
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


资讯
vLLM v0.6.0
-
性能瓶颈分析
-
CPU开销过高:使用Python原生数据结构导致调度和数据准备时间过长,占用大量CPU资源。 -
缺乏异步处理:许多组件(如调度器和输出处理器)以同步方式执行,导致GPU等待CPU,降低了GPU利用率。
-
性能优化措施
-
API服务器与推理引擎分离:通过ZMQ套接字连接,将API服务器和推理引擎分离,避免了Python全局解释器锁(GIL)的竞争,提高了并行处理效率。 -
多步调度:批量调度多个步骤,减少CPU与GPU之间的等待时间,增加了GPU的使用时间,从而提升了吞吐量。 -
异步输出处理:通过将输出处理与GPU计算并行化,减少了GPU空闲时间,提高了整体性能。
-
其他优化
-
性能基准测试
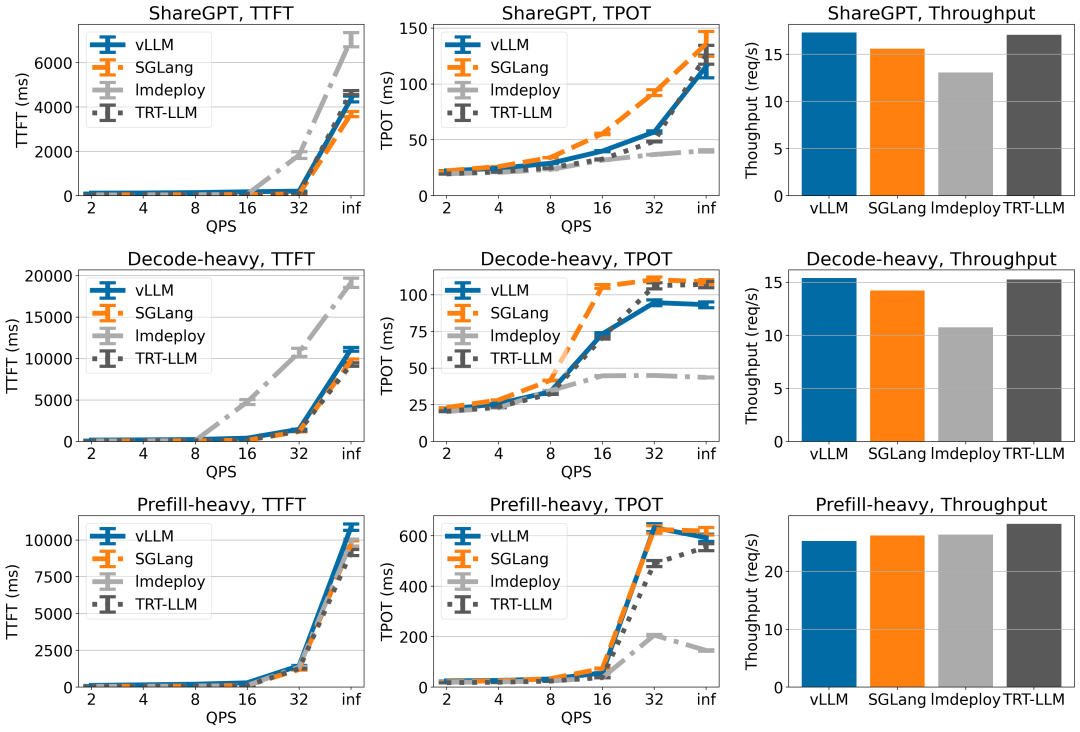 https://blog.vllm.ai/2024/09/05/perf-update.html
https://blog.vllm.ai/2024/09/05/perf-update.html全球首个多语言 ColBERT:Jina ColBERT V2 和它的‘俄罗斯套娃’技术
-
多语言支持:Jina-ColBERT-v2 支持多达 89 种语言,包括阿拉伯语、中文、俄语、编程语言等,提升了全球范围内的检索性能。其训练数据集覆盖了 4.5 亿对语义相关句子和问答对,使得模型能够在多语言和跨语言任务中表现优异。 -
输出维度可定制:引入了“俄罗斯套娃表征学习 (MRL)”技术,允许用户选择 128、96 和 64 维度的输出向量。尽管向量缩短了 50%,性能损失仅在 1.5% 以内,显著减少了存储需求并加速了检索计算,尤其在向量比对和距离计算中效果显著。 -
性能提升:与原始 ColBERT-v2 和 Jina-ColBERT-v1-en 相比,Jina-ColBERT-v2 的英语检索性能分别提升了 6.5% 和 5.4%。其在 MIRACL 基准测试中的表现显著优于传统 BM25 方法,展现了其多语言检索的优越性。
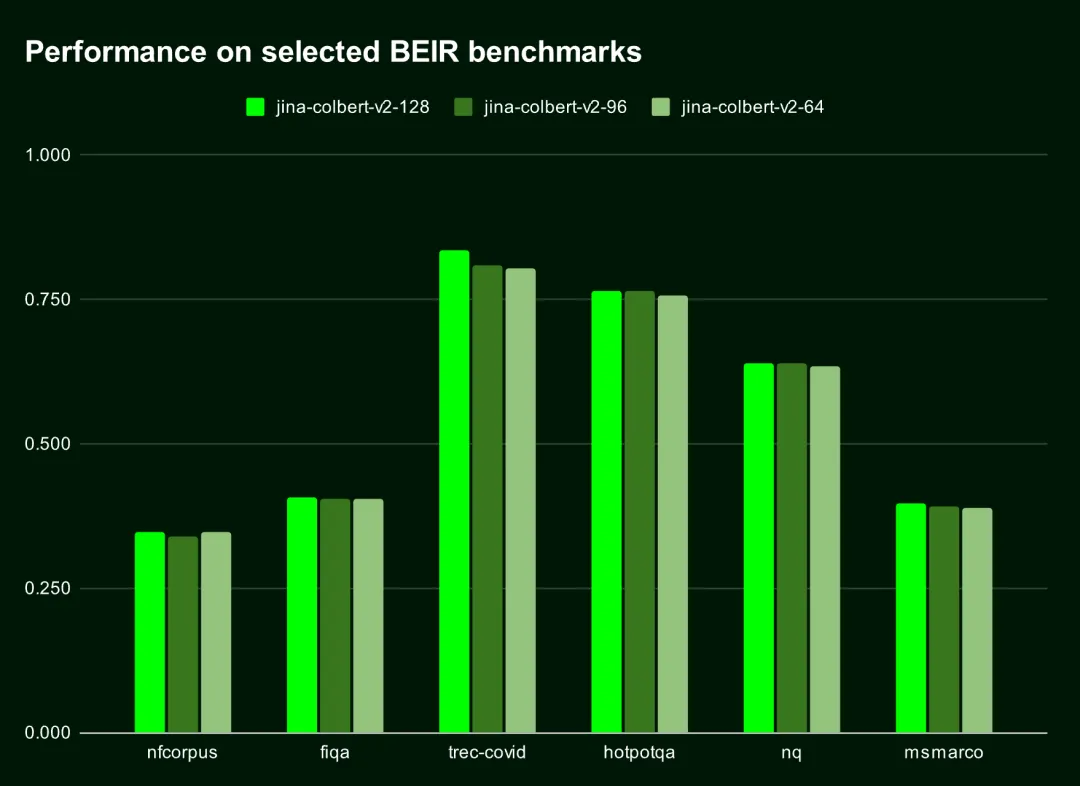 https://mp.weixin.qq.com/s/2U2dK3fppHNnE6dvET3Qhg
https://mp.weixin.qq.com/s/2U2dK3fppHNnE6dvET3Qhg忙碌海狸难题突破:业余爱好者攻克40年计算机科学难题
 https://mp.weixin.qq.com/s/nftONaTaGTbZVEjIgQy3OQ
https://mp.weixin.qq.com/s/nftONaTaGTbZVEjIgQy3OQ开源大模型Reflection 70B
 https://mp.weixin.qq.com/s/NpOUZXjEtZnDPmESA38lwg
https://mp.weixin.qq.com/s/NpOUZXjEtZnDPmESA38lwgAI行业迷恋Chatbot Arena,但它可能不是最佳基准测试工具
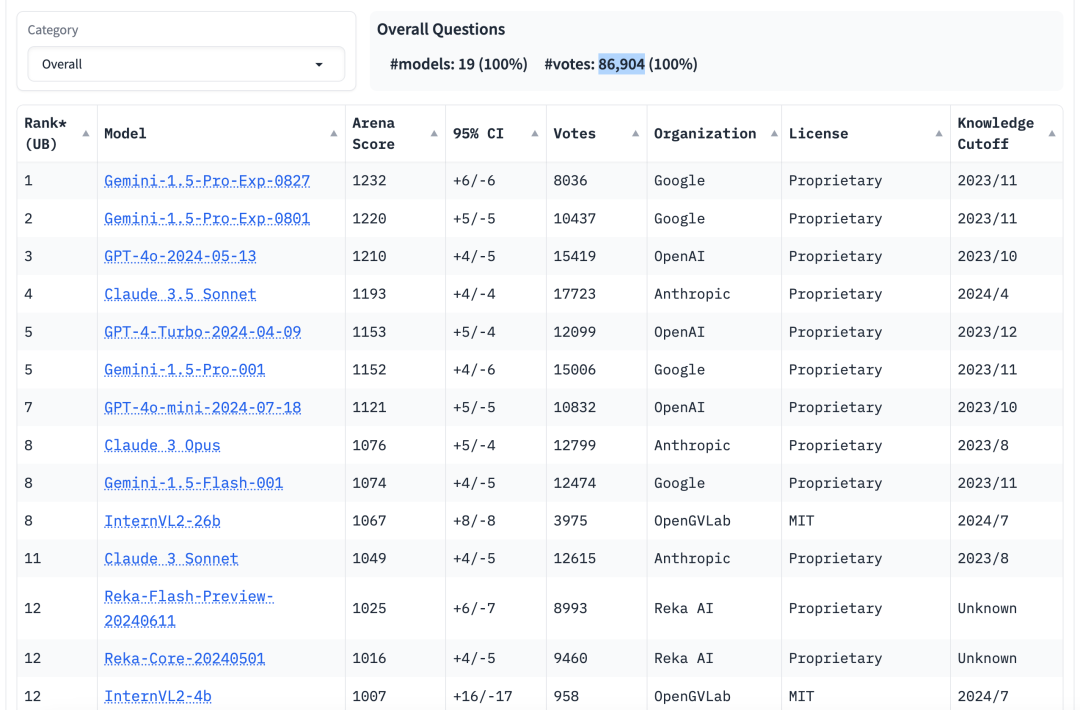 https://techcrunch.com/2024/09/05/the-ai-industry-is-obsessed-with-chatbot-arena-but-it-might-not-be-the-best-benchmark/
https://techcrunch.com/2024/09/05/the-ai-industry-is-obsessed-with-chatbot-arena-but-it-might-not-be-the-best-benchmark/推特
Replit Agent的早期访问开放,Karpathy:完全可以归类到“感受AGI”类别中
 https://x.com/karpathy/status/1831776835388285347
https://x.com/karpathy/status/1831776835388285347
吴恩达发布AI Python for Beginners最后两门课程,限时免费开放
 https://x.com/AndrewYNg/status/1831346457854771255
https://x.com/AndrewYNg/status/1831346457854771255Anthropic AI三位顶尖工程师小圆桌:什么样的人是优秀的提示工程师等
-
什么样的人是优秀的提示工程师 -
编写更好提示的实用技巧 -
大型语言模型(LLM)内部的工作原理 -
破解限制(jailbreaks) -
提示工程的未来 -
以及更多内容
 https://x.com/AnthropicAI/status/1831779476369486094
https://x.com/AnthropicAI/status/1831779476369486094Khalusova分享:如何通过合成生成的评估数据集和指标,快速在非结构化数据上比较嵌入模型
 https://x.com/mariaKhalusova/status/1831309176988922253
https://x.com/mariaKhalusova/status/1831309176988922253产品
Toypal
 https://www.toypal.ai/
https://www.toypal.ai/Sobrief
 https://sobrief.com/
https://sobrief.com/投融资
穹彻智能已完成天使轮和Pre-A轮融资
 https://mp.weixin.qq.com/s/RJPNAlLwKpIspIzHYnZxig
https://mp.weixin.qq.com/s/RJPNAlLwKpIspIzHYnZxig原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/09/13087.html