
特别活动


我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。

资讯
百万tokens低至1元!大模型越来越卷了
 https://mp.weixin.qq.com/s/42hA4Ggzu_p4Iqk8yr4VAQ
https://mp.weixin.qq.com/s/42hA4Ggzu_p4Iqk8yr4VAQ人类偏好就是尺!SPPO对齐技术让大语言模型左右互搏、自我博弈论文
 https://mp.weixin.qq.com/s/ulVGoBkCtFyV_mwSBdzgQg
https://mp.weixin.qq.com/s/ulVGoBkCtFyV_mwSBdzgQgDiT架构大一统:一个框架集成图像、视频、音频和3D生成,可编辑、能试玩
 https://mp.weixin.qq.com/s/NwwbaeRujh-02V6LRs5zMg
https://mp.weixin.qq.com/s/NwwbaeRujh-02V6LRs5zMg从零开始手搓GPU,照着英伟达CUDA来,只用两个星期
 https://mp.weixin.qq.com/s/gDWQGs4MyVWqsmONdEqvpQ
https://mp.weixin.qq.com/s/gDWQGs4MyVWqsmONdEqvpQFlash Attention稳定吗?Meta、哈佛发现其模型权重偏差呈现数量级波动
 https://mp.weixin.qq.com/s/sG3JaZR1isZApWP6ZkYe6Q
https://mp.weixin.qq.com/s/sG3JaZR1isZApWP6ZkYe6Q博弈论让 AI 更加正确、高效,LLM 与自己竞争
 https://mp.weixin.qq.com/s/gMUE2eg_B_jl5wCZpQlvjw
https://mp.weixin.qq.com/s/gMUE2eg_B_jl5wCZpQlvjwHeyGen 创始人对话硅谷投资人 Sarah Guo:SaaS 十倍增长背后,Bootstrapping 还是拿融资
推特
Anthropic控制台中现在可以生成提示语啦!
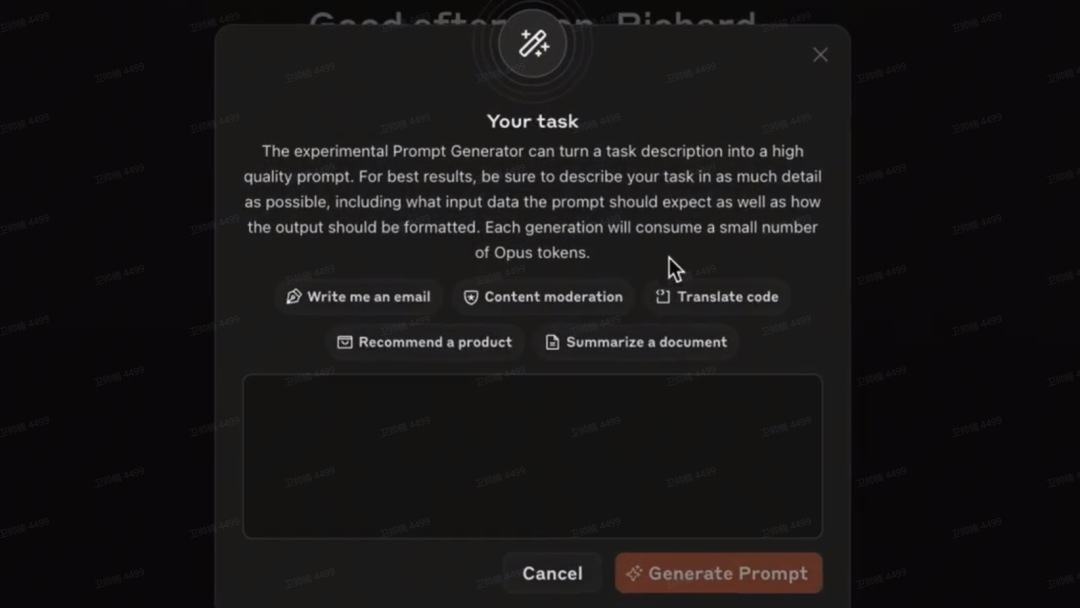 https://x.com/AnthropicAI/status/1788958483565732213
https://x.com/AnthropicAI/status/1788958483565732213
Jim Fan分享思考:我们学习主流神经网络的像素到大脑会怎么样?我们能否拦截人类计算的“思维链”信号?
 https://x.com/DrJimFan/status/1788955845096820771
https://x.com/DrJimFan/status/1788955845096820771
谷歌在Hugging Face发布TimesFM权重
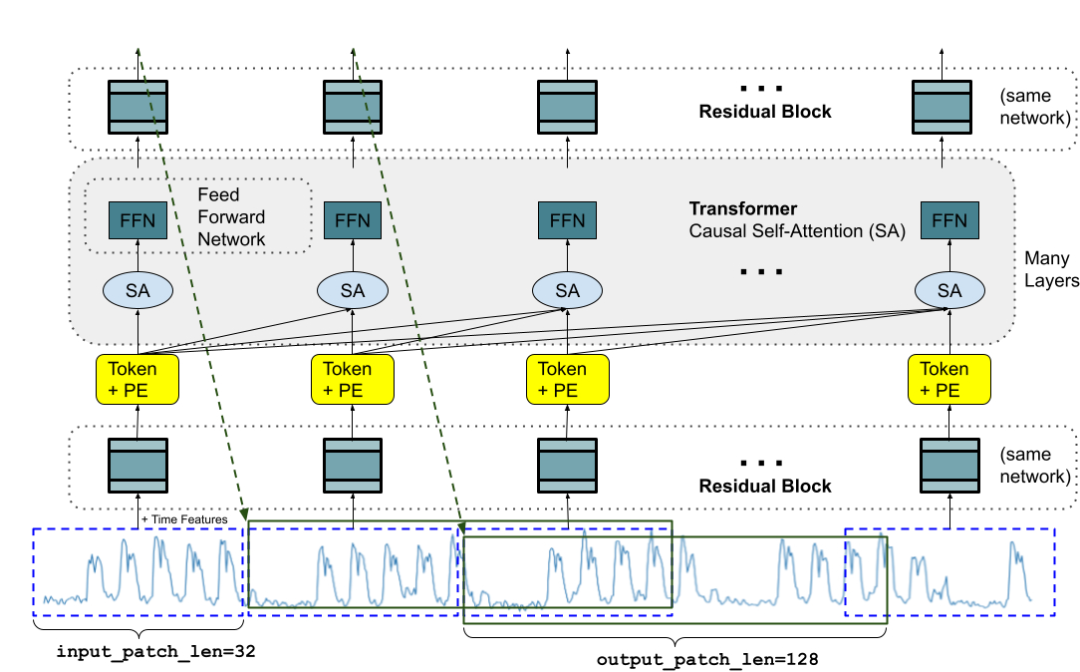 https://x.com/GoogleAI/status/1788972685739114946
https://x.com/GoogleAI/status/1788972685739114946Yohei Nakajima: BabyAGI、人工智能代理与人工智能投资
 https://x.com/OfficialLoganK/status/1789330831321772420
https://x.com/OfficialLoganK/status/1789330831321772420Chip Huyen:人们没有花足够的时间评估他们的评估流程
-
大多数团队使用多于一个的指标(通常是3-7个指标)来评估他们的应用程序,这是一个好的做法。然而,很少有人测量这些指标之间的相关性。
-
许多人(我估计60 – 70%?)使用人工智能评估人工智能的回答,常见的标准包括简洁性、相关性、连贯性、忠实性等。我发现将人工智能作为评判者非常有前景,并期待将来看到更多这样的方法。
 https://x.com/chipro/status/1788972359900389475
https://x.com/chipro/status/1788972359900389475Shunyu Yao分享博士论文答辩:《语言代理:从下一个词预测到数字自动化》
-
演讲(WebShop、SWE-bench、ReAct、ToT、CoALA以及关于代理未来的讨论):https://youtube.com/watch?v=zwfE6J2BIR4 -
论文(内容更加全面):https://ysymyth.github.io/papers/Dissertation-finalized.pdf
 https://x.com/ShunyuYao12/status/1789058769982550031
https://x.com/ShunyuYao12/status/1789058769982550031
谷歌深度学习 Chollet:深度学习模型不能解决训练分布之外的任务,“涌现学习”是不正确的
 https://x.com/fchollet/status/1789082647375090040
https://x.com/fchollet/status/1789082647375090040产品
Wanderboat——你的私人定制旅行伙伴
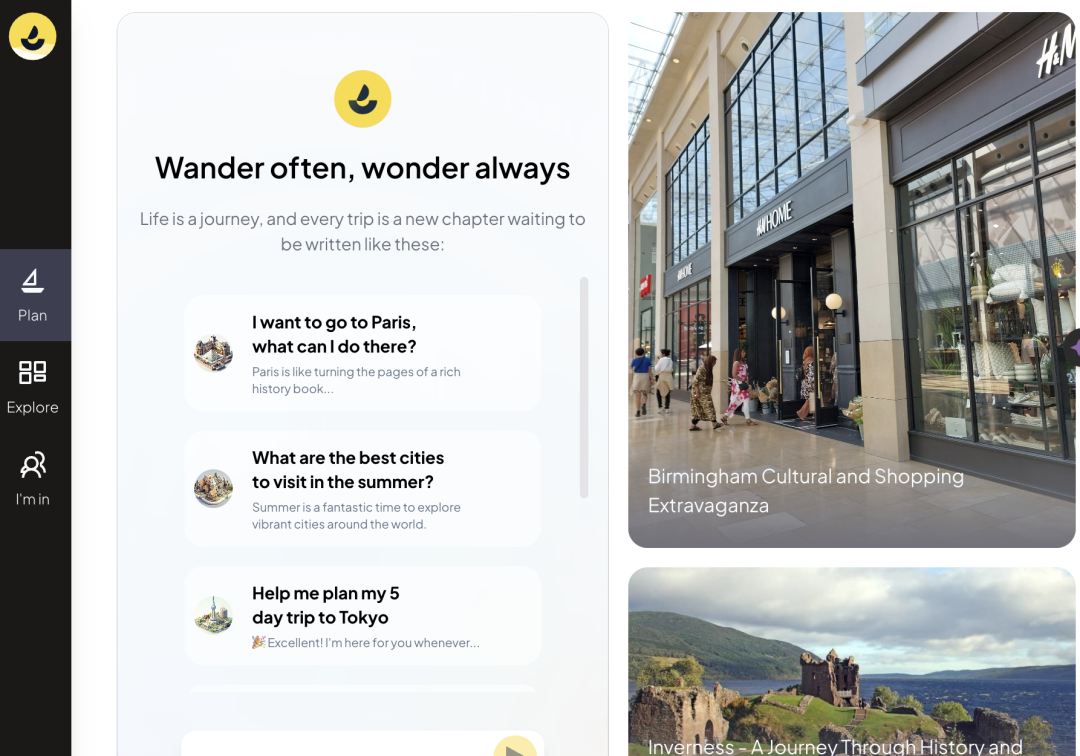 https://wanderboat.ai/
https://wanderboat.ai/Otto——记录生活,高速成长
 https://www.landing.ottowrites.co/
https://www.landing.ottowrites.co/FaceSwap
 https://faceswap.so/
https://faceswap.so/【噗噗故事机】完成数百万元人民币天使轮融资,投资方为「奇绩创坛」
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/05/15455.html