MOLAR FRESH 2021年第8期
人工智能新鲜趣闻 每周一更新
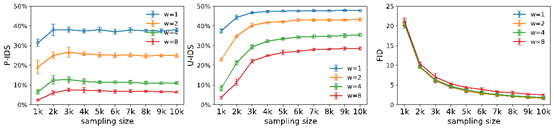
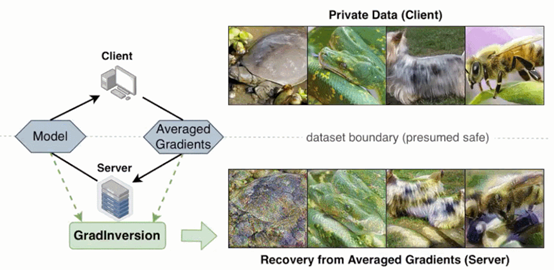
“霸榜CLUE” ,华为云发布的业界最大中文NLP预训练模型 近日,华为云发布了业界首个千亿参数的中文大模型——盘古 NLP 大模型。据了解,盘古 NLP 大模型,由华为云、循环智能和鹏城实验室联合开发,是全球最大的中文语言预训练模型,在预训练阶段就学习了 40 TB 的中文文本数据,其中包括细分行业的小样本数据,可以优化提升模型在具体场景中的应用性能。与其他大模型不同的是,盘古 NLP 大模型瞄准的是细分行业,主要解决商业环境中低成本大规模定制的问题。 华为云盘古系列 AI 大模型计划包括四大模型:NLP 大模型、CV 大模型、多模态大模型、科学计算大模型。整个大模型设计遵循三大原则:一是超大的神经网络;二是网络架构强壮,相比于定制化小模型,大模型综合性能提升了 10% 以上;三是健壮(Robust)的网络性能,全场景覆盖率提升 10 倍以上。 除了 NLP 模型,华为云还同时发布了盘古 CV 大模型。据了解,该 CV 模型包含 30 亿 + 参数,是目前业界最大的CV 模型,并且在 ImageNet 1%、10% 等数据集上的小样本分类精度上均达到目前业界最高水平(SOTA)。 ICLR 2021 | 协同调制生成对抗网络,轻松帮你实现任意大区域图像填充 图像填充是深度学习领域内的一个热点任务。尽管现有方法对于小规模、稀疏区域的填充可以取得不错的效果,但对于大规模的缺失区域始终无能为力。为解决这一问题,微软亚洲研究院提出了协同调制生成式对抗网络——一种通用的方法,跨越了条件与无条件图像生成领域之间的鸿沟,可轻松实现任意大区域的图像补全,还可以被拓展至更广泛的图像转换任务。 图1:从小规模(左)到大规模(右)的缺失区域,协同调制生成对抗网络始终可以创作出高质量、多样的填充内容。 此外,考虑到图像填充领域内缺乏良好的指标, 研究员们提出了新的配对/无配对感知器辨别分数(P-IDS/U-IDS),通过计算生成图像与真实图像在感知器特征空间中的线性可分程度,反映了生成图像的保真度,以更加 鲁棒、直观且合理地衡量模型性能。该相关工作已被 ICLR2021 接受为SpotlightPresentation。 图2:相较于 FID,P-IDS/U-IDS在数据量少的情况下收敛迅速。 联邦学习也不安全?英伟达研究用「没有隐私」的数据直接重建了原图 最近,英伟达的研究人员更进一步,甚至直接通过机器学习中的梯度数据重建了图像。具体地,研究者提出了一种GradInversion方法, 通过反转给定的批平均梯度(batch-averaged gradients)从随机噪声中恢复隐藏的原始图像。该研究已被计算机视觉顶会CVPR2021接收。 研究者提出了一种标签修复方法,利用最后的全连接层梯度来恢复真值标签。他们还提出了一种群体一致性正则化项,它是基于多种子优化和图像配准,用于提升图像重建质量。实验表明,对于 ResNet-50 这样的深度网络,利用批平均梯度完全恢复细节丰富的单个图像是可行的。 研究者在论文中表示,与 BigGAN 等 SOTA 生成对抗网络相比,他们提出的非学习(non-learning)图像恢复方法可以恢复隐藏输入数据的更丰富细节。更重要的是,即使当图像批大小增加至 48,通过反转批梯度,该方法依然可以完全恢复 224×224 像素大小且具有高保真度和丰富细节的图像。
深度稳定学习:因果学习的最新进展 | 清华大学团队 CVPR 研究
就在今年,清华大学崔鹏团队研究的稳定学习在深度学习框架下有些突破,给出了比较通用有效的深度稳定学习方法,名为 StableNet,其论文《Deep Stable Learning for Out-Of-Distribution Generalization》已被CVPR2021接收。
深度稳定学习的基本思路是提取不同类别的本质特征,去除无关特征与虚假关联,并仅基于本质特征(与标签存在因果关联的特征)作出预测。
如下图所示,当训练数据的环境较为复杂且与样本标签存在强关联时,ResNet等传统卷积网络无法将本质特征与环境特征区分开来,所以同时利用所有特征进行预测,而StbleNet则可将本质特征与环境特征区分开来,并仅关注本质特征而忽略环境特征,从而无论环境(域)如何变化,StableNet均能做出稳定的预测。
中科院自动化所、字节跳动提出高性能的指代性分割基准模型
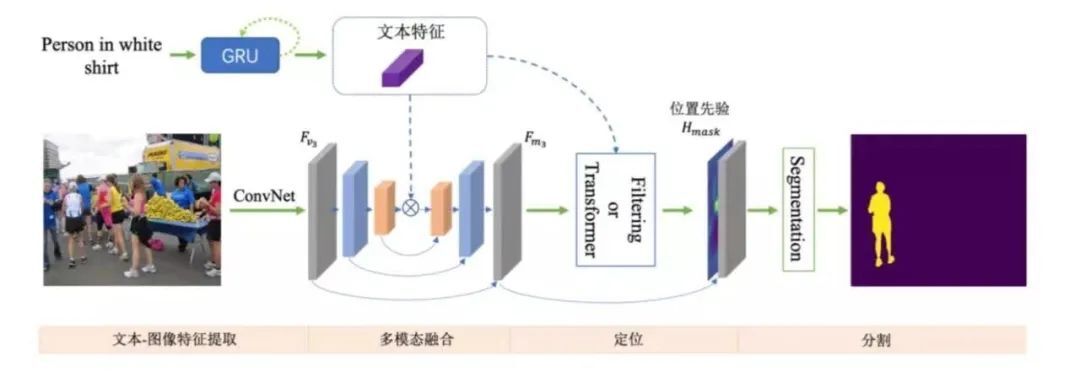
如何通过自然语言定位并分割出场景中的目标物体?比如给定一张图片,语言指示 「分割出穿白色衬衫的人」。这个任务在学术界叫做指代性物体分割(Referring Image Segmentation)。目前指代性分割的工作通常着重于设计一种隐式的递归特征交互机制用于融合视觉 – 语言特征来直接生成最终的分割结果,而没有显式建模被指代物体的位置。
为了强调语言描述的指代作用,来自中科院自动化所、字节跳动的研究者将该任务解耦为先定位再分割的方案(LTS,Locate then Segment),它在直观上也与人类的视觉感知机制相同。比如给定一句语言描述,人们通常首先会注意相应的目标图像区域,然后根据对象的环境信息生成关于对象的精细分割结果。该方法虽然很简单但效果较好。在三个流行的基准数据集上,该方法大幅度优于所有以前的方法。这个框架很有希望作为指代性分割的通用框架。
来源:机器之心
原创文章,作者:整数智能,如若转载,请注明出处:https://www.agent-universe.cn/2021/05/8445.html