
欢迎观看大模型日报,如需进入大模型日报群和空间站请直接扫码。社群内除日报外还会第一时间分享大模型活动。


推特
Mistral-22B-v0.2 发布,使用8倍以上的训练数据,在处理用户查询方面明显更好
 https://x.com/mejia_petit/status/1779131534269673556
https://x.com/mejia_petit/status/1779131534269673556Karpathy llm.c更新:从比PyTorch慢4.2倍提升到只慢2倍
-
在矩阵乘法中使用TF32(NVIDIA TensorFLoat-32)而不是FP32。这是从Ampere+开始的GPU中的一种新的数学模式。这是一个非常好的、几乎免费的优化,通过在张量核心上运行矩阵乘法,同时将尾数截断到只有10位(浮点数的最低有效19位会丢失),以牺牲一点精度来换取大幅提高性能。因此,输入、输出和内部累加保持在fp32中,但乘法的精度较低。相当于PyTorch的 torch.set_float32_matmul_precision('high')。 -
调用cuBLASLt API而不是cuBLAS进行sGEMM(fp32矩阵乘法),因为这允许你将偏置融合到矩阵乘法中,并消除了对单独的add_bias内核的需求,从而避免了对全局内存进行一次愚蠢的往返只为了一次加法。 -
一个更高效的注意力内核,它使用1)cooperative_groups reduction,看起来更简洁,我也是最近才了解到的(CUDA PMP书中没有涉及到…);2)flash attention中使用的在线softmax算法;3)融合的注意力缩放因子乘法;4)”内置”的自回归掩码边界。(非常感谢GitHub上的ademeure、ngc92和lancerts编写/帮助这些内核!)
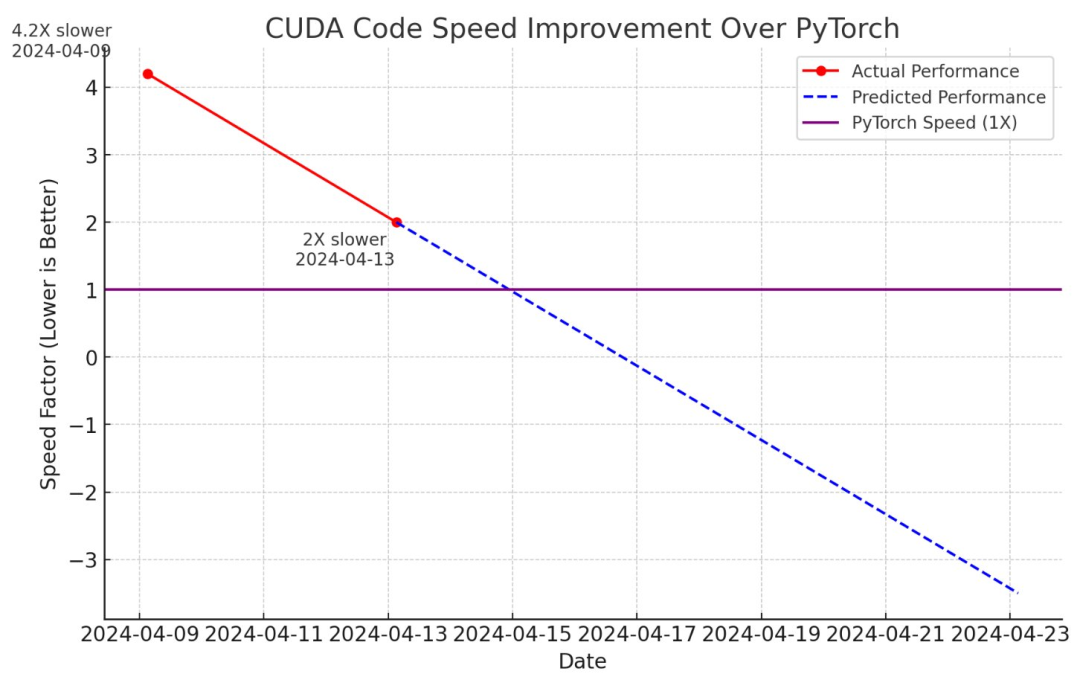 https://x.com/karpathy/status/1778988957713477778
https://x.com/karpathy/status/177898895771347777818小时后的更新:降到26.2ms/迭代,与PyTorch完全相同。只用大约2,000行C代码就能比PyTorch更快地训练LLM,这似乎触手可及
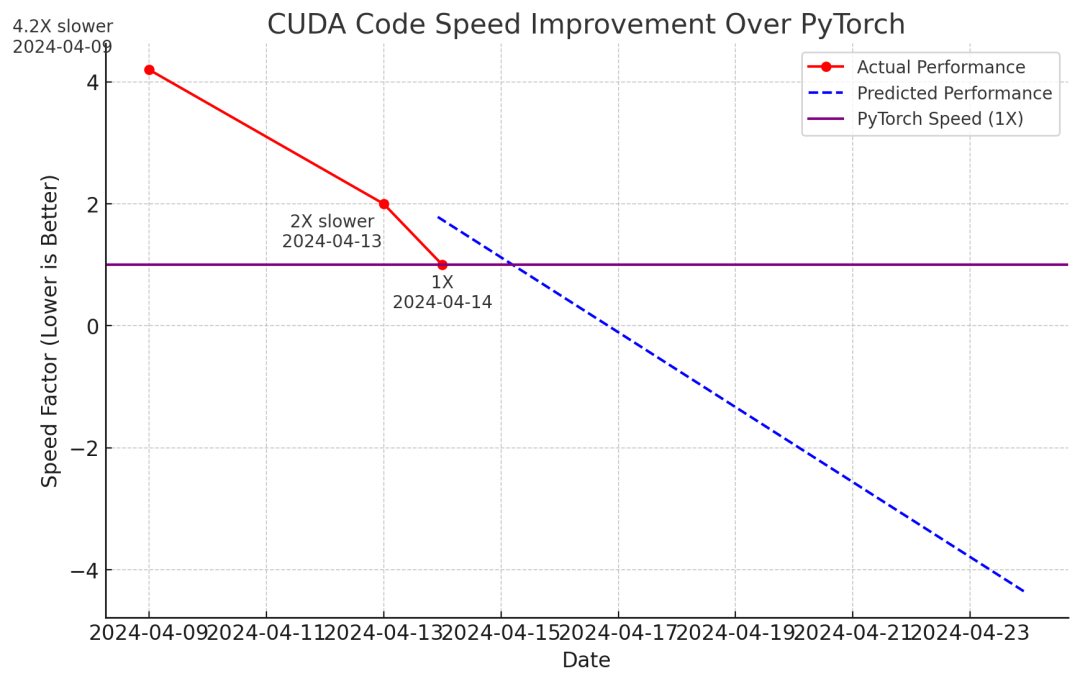 https://x.com/karpathy/status/1779272336186978707
https://x.com/karpathy/status/1779272336186978707PyTorch的复仇,大约20%的加速
 https://x.com/karpathy/status/1779354343013269929
https://x.com/karpathy/status/1779354343013269929Virat分享现在用的RAG stack:Cohere、Weaviate、Opus
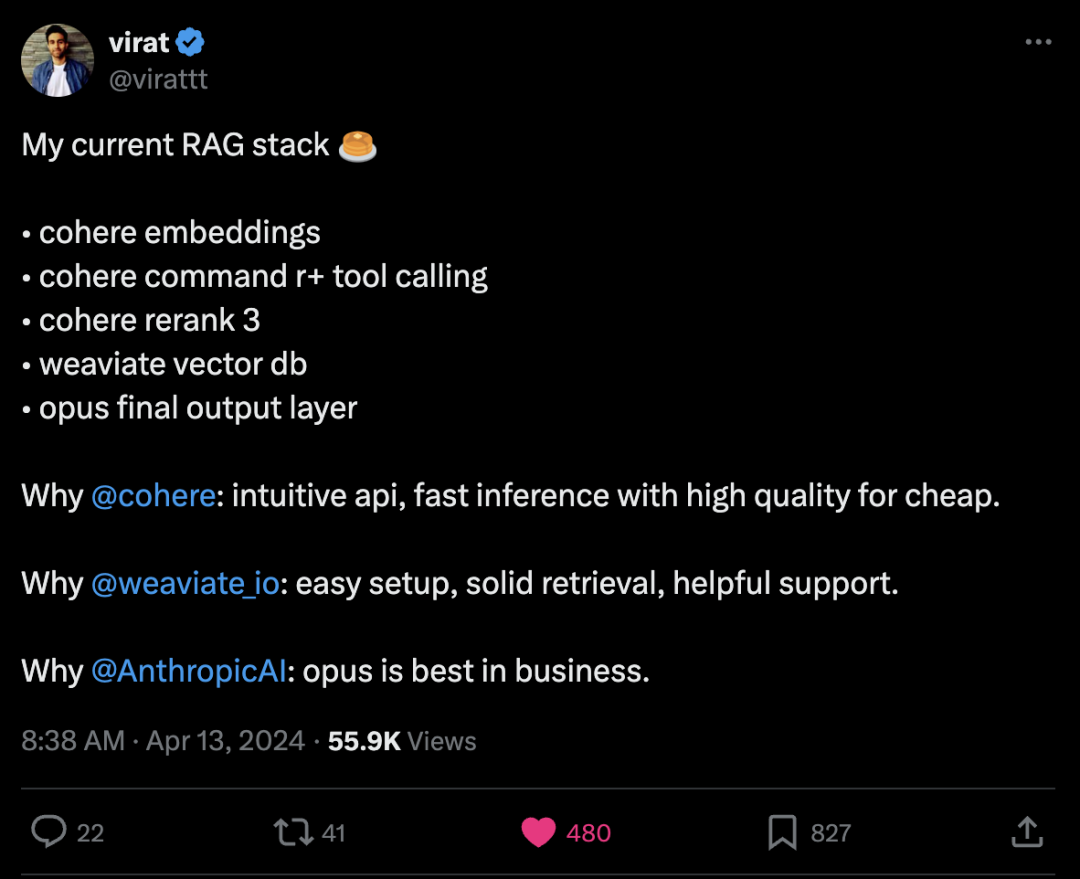 https://x.com/virattt/status/1779172358760075591
https://x.com/virattt/status/1779172358760075591Roemmele分享开源Gemini 智能体示例
 https://x.com/BrianRoemmele/status/1779158342642131077
https://x.com/BrianRoemmele/status/1779158342642131077Arnold谈美国大学强制性标准化成绩:LLM已经完全降低了论文部分作为可靠衡量标准的价值
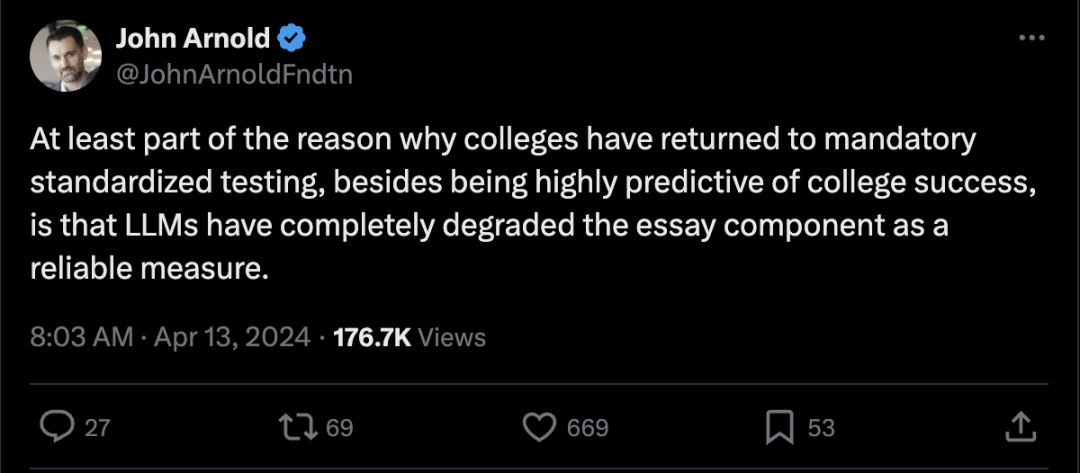 https://x.com/JohnArnoldFndtn/status/1779163497802174833
https://x.com/JohnArnoldFndtn/status/1779163497802174833musicgen-songstarter-v0.2:这是一个大型立体声MusicGen模型,体积是1.0的2倍
 https://x.com/_nateraw/status/1778901598254624830
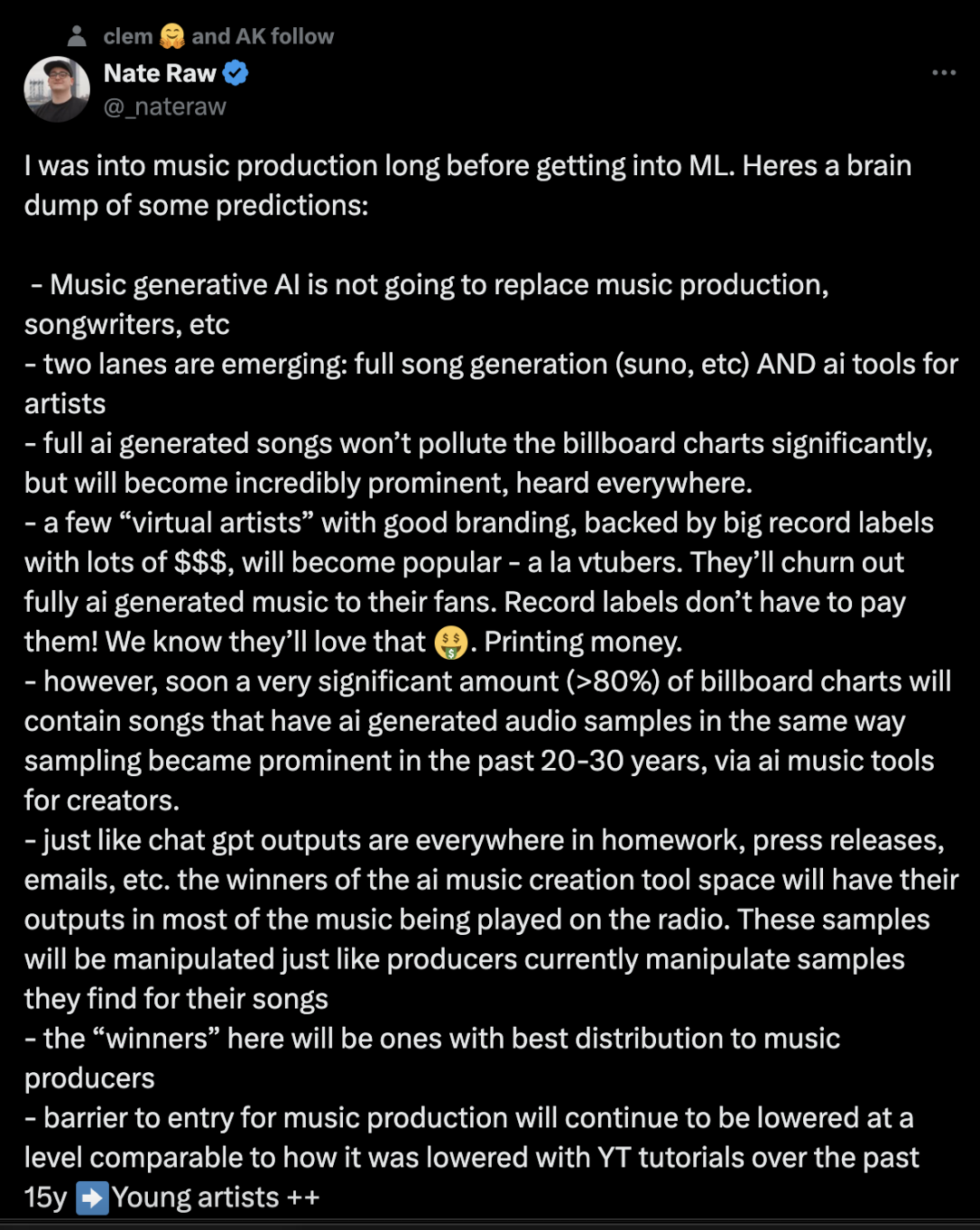
https://x.com/_nateraw/status/1778901598254624830musicgen作者Nate Raw预测AI音乐未来:不会取代音乐唱作,会分完整歌曲生成和专供艺术家
-
音乐生成AI不会取代音乐制作、词曲创作等 – 正在形成两条路线:完整歌曲生成(如suno等)和为艺术家提供的AI工具。 -
完全由AI生成的歌曲不会显著污染公告牌排行榜,但会变得非常突出,无处不在。 -
少数拥有良好品牌、由大唱片公司大笔资金支持的”虚拟艺人”将会流行起来,类似虚拟主播。他们将为粉丝制作全AI生成的音乐。唱片公司不需要付钱给他们!我们知道他们会喜欢这一点。就像印钞票一样。 -
然而,很快公告牌排行榜上相当一部分(>80%)的歌曲将包含AI生成的音频样本,就像过去20-30年通过为创作者提供的AI音乐工具,采样变得突出一样。 -
就像聊天GPT的输出无处不在,出现在作业、新闻稿、电子邮件等中一样。AI音乐创作工具领域的赢家,他们的作品将出现在收音机播放的大部分音乐中。这些样本将像制作人目前操纵他们为歌曲找到的样本一样被操纵。 -
这里的”赢家”将是那些在音乐制作人中分布最广的人 – 音乐制作的进入门槛将继续降低,就像过去15年YouTube教程降低门槛的程度一样。年轻艺术家会大大受益。 -
音乐领域的开放和封闭模型之间的差距将比LLM更大。我希望我是错的,但不幸的是,版权问题更加棘手,这激励人们将他们在未经许可的数据上训练的模型权重保持封闭,以避免被可怕的顶级唱片公司律师攻击。
 https://x.com/_nateraw/status/1779246493351756058
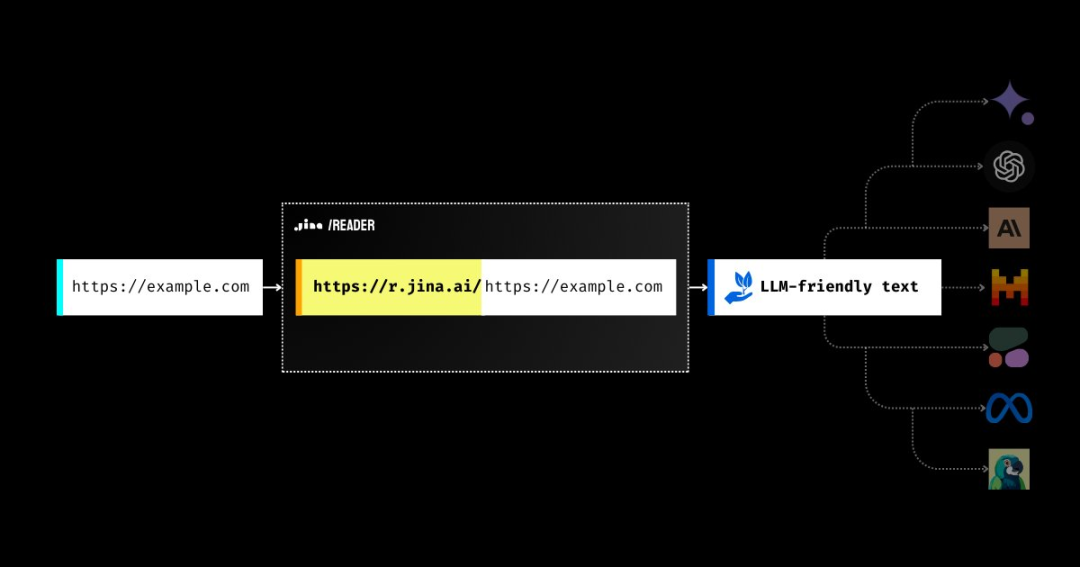
https://x.com/_nateraw/status/1779246493351756058Jina AI开源网页数据爬取
1. 在 https://r.jina.ai<url> 中填入任何 Url 即可获取到 LLM 友好的 Parsed Content( Markdown)
2. 免费使用,提供 Stream 模式可流式读内容(简单内容 <=2s 可获取)
 https://x.com/tuturetom/status/1779377811905769960
https://x.com/tuturetom/status/1779377811905769960Shawn Wang分享:Devin,OpenDevin,和SWE-Agent之战
-
用Rust编写了一个斐波那契生成器。 -
根据给定的任务写了一个睡前故事。 -
构建了一个基于React和Chakra UI的Docker CLI,取代了Docker桌面版。 -
编写了一个简单的Golang工作流,用于在特定条件下发送电子邮件。
-
最初在为Apple Silicon Mac进行交叉编译时遇到困难。 -
在预提交钩子linting方面遇到困难。
-
优点: -
界面精美,用户友好,带有聊天窗口进行交互和计划可视化。 -
强大的功能,包括网络浏览、代码生成和执行。 -
能够根据用户反馈进行调整和重新规划。 -
缺点: -
专有工具,访问受限。 -
有时可能很慢,特别是在处理复杂任务时。
-
优点: -
开源,任何人都可以访问。 -
在代码生成和执行方面表现出前景。 -
用户友好的界面,有改进的潜力。 -
缺点: -
开发处于早期阶段,存在安装挑战和依赖问题。 -
关键的网络浏览功能在直播期间无法使用。
-
优点: -
开源,专注于GitHub问题解决。 -
展示了创建PR和与GitHub交互的能力。 -
与Devin和OpenDevin相比,效率和速度相对较快。 -
缺点: -
功能有限,只专注于GitHub问题。 -
缺乏用户友好的界面,依赖命令行交互。 -
在更复杂的任务和迭代开发过程中遇到困难。 -
文档可以改进,以提高清晰度和易用性。
 https://x.com/swyx/status/1778641185193730488
https://x.com/swyx/status/1778641185193730488资讯
马斯克的首款多模态大模型来了,GPT-4V又被超越了一次
 https://mp.weixin.qq.com/s/2GDjZS6ctayAF8e8eFb3CQ
https://mp.weixin.qq.com/s/2GDjZS6ctayAF8e8eFb3CQAnthropic CE0 表示领先的人工智能模型的成本将很快上升到 100 亿美元
 https://the-decoder.com/anthropic-ceo-believes-leading-ai-models-will-soon-cost-up-to-ten-billion-dollars/
https://the-decoder.com/anthropic-ceo-believes-leading-ai-models-will-soon-cost-up-to-ten-billion-dollars/木头姐 ARK 宣布已投资 OpenAI!还将 Anthropic 及 Figure1 等 AI 独角兽一网打尽
 https://mp.weixin.qq.com/s/lE7zTnVeFfI1wcDfvkVauw
https://mp.weixin.qq.com/s/lE7zTnVeFfI1wcDfvkVauwTier1 厂商麦格纳宣布采用 Sanctuary AI 人形机器人参与汽车制造
 https://mp.weixin.qq.com/s/nzuGNBLFKfNonBb_Y4Wcuw
https://mp.weixin.qq.com/s/nzuGNBLFKfNonBb_Y4Wcuw首个AI程序员造假被抓,Devin再次“震撼”硅谷!扒皮视频文字详解附上
 https://mp.weixin.qq.com/s/898TBRvqFwhBVfI3SPdxyA
https://mp.weixin.qq.com/s/898TBRvqFwhBVfI3SPdxyAGPT超越扩散、视觉生成Scaling Law时刻!北大&字节提出VAR范式
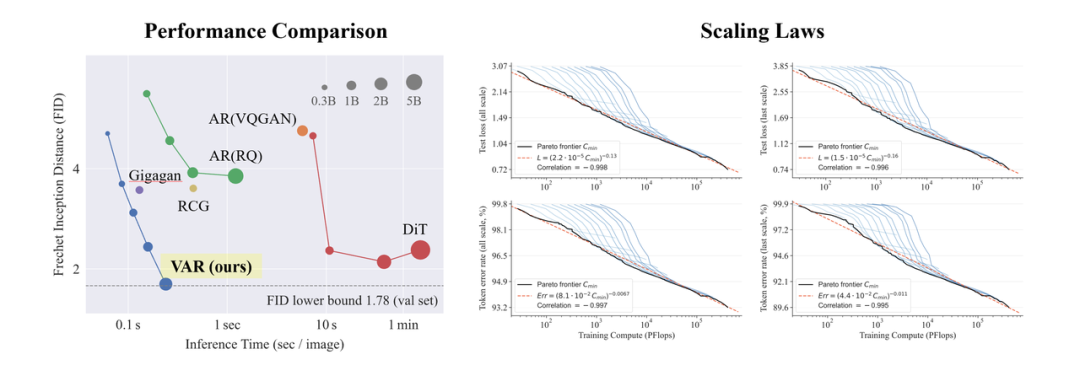 https://mp.weixin.qq.com/s/KOEdTgJX4Gga5zRbl57Yow
https://mp.weixin.qq.com/s/KOEdTgJX4Gga5zRbl57Yow曾爆火的 InstantID又有了新玩法:风格化图像生成,已开源
 https://mp.weixin.qq.com/s/CP6NFzzt57YZMj4Q3JNySA
https://mp.weixin.qq.com/s/CP6NFzzt57YZMj4Q3JNySA全球AI顶会NeurlPS开始收高中生论文了
 https://mp.weixin.qq.com/s/Uctt64AT7oeWtZPLmZqxVQ
https://mp.weixin.qq.com/s/Uctt64AT7oeWtZPLmZqxVQOpenAI推销ChatGPT to B业务,微软客户也是目标
微软作为 OpenAI 的最大投资者,去年开始已通过其 Azure 云和销售 Microsoft 365 Copilot(一种由 OpenAI 面向企业的模型提供支持的生产力工具)的方式提供了对 OpenAI 先进大模型技术的访问。
 https://mp.weixin.qq.com/s/86nAqCu84lC_aDCe9_R8dw
https://mp.weixin.qq.com/s/86nAqCu84lC_aDCe9_R8dwCVPR 2024 | 仅需文本或图像提示,新框架CustomNeRF精准编辑3D场景
 https://mp.weixin.qq.com/s/5Lw5iwSHxJxeqPJYEa3KZw
https://mp.weixin.qq.com/s/5Lw5iwSHxJxeqPJYEa3KZw谁说大象不能起舞! 重编程大语言模型实现跨模态交互的时序预测 | ICLR 2024
 https://mp.weixin.qq.com/s/K04haPMcbKiS6OkCihXAqQ
https://mp.weixin.qq.com/s/K04haPMcbKiS6OkCihXAqQ除了唱歌,AI还能替你演出?又一AI公司将虚拟人推到新高度
最近,一家名为 AKOOL的 AI 公司推出了一个唱歌虚拟人工具,用户只需在平台上选择虚拟人,简单输入歌词指令,便可生成能唱歌的虚拟人 MV。视频中的 “歌手” 在雪地里随着音乐翩翩起舞,“假唱” 对口型也毫不逊色。
 https://mp.weixin.qq.com/s/gSg1JRosqPnX86wAUEzg0A
https://mp.weixin.qq.com/s/gSg1JRosqPnX86wAUEzg0A产品
eezyCollab
 https://www.eezycollab.com/
https://www.eezycollab.com/chatslide.ai
用AI帮企业跑通财税服务全流程,「创业爸爸」获1000万元融资
 https://36kr.com/p/2729877214045447
https://36kr.com/p/2729877214045447Prem Labs获得1400万美元种子轮融资,用于AI模型创新
 https://www.techcompanynews.com/prem-labs-secures-14m-seed-funding-for-ai-model-innovation/
https://www.techcompanynews.com/prem-labs-secures-14m-seed-funding-for-ai-model-innovation/前Intel高管创立的Lumana获得2400万美元种子轮融资
 https://www.calcalistech.com/ctechnews/article/ryny02cyc?utm_
https://www.calcalistech.com/ctechnews/article/ryny02cyc?utm_
大模型日报16
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/04/16093.html