
MOLAR NEWS
2021年第7期
MolarData人工智能每周见闻分享,每周一更新。
270亿参数、刷榜CLUE,阿里达摩院发布最大中文预训练语言模型PLUG
4 月 19 日,阿里达摩院发布了中文社区最大规模预训练语言模型 PLUG(Pre-training for Language Understanding and Generation)。该模型参数规模达 270 亿,集语言理解与生成能力于一身,在小说创作、诗歌生成、智能问答等长文本生成领域表现突出,其目标是通过超大模型的能力,大幅提升中文 NLP 各类任务的表现,取得超越人类表现的性能。
此前,达摩院机器智能实验室自研的 NLU 语言模型 StructBERT 与 NLG 语言模型 PALM 均在各自领域取得了 SOTA 的效果。简单来说,StructBERT 模型通过加强句子级别(Sentence Structural Objective)和词级别(Word Structural Objective)两个层次的训练目标对语言结构信息的建模,加强模型对语法的学习能力。PALM 模型则结合了 Autoencoding 和 Autoregression 两种预训练方式,引入 Masked LM 目标来提升 encoder 的表征能力,同时通过预测文本后半部分来提升 decoder 的生成能力。
来源:机器之心
AI语音诈骗防不胜防?腾讯朱雀实验室——用AI对抗AI!
近日,有研究发现,VoIP电话劫持与AI语音模拟正在成为一种新型的攻击技术,区别于此前脚本类的电信诈骗,它可实现从电话号码到声音音色的全链路伪造,攻击者可以利用漏洞劫持VoIP电话,实现虚假电话的拨打,并基于深度伪造AI变声技术生成特定人物的声音进行诈骗。
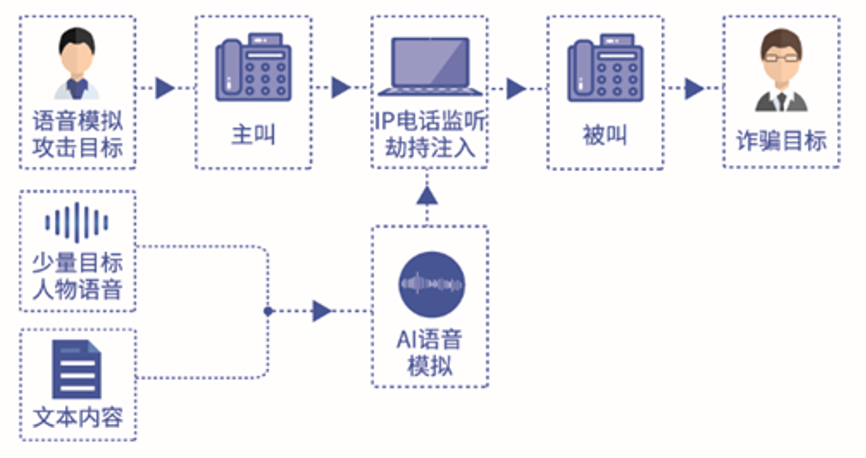

腾讯朱雀实验室研究显示,在VoIP电话劫持中,利用少量被攻击者的声音,可以合成与被攻击者音色相似的任意内容的语音片段,再将虚假语音注入到电话中,就能达到以假乱真的效果,实现完整的电话欺骗链路。攻击者可以轻松拨打虚假电话,冒充被攻击者身份与目标人员对话。

来源:AI科技评论
戴琼海团队新作登上Nature:提出光电可重构计算模式,迈向AI新时代
4月12日,一篇题为“Large-scale neuromorphic optoelectronic computing with a reconfigurable diffractive processing unit”的论文登上Nature子刊《Nature Photonics》。
论文是由中国工程院院士戴琼海教授团队撰写,第一作者是清华大学博士研究生周天贶。
智能时代的手工劳动者:调教AI、月薪三千
天空的颜色、路边的风景、交通路况、CT 片显示的病灶……所有视觉、声音或者文字信息,都隐含着这个星球的秘密。若是数据的标注不需要成本,人类应该想让机器感知整个物质的星球。
在机器学习的过程中,参与的数据集被分为训练集、验证集与测试集,机器的任务就是对根据训练集的数据点进行拟合、通过验证集调教预测模型,并测试集进行准确度评估。
事实上,包括阿里在内,每一个拥有大量数据需求的科技巨头均建立了各自的数据标注供应链。其中众包平台是他们获得标注服务的重要方式,例如腾讯搜活帮、百度智能云、京东众智、科大讯飞爱标客等,均是如此。
像白女士那样手把手教人工智能学习的方式,被称为“有监督”的机器学习。但当人工智能被逐渐养熟后,它自身的识别能力与模型拟合准确度将不断提高,进入人机协作模式。

他们的任务一开始比较最简单,比如判断句子意思是否通顺;进阶任务是识别图像、验证码。其中识别图像包括做人脸标识,这要求他们在各种角度、遮挡、清晰度的条件下,标注出五官、脸型的轮廓与位置,每张脸上要标出100多个识别点。

直至人工智能会在某模型的注准确度与效率完全超过人类,此时它便要离开人工标注,进入无监督机器学习。
当机械代替人力成为时代的强权,有批人失去了工作,但围绕着机械新创造出了能源、制造、维修、运输等产业,另一批工作又诞生了。
在可预见的将来,人工智能也许会成为新的时代权力高点,届时围绕人工智能,全新的职业秩序又将被重新建立。
至于人工智能会带来什么样的未来,也只能交给更远的未来去回答了。科幻电影《银翼杀手 2049》中,华莱士有一句话:Every leap of civilization was built on the back of a disposable workforce——每一次文明的跃进,都建立在可被抛弃的劳动力基础之上。
来源:网易智能
END




AI资讯
掌握最新时事新闻
长按扫码关注我们

原创文章,作者:整数智能,如若转载,请注明出处:https://www.agent-universe.cn/2021/04/8446.html