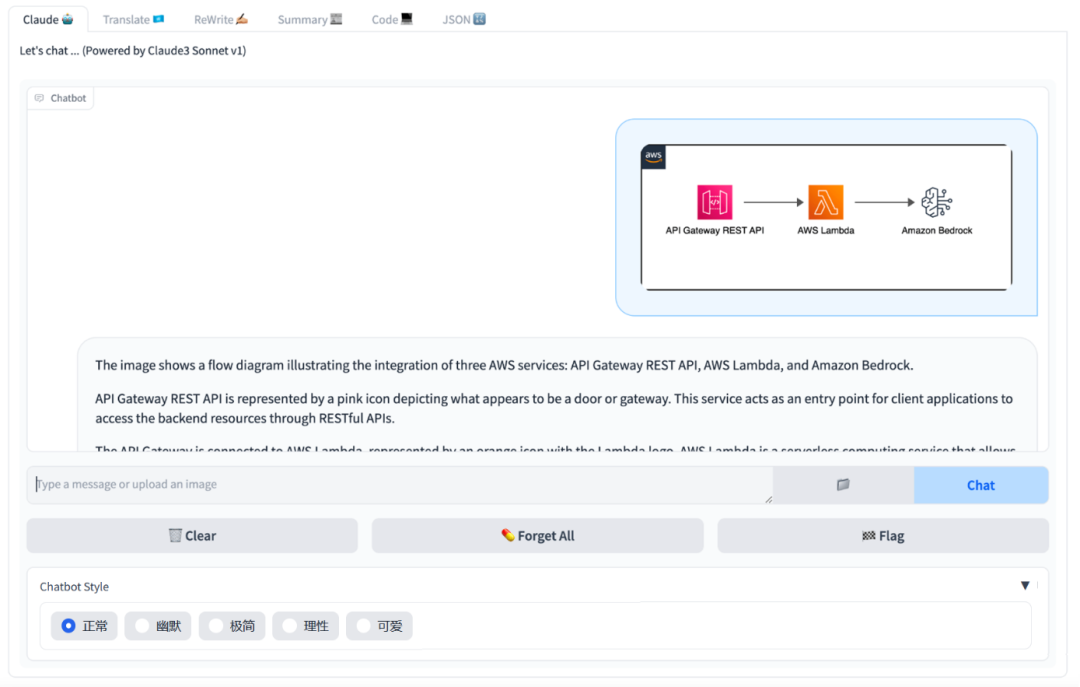
学习 为什么谷歌没能创造出GPT-3 + 为何多模态代理是通往AGI之路 —— Adept的David Luan 文章探讨了谷歌在大型语言模型(LLM)研发上的起步领先却未能制造出GPT-3的原因,以及Adept公司是如何成为AI领域内“最被误解的公司”的。David Luan分享了他在OpenAI和谷歌大脑的经历,及其与Adept一起创建能“做任何人在电脑上能做的事”的代理的过程。Adept的目标是构建一个可以使用现有所有软件工具、API和网络应用的基础模型,作为实现这一宏伟目标的实际路径。文章还讨论了从现有的LLM到建造我们都想要的AGI的过渡,以及如何通过更高层次的“抽象”(即自主性)实现这一目标,同时保持极高的可靠性标准。David Luan强调,通过直接模拟人类的计算机使用行为,而不是依赖API调用,多模态模型是实现这一目标的关键。 https://www.latent.space/p/adept 大白话闲谈Hebbian Learning 作者讨论了Hebbian Learning作为一种基本学习规则在人工智能算法中的应用较少,但近两年出现了一些取得不错效果的相关研究。文章提到了两篇重要论文,并介绍了使用Hebbian Learning的网络能在特定数据集上实现的准确率和特征重构。同时,讨论了传统神经网络训练方法与Hebbian Learning的不同,尤其是在模拟生物学习过程方面的优势。作者还分享了自己设计的Hebbian Learning算法,该算法结合了简单性和速度,旨在提高神经网络的鲁棒性。此外,提出了未来研究方向,包括从数学角度探究算法、提高网络鲁棒性的可能性,以及深度Hebbian算法的开发。 https://zhuanlan.zhihu.com/p/454272138?utm_psn=1756236641365450752 LLM推理加速方式汇总 文章总结了几种提升大型语言模型(LLM)推理速度的技术方法,包括模型量化、模型结构改进、动态批处理和投机推理等。量化技术通过减少模型的数值精度来减少显存占用并加速推理过程,而BF16被推荐为LLM训练和推理的最佳数值类型。模型结构改进如Multi-Query Attention (MQA)和Grouped Query Attention (GQA)旨在通过共享参数或减少参数量来加快推理速度。此外,Flash Attention技术通过优化self-attention计算来实现显著的推理加速,Page Attention通过高效管理内存来提升推理效率。文章提供了对这些技术详细的解释和评估,为LLM的优化提供了有价值的参考。 https://zhuanlan.zhihu.com/p/688736901 图网络表示GE与知识图谱表示KGE的原理对比与实操效果分析 文章深入探讨了图网络嵌入(Graph Embedding, GE)与知识图谱嵌入(Knowledge Graph Embedding, KGE)的原理及其在实际应用中的效果差异。作者通过比较GE和KGE的学习目标、表示方法以及实际训练效果,揭示了两者在处理实体间关系、保留网络结构信息、以及应对异质信息网络方面的不同侧重点。GE更注重捕获网络中的结构信息,而KGE则侧重于建模实体间的显式关系。实验部分,作者使用公开知识图谱数据集,并分别采用DeepWalk和TransE算法进行嵌入学习,展示了两种方法在实际应用中的效果对比,为理解和选择合适的嵌入技术提供了有价值的参考。 https://mp.weixin.qq.com/s/PBDpejpbSvZD4z-ycFQauQ 基于Amazon Bedrock + Claude3快速构建Serverless GenAI应用 本文介绍了如何利用Amazon Bedrock和最新推出的Claude3大语言模型,快速构建和部署Serverless生成式人工智能(GenAI)应用。Claude3支持高达20万token的处理能力,标志着在推理、数学、编程、多语言理解和视觉领域的新突破。Amazon Bedrock服务,被誉为“AI操作系统”,集成了Claude3,提供强大的企业级AI服务。开发者可以通过Gradio库创建交互界面,利用Lambda构建后端逻辑,通过API Gateway提供服务接口,整个方案可通过Amazon CDK一键部署。示例应用AIToolBox展示了Claude3在智能聊天、文本翻译、内容汇总、代码编写、图片识别等多个场景中的应用,展现了其强大的自然语言处理能力。 https://aws.amazon.com/cn/blogs/china/quickly-build-serverless-genai-applications-based-on-amazon-bedrock-and-claude3/ Vinija的大型语言模型(LLM)概览 Vinija.ai提供了对大型语言模型(LLM)的全面概述,深入探讨了它们的工作原理、培训步骤、以及面临的挑战和解决方案。文中详细介绍了LLM的关键特性,如上下文长度扩展、位置编码和稀疏注意力机制。同时,探讨了LLM在处理大量数据时的优化技巧,包括动态缩放的RoPE和多查询注意力等方法。此外,还提到了通过知识图谱增强LLM的方法,以及如何使用提示工程和令牌采样等技术来提高LLM的性能。文章不仅提供了对LLM的深入理解,还探索了其在多种应用场景中的潜力。 http://vinija.ai/models/LLM/
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/03/16618.html