
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


论文
Yuan 2.0-M32:带有注意路由器的专家混合
 http://arxiv.org/abs/2405.17976v1
http://arxiv.org/abs/2405.17976v1数据集增长
 http://arxiv.org/abs/2405.18347v1
http://arxiv.org/abs/2405.18347v1语言崩溃:(大型) 语言模型中的神经崩溃
 http://arxiv.org/abs/2405.17767v1
http://arxiv.org/abs/2405.17767v1超越固定训练时长的训练的缩放规律和计算优化
 http://arxiv.org/abs/2405.18392v1
http://arxiv.org/abs/2405.18392v1预训练Transformer中的知识回路
 http://arxiv.org/abs/2405.17969v1
http://arxiv.org/abs/2405.17969v1渐进一致性模型
 http://arxiv.org/abs/2405.18407v1
http://arxiv.org/abs/2405.18407v1SMR:状态记忆重放用于长序列建模
 http://arxiv.org/abs/2405.17534v1
http://arxiv.org/abs/2405.17534v1学习物理定律的下一帧预测的力量
 http://arxiv.org/abs/2405.17450v1
http://arxiv.org/abs/2405.17450v1ORLM:为优化建模训练大语言模型
 http://arxiv.org/abs/2405.17743v1
http://arxiv.org/abs/2405.17743v1HippoRAG
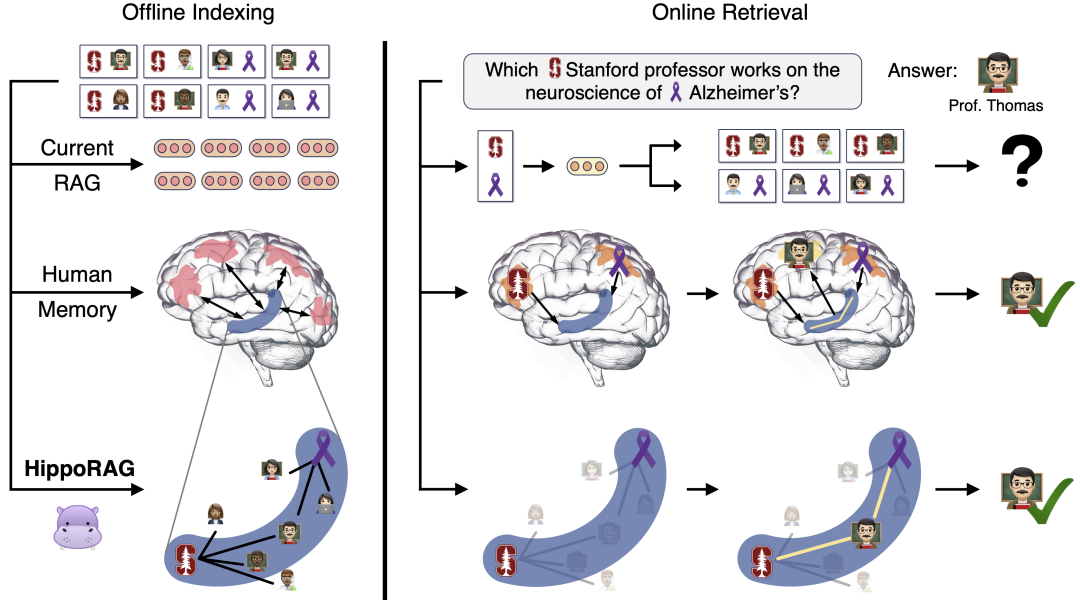 https://github.com/OSU-NLP-Group/HippoRAG
https://github.com/OSU-NLP-Group/HippoRAGThe LLooM
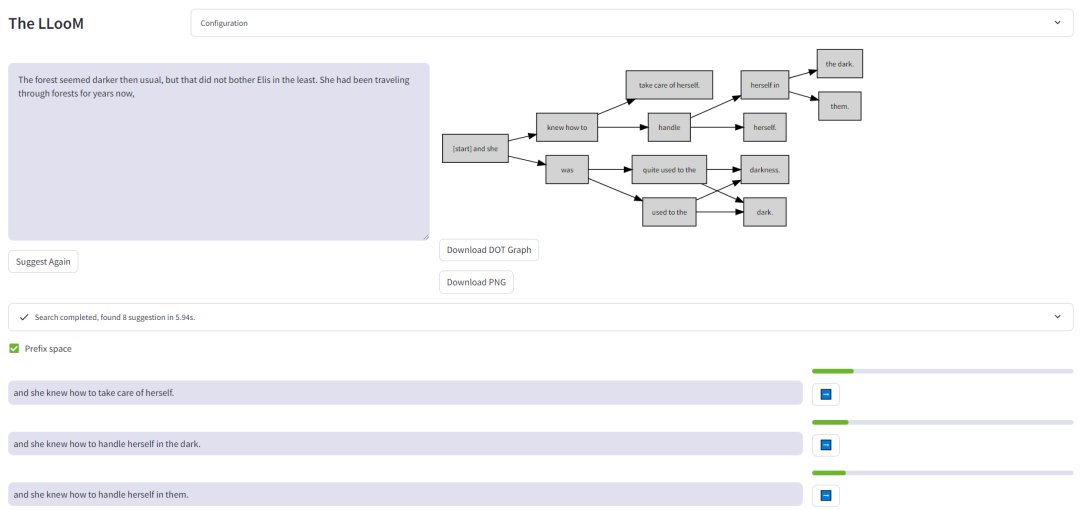 https://github.com/the-crypt-keeper/LLooM
https://github.com/the-crypt-keeper/LLooM原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/05/15038.html