欢迎观看大模型日报 , 如 需 进 入 大 模 型 日 报 群 和 空 间 站 请 直 接 扫 码 。 社 群 内 除 日 报 外 还 会 第 一 时 间 分 享 大 模 型 活 动 。
资 讯 ICLR 2024 | 无需训练,Fast-DetectGPT让文本检测速度提升340倍 大语言模型如 ChatGPT 和 GPT-4 在各个领域对人们的生产和生活带来便利,但其误用也引发了关于虚假新闻、恶意产品评论和剽窃等问题的担忧。本文提出了一种新的文本检测方法 ——Fast-DetectGPT,无需训练,直接使用开源小语言模型检测各种大语言模型生成的文本内容。Fast-DetectGPT 将检测速度提高了 340 倍,将检测准确率相对提升了 75%,成为新的 SOTA。在广泛使用的 ChatGPT 和 GPT-4 生成文本的检测上,均超过商用系统 GPTZero 的准确率。Fast-DetectGPT 同时做到了高准确率、高速度、低成本、通用,扫清了实际应用的障碍! https://mp.weixin.qq.com/s/lp0nIaBfk2cMMQ86NvnjFg
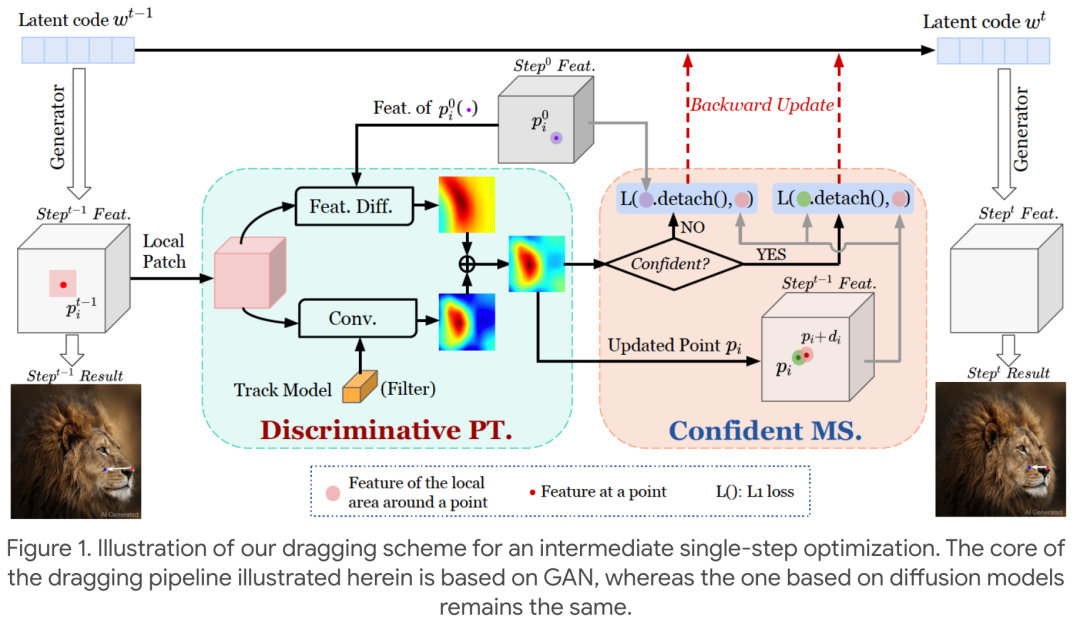
拖拽P图技术又升级了 StableDrag更稳、更准,南大、腾讯联合打造 去年 5 月,动动鼠标就能让图片变「活」得研究 DragGAN吸引了 AI 圈的关注。通过拖拽,我们可以改变并合成自己想要的图像,比如下图中让一头狮子转头并张嘴。实现这一效果的研究出自华人一作领衔的「Drag Your GAN」论文,于上个月放出并已被 SIGGRAPH 2023 会议接收。相关的项目在 GitHub 上已经积累了 34.5k 的 Star 量。之后,新加坡国立大学和字节跳动推出了类似的研究 ——DragDiffusion。他们利用大规模预训练扩散模型,极大提升了基于点的交互式编辑在现实世界场景中的适用性。尽管取得了很大的成功,但类似的拖拽方案存在两个主要缺陷,即点跟踪不准确和动作监督不完整,从而可能导致无法达到满意的拖拽效果。为了克服这些缺陷,南京大学、腾讯的几位研究者提出了一种判别式点跟踪方法并针对动作监督采用了基于置信的潜在增强策略,构建了一个更加稳定和精确的拖拽编辑框架 ——StableDrag。其中判别式点跟踪方法能够精确地定位更新的操纵点,提高长程操纵稳定性;基于置信的潜在增强策略能够在所有操纵步骤中,保证优化的潜在变量尽可能地高质量。
可发现药物靶点,哈佛、Hopkins 中国科学院等机构 基于Transformer开发了一种可对蛋白翻译动态变化建模的深度学习方法 翻译延伸对于维持细胞蛋白质稳态至关重要,并且翻译景观的改变与一系列疾病相关。核糖体分析可以在基因组规模上详细测量翻译。然而,目前尚不清楚如何从这些数据中的技术产物中分离出生物变异,并识别翻译失调的序列决定因素。在最新的研究中,中国科学院、哈佛大学(Harvard University)、斯坦福大学(Stanford University)、约翰霍普金斯大学(Johns Hopkins University)的研究团队开发了 Riboformer,一个基于深度学习的框架,用于对翻译动态中上下文相关的变化进行建模。Riboformer 利用 Transformer 架构,能够以密码子分辨率准确预测核糖体密度。当在无偏数据集上进行训练时,Riboformer 会纠正以前未见过的数据集中的实验伪影,这揭示了同义密码子翻译中的细微差异,并揭示了翻译延伸的瓶颈。研究人员表明 Riboformer 可以与计算机诱变相结合,以识别有助于核糖体在各种生物环境(包括衰老和病毒感染)中停滞的序列基序。
首个AI软件工程师Devin 完整技术报告出炉, 还有人用GPT做出了「复刻版」 文章深入介绍了AI软件工程师Devin和其技术细节,特别是在SWE-bench基准测试中的表现。Devin无需人类辅助,在2294个软件工程问题中解决了13.86%,表现远超当前最先进模型。SWE-bench旨在评估处理真实世界代码库问题的能力,包含问题描述和相应的GitHub拉取请求。Devin通过自动导航文件系统和执行迭代解决方案展现了强大的编码能力,尤其是在逻辑推理和多步骤推导方面。此外,文章还提到社区对Devin的“复刻版”尝试及类似项目BabelCloud,展示了AI在软件开发领域的进步和潜在影响。 https://www.ithome.com/0/755/787.htm产业 马斯克开源Grok-1 3140亿参数迄今最大,权重架构全开放,磁力下载 说到做到,马斯克承诺的开源版大模型 Grok 终于来了。今天凌晨,马斯克旗下大模型公司 xAI 宣布正式开源 3140 亿参数的混合专家(MoE)模型「Grok-1」,以及该模型的权重和网络架构。这也使得Grok-1成为当前参数量最大的开源大语言模型。
没等来OpenAI,等来了Open-Sora全面开源 不久前 OpenAI Sora以其惊人的视频生成效果迅速走红,在一众文生视频模型中突出重围,成为全球瞩目的焦点。继 2 周前推出成本直降 46% 的 Sora 训练推理复现流程后,Colossal-AI 团队全面开源全球首个类 Sora 架构视频生成模型 「Open-Sora 1.0」,涵盖了整个训练流程,包括数据处理、所有训练细节和模型权重,携手全球 AI 热爱者共同推进视频创作的新纪元。
月之暗面Kimi模型升级: 200万字窗口版可申请,新增“继续”功能 继2月以投后约25亿美金估值炸场后,杨植麟的大模型公司月之暗面()终于有了一次公开对媒体的活动。虽然杨植麟本人并未露面,但是发布了更长上下文窗口的版本:200万字上下文版本,今天即刻在Kimi上开启内测。并且在与Kimi对话过程中,加入了(不打断模型思路的)“继续”功能按钮。 https://x.com/svpino/status/1768252265373081912?s=20
消息称英伟达洽购以色列人工智能初创公司Run:AI 据知情人士称,英伟达正在就收购以色列人工智能基础设施编排和管理平台Run:AI进行深入谈判。这笔交易的价值估计在数亿美元,甚至可能达到10亿美元。 https://finance.sina.com.cn/stock/usstock/c/2024-03-18/doc-inansyiy2526325.shtml 推特 韩国媒体报道 Sam Altman透露了有关GPT-5的新细节 他基本上承认GPT-5将是对GPT-4的巨大升级,因此我们可以期待从GPT-3到GPT-4会有类似的飞跃。 “如果你忽视了改进的速度,你将被’碾压’……Altman对GPT-5的性能很有信心,并发出警告。” 【硅谷特派记者群采访】忽视改进幅度导致业务部署过时,GPT模型没有极限地发展,AGI科研仍是可持续经济发展的驱动力。 OpenAI首席执行官Sam Altman警告不要因忽视GPT-5性能改进幅度而产生”创新延迟”,预计其性能将超出预期。他强调,随着GPT下一代模型的开发,需要有更新的思维,取代和抹去各个商业和日常生活领域。这几乎是Altman首席执行官首次对GPT-5的性能表示如此自信的”信号”。他明确表示,构建”通用人工智能(AGI)”是他和OpenAI的目标,暗示如果投入大量计算资源加速AGI的到来,那么目前面临的问题,如AI运作所需的能源危机,都将迎刃而解。 3月14日(当地时间),在与韩国硅谷记者团的会面中,Altman首席执行官提到,”我不确定GPT-5何时会发布,但它将作为在高级推理能力方面实现飞跃的模型取得重大进展。有很多问题是关于GPT是否有任何极限,但我可以自信地说’没有’。”他表示有信心,如果投入足够的计算资源,构建超越人类能力的AGI完全可行。 Altman首席执行官还认为,低估正在开发的GPT-5的改进幅度并相应地部署业务将是一个大错误。这意味着GPT-5的改进幅度超乎想象。他提到,”许多初创公司乐于假设GPT-5只会取得微小进步而不是重大进展(因为这为更多商机敞开大门),但我认为这是个巨大错误。在这种情况下,当技术剧变发生时,它们经常会被下一代模型’碾压’。” 除了”构建AGI”,Altman似乎对其他什么都不感兴趣。他对AI以外的其他技术,包括区块链和生物技术,兴趣似乎已经减退。他说,”过去,我对世界上发生的一切都有广泛的视角,可以看到从狭隘视角看不到的东西。遗憾的是,这些天我完全专注于AI(全速投入AI),很难有其他视角。” 最近,Altman首席执行官一直致力于创新全球AI基础设施,引发”7万亿美元资金”传闻的讨论。他说,”除了思考下一代AI模型,我最近花费大部分时间的领域是’计算建设’,因为我越来越相信计算将成为未来最重要的货币。然而,世界尚未为足够的计算做好计划,如果不直面这一问题,思考如何以尽可能低的成本建设大量计算,将是一个巨大挑战。”这表明对实现AGI所需计算资源的重大担忧。 https://x.com/burny_tech/status/1769549895835226613?s=20
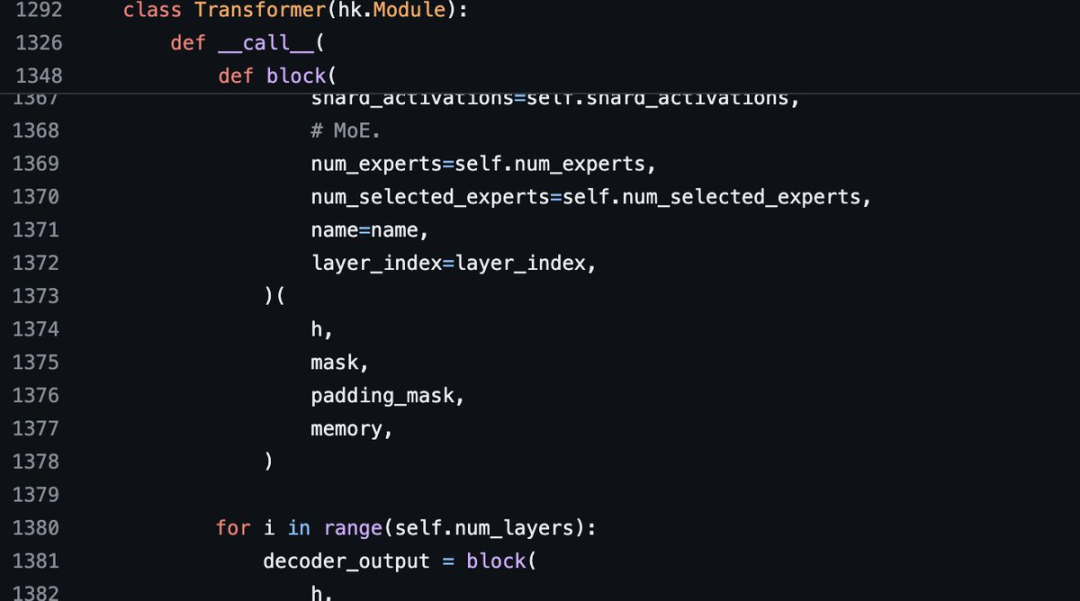
斯坦福Andrew Kean Gao浅析Grok开源 这是对 @grok 架构的深度探索!我刚刚仔细阅读了这个314亿参数的开源巨兽的 model.py 文件,它是完全开放的,没有任何附加条件。
使用 Rotary Embeddings(旋转嵌入,缩写 RoPE)替代固定位置嵌入
分词器(tokenizer)词汇量: 131,072 (与 GPT-4 相似)
每一层都有一个解码器层:包含多头注意力模块(Multihead attention block)和密集模块(denseblock)
查询(queries)有48个头,键/值(keys/values)有8个头
密集模块(dense feedforward block):
旋转位置嵌入(rotary positional embeddings)维度6144,与模型输入嵌入维度一致
提到了一些关于权重的8位量化,但作者本人不是这方面的专家,cc给 @erhartford 征求意见
关注作者 @itsandrewgao 获取更多关于 @grok 的报道
https://x.com/itsandrewgao/status/1769447551374156097?s=20
Daniel Han分析Grok代码 注意力(Attention)按30 * tanh(x/30) 进行缩放
注意力(Attention)按30 * tanh(x/30) 进行缩放?!
使用了4倍的LayerNorm,而Llama只有2倍
RMS LayerNorm在最后进行了向下转换,与Llama不同,但与Gemma相同
我认为RoPE(旋转位置嵌入)完全使用float32,与Gemma一样
QKV(查询-键-值)有偏置(bias),但输出(Output)和MLP没有偏置
词汇表大小为131072,而Gemma为256000。
遗憾的是,它对我来说太大了,无法用@UnslothAI加速微调或运行。70亿参数的Llama可以用Unsloth放入48GB显存中,但Grok将需要太多的GPU资源:( https://x.com/danielhanchen/status/1769550950270910630?s=20 Open Interpreter预告本周四将会有重大宣布 https://x.com/OpenInterpreter/status/1769448726660337875?s=20
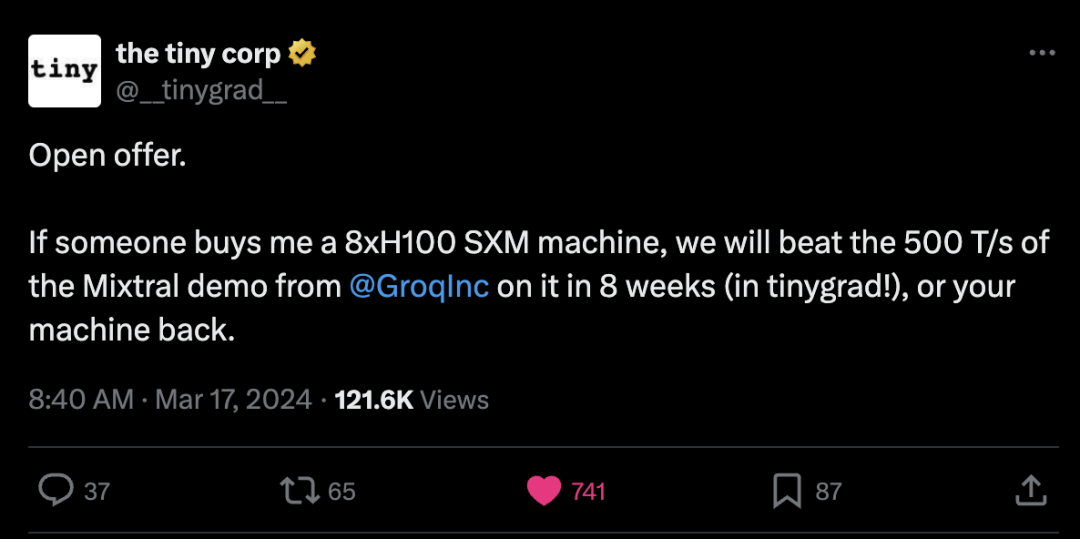
TinyGrad:开放报价 如果购买一台搭载8块H100 SXM GPU的机器 8周内完成超越GroqInc Mixtral演示所达到的500万亿次/秒性能 如果有人愿意为我购买一台搭载8块H100 SXM GPU的机器,我们将在8周内(使用tinygrad!)超越@GroqInc的Mixtral演示所达到的500万亿次/秒(500 T/s)的性能,否则归还机器。 https://x.com/__tinygrad__/status/1769388346948853839?s=20
AutoMerger 自动合并来自 开放大语言模型(Open LLM) 排行榜上的两个随机语言模型 快来看看由@maximelabonne开发的𝐀𝐮𝐭𝐨𝐌𝐞𝐫𝐠𝐞𝐫,这是一个令人着迷的工具,可以自动合并来自开放大语言模型(Open LLM)排行榜上的两个随机语言模型。 它使用@Gradio构建,托管在🤗平台上,仅需10分钟即可在CPU上创建出具有竞争力的模型! https://x.com/Gradio/status/1768606824909922348?s=20
Jensen HuangGTC主题演讲即将开始 Jim Fan:GEAR实验室有一些特别的东西要分享 迫不及待地想看明天Jensen的GTC主题演讲,这是NVIDIA一年中最盛大的节日!一定要坚持到最后!我们新成立的GEAR实验室有一些特别的东西要分享;)您可以在线观看直播或亲自前往SAP中心参加:https://nvidia.com/gtc/keynote h ttps://x.com/DrJimFan/status/1769375386645975077?s=20
论文
Uni-SMART: 通用科学多模态分析和研究Transformer 大语言模型(LLMs)在大型文本数据上的预训练目前已成为标准范例。在许多下游应用中使用这些LLMs时,通常会通过RAG提示或微调来额外融入新知识(如时事新闻或专有领域知识)到预训练模型中。然而,模型获取这些新知识的最佳方法仍是一个未解之谜。本文提出了检索增强微调(RAFT),这是一种训练方法,能够改善模型在“开卷考试”式领域设置下回答问题的能力。在RAFT中,给定一个问题和一组检索到的文档,我们训练模型忽略那些不帮助回答问题的文档,称之为干扰文档。RAFT通过引用相关文档中能够帮助回答问题的正确序列来实现这一点。结合RAFT的思维链式响应方式有助于提高模型的推理能力。在特定领域的RAG中,RAFT在PubMed、HotpotQA和Gorilla数据集上持续改善模型的表现,提出了一个后训练方法来改进预训练的LLMs到领域相关的RAG。RAFT的代码和演示在github.com/ShishirPatil/gorilla中开源。
http://arxiv.org/abs/2403.10301v1
RAFT: 将语言模型调整至特定领域的智能体 大语言模型(LLMs)在大型文本数据上的预训练目前已成为标准范例。在许多下游应用中使用这些LLMs时,通常会通过RAG提示或微调来额外融入新知识(如时事新闻或专有领域知识)到预训练模型中。然而,模型获取这些新知识的最佳方法仍是一个未解之谜。本文提出了检索增强微调(RAFT),这是一种训练方法,能够改善模型在“开卷考试”式领域设置下回答问题的能力。在RAFT中,给定一个问题和一组检索到的文档,我们训练模型忽略那些不帮助回答问题的文档,称之为干扰文档。RAFT通过引用相关文档中能够帮助回答问题的正确序列来实现这一点。结合RAFT的思维链式响应方式有助于提高模型的推理能力。在特定领域的RAG中,RAFT在PubMed、HotpotQA和Gorilla数据集上持续改善模型的表现,提出了一个后训练方法来改进预训练的LLMs到领域相关的RAG。RAFT的代码和演示在github.com/ShishirPatil/gorilla中开源。 http://arxiv.org/abs/2403.10131v1
大型语言模型中快速推理解码的循环起草者 在本文中,我们介绍了一种改进的猜测解码方法,旨在提高为大型语言模型提供服务的效率。我们的方法利用了两种已建立技术的优势:经典的双模型猜测解码方法和较新的单模型方法Medusa。受到Medusa的启发,我们的方法采用了单模型策略进行猜测解码。然而,我们的方法通过采用具有循环依赖设计的单一轻量级草稿头来区别自己,本质上类似于经典猜测解码中使用的小型草稿模型,但不涉及完整Transformer架构的复杂性。由于循环依赖,我们可以使用波束搜索快速过滤掉草稿头中不需要的候选项。其结果是一种结合了单一模型设计简易性的方法,并且避免了只为Medusa中推断而创建数据依赖性树注意结构的需要。我们在几个流行的开源语言模型上经验性地证明了所提方法的有效性,同时全面分析了采用这种方法所涉及的权衡。 http://arxiv.org/abs/2403.09919v1 OverleafCopilot 用大语言模型增强Overleaf中的学术写作 大语言模型(LLMs)的快速发展促进了不同领域的各种应用。在这个技术报告中,我们探讨了LLMs和流行的学术写作工具Overleaf的整合,以提高学术写作的效率和质量。为了实现上述目标,存在三个挑战:i)在Overleaf和LLMs之间实现无缝互动,ii)与LLM提供者建立可靠的通信,iii)确保用户隐私。为了应对这些挑战,我们提出了OverleafCopilot,这是第一个能无缝整合LLMs和Overleaf的工具(即浏览器扩展程序),使研究人员在撰写论文时可以利用LLMs的力量。具体来说,我们首先提出了一个有效的框架来连接LLMs和Overleaf。然后,我们开发了PromptGenius,一个网站让研究人员轻松找到和分享高质量的最新提示。第三,我们提出一个智能体命令系统,帮助研究人员快速构建他们可定制的智能体。OverleafCopilot已经在Chrome扩展商店上架,现在为成千上万的研究人员提供服务。此外,PromptGenius的代码已在https://github.com/wenhaomin/ChatGPT-PromptGenius上发布。我们相信我们的工作有可能彻底改变学术写作实践,赋予研究人员在更短时间内生产出更高质量的论文的能力。 http://arxiv.org/abs/2403.09733v1 Repoformer:基于仓库级代码补全的选择性检索
摘要:最近检索增强生成(RAG)技术在存储库级代码自动补全方面开启了新纪元。然而,现有方法中对检索的不变使用暴露了效率和稳健性问题,其中大部分检索到的上下文对于代码语言模型(code LMs)来说既无帮助又有害。为了应对这些挑战,本文提出了一种选择性RAG框架,当不必要时避免使用检索。为了支持该框架,我们设计了一种自监督学习方法,使代码LM能够准确地自我评估检索是否能提高其输出质量,并能够稳健地利用潜在带有噪音的检索上下文。通过将此LM作为选择性检索策略和生成模型,我们的框架在包括RepoEval、CrossCodeEval和一个新基准测试在内的各种基准测试上始终优于目前最先进的提示技术。同时,我们的选择性检索策略使推理速度提高了多达70%,而并不损害性能。我们展示了我们的框架有效地适应不同的生成模型、检索器和编程语言。这些进步将我们的框架定位为朝着更准确和高效的存储库级代码自动补全迈出的重要一步。 http://arxiv.org/abs/2403.10059v1 AlignmentStudio 将大语言模型与特定上下文规定对齐 大语言模型的对齐通常由模型提供者完成,以添加或控制跨用例和上下文普遍理解的行为。与此相反,在本文中,我们提出了一种方法和架构,赋予应用开发人员调整模型到他们特定的价值观、社会规范、法律和其他法规,并在上下文中协调潜在的冲突要求的能力。我们阐述了这种对齐工作室架构的三个主要组件:Framers、Instructors和Auditors,它们共同控制语言模型的行为。我们通过一个示例说明了这种方法,即将一家公司内部企业聊天机器人与其业务行为准则对齐。 http://arxiv.org/abs/2403.09704v1 投融资 Big Sur AI筹集690万美元并推出电子商务商家的AI销售代理 Big Sur AI,一家面向电子商务的AI平台,宣布完成690万美元种子轮融资,旨在为零售商和品牌简化和普及AI技术的接入。此轮融资由Lightspeed Venture Partners领投,Capital F和多位天使投资人参投。Big Sur AI同时推出旗舰产品——AI销售代理,为网上购物者在商家网站上提供增强的产品发现和辅助购物体验。该公司致力于让每个商家都能轻松享受到AI转型带来的好处。AI销售代理产品现已向所有Shopify平台的商家开放。 https://www.businesswire.com/news/home/20240313840610/en/Big-Sur-AI-raises-6.9M-and-launches-an-AI-Sales-Agent-for-E-commerce-Merchants
9家AI创业公司今日融资超2.6亿美元,涵盖护肤应用领域 据Chief AI Officer在X平台(前Twitter)的消息,今日共有9家AI创业公司宣布融资,总额超过2.6亿美元,其中包括一款针对护肤的AI应用。这次融资活动不仅展示了AI行业的热度,也反映了投资者对于AI技术在多个细分领域应用潜力的认可。特别是在个人护理与美容领域,AI技术的应用开始受到更多关注。此次融资事件是对AI创新公司及其技术潜力的一大肯定,同时也预示着AI技术在不同行业的广泛应用前景。 https://twitter.com/chiefaioffice/status/1768362979748159843 学习 LLM推理阶段 低端低带宽芯片部署策略为什么不首选pipeline parallelism? 页面讨论了低端低带宽芯片在LLM推理阶段部署策略中,为什么不首选pipeline parallelism。主要原因是虽然pipeline parallelism能显著提高Throughput,降低成本,但它会增加Latency,影响用户体验。每个query需要多次卡间传输,这些传输是串行的,无法通过批处理掩盖。因此,尽管pipeline parallelism在理论上看起来有优势,实际部署时需考虑对用户体验的影响。 https://www.zhihu.com/question/646355802/answer/3414841948 Diffusion Model + RL 系列技术科普博客(9) 透过 Diffusion Transformer 探索生成式模型的技术演进 本文探讨了生成式模型技术的演进,特别是基于Transformer架构的扩散模型在图像和视频生成领域的应用。文章通过论文《SiT: Exploring Flow and Diffusion-based Generative Models with Scalable Interpolant Transformers》总结了扩散模型的技术演进,包括理论框架、训练方式、网络设计、采样方式等方面的新进展,并分析了各项背后的数学原理。特别强调了扩散模型在连续时间建模、扩散过程类型、训练方式等方面的创新,展现了生成式模型在模拟和生成复杂数据分布方面的强大能力。 https://zhuanlan.zhihu.com/p/686979830 LoRA及其变体概述:LoRA, DoRA, AdaLoRA, Delta-LoRA
本文介绍了LoRA(低秩自适应)及其变体技术,这些技术用于高效训练大型语言模型(LLM)。LoRA通过引入两个小矩阵A和B来减少训练参数,从而降低资源消耗。文章还探讨了LoRA+、VeRA、LoRA-FA、LoRA-drop、AdaLoRA、DoRA和Delta-LoRA等变体,它们通过不同方式优化了原始LoRA方法,如调整学习率、使用随机权重矩阵、冻结矩阵、基于重要性剪枝参数等,以提高模型性能和训练效率。这些技术在减少参数数量的同时,力求保持或接近完全微调的性能。
https://mp.weixin.qq.com/s/-_JqRklaRI9bD_6QQGKrjg
如何评价Meta最新的推荐算法论文 统一的生成式推荐第一次打败了分层架构的深度推荐系统?
Meta的最新推荐算法论文提出了一种统一的生成式推荐系统,该系统首次超越了分层架构的深度推荐系统。这项技术通过将用户画像、行为和目标信息整合到超长序列中,并结合多层Transformer进行建模,实现了更强的特征交叉能力和更充分的信息利用。此外,新模型引入了更丰富的用户行为信号和更强的序列建模能力,同时优化了在线推理和算力成本。论文还探讨了大型语言模型(LLM)的scaling law现象,以及在推荐系统中可能的算力和数据集规模的同步增长需求。
https://www.zhihu.com/question/646766849?utm_psn=1751997337646608384 LLM推理加速(三):AWQ量化 文章讨论了大型语言模型(LLM)的推理加速问题,特别是通过AWQ量化技术来减少模型权重文件的大小和显存占用。AWQ量化识别并保护了对模型效果贡献最大的1%的关键权重,通过激活分布来识别这些权重。为了减少量化误差,AWQ提出了先放大关键权重再进行量化的方法,并通过数学证明展示了这种方法的有效性。此外,AWQ还根据权重的激活幅值来调整放大系数,以进一步保护更重要的权重。这种方法有助于在保持模型性能的同时,提高推理效率。 https://zhuanlan.zhihu.com/p/685867596?utm_psn=1751997059807211520
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/03/16807.html



 https://mp.weixin.qq.com/s/lp0nIaBfk2cMMQ86NvnjFg
https://mp.weixin.qq.com/s/lp0nIaBfk2cMMQ86NvnjFg