我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢 迎 大 家 一 起 交 流 !
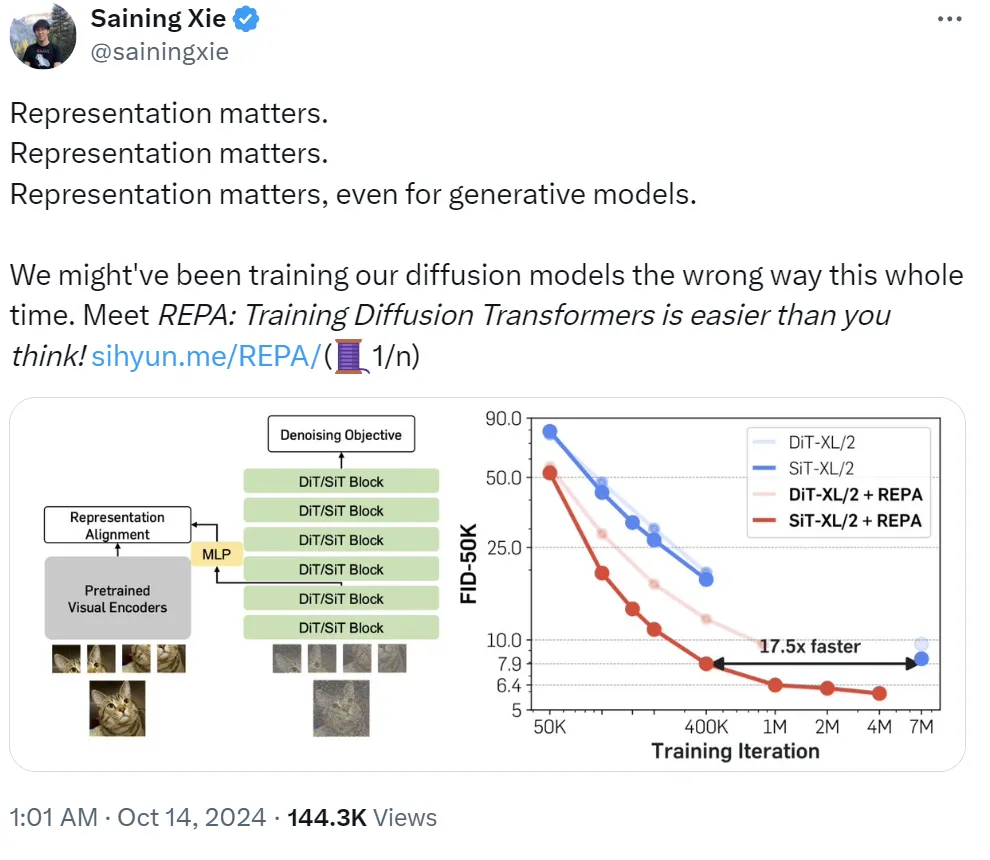
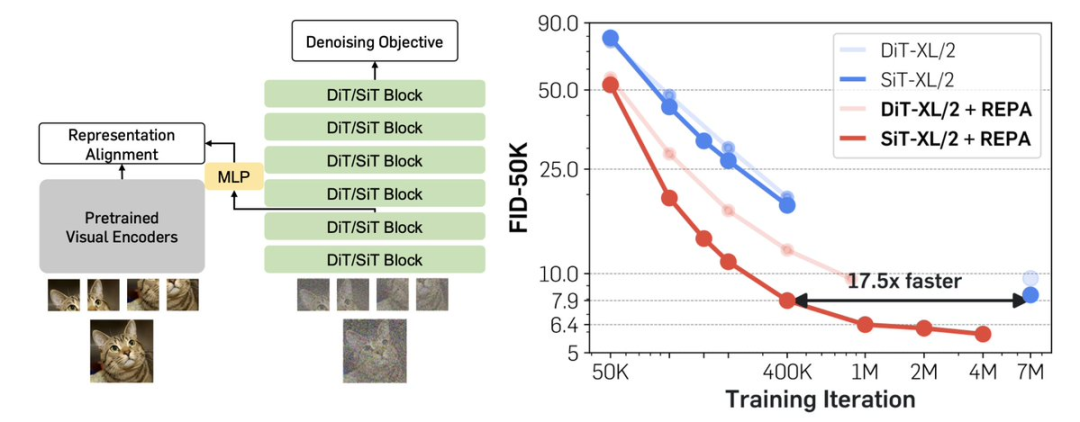
资讯 REPA:表征对齐助力扩散模型训练的突破 纽约大学研究者谢赛宁及其团队提出了表征对齐技术(REPA),旨在优化扩散模型的训练方式。他们认为,当前训练扩散模型的传统方法可能存在问题,而REPA技术能够让训练扩散Transformer变得更为高效且简单。REPA的核心在于通过将预训练自监督视觉表征与扩散模型的表征对齐,从而大幅提升模型性能。 Yann LeCun对这一研究表示认可,指出即便生成模型专注于像素生成,仍然应结合特征预测损失,以增强解码器的内部表征。基于此,研究团队提出了REPresentation Alignment(REPA),该技术利用预训练的视觉编码器(如DINOv2)生成的高质量表征,提升扩散Transformer的表现。研究发现,当扩散模型获得外部高质量表征支持时,其生成性能可以显著提升。 REPA是一种正则化技术,将预训练的自监督视觉表征蒸馏到扩散Transformer中。具体而言,REPA通过最大化扩散模型隐藏状态与外部视觉表征之间的相似性来实现表征对齐。通过这种方式,扩散模型能够更好地利用语义丰富的表征,进而提升生成效率。 REPA主要基于扩散Transformer(DiT)架构,使用预训练的视觉编码器(如DINOv2)来提供干净的视觉表征。通过加入REPA,模型的训练效率和生成质量均得到了大幅度提升。实验证明,REPA在模型收敛速度上比原生模型快17.5倍,并在生成图像质量上取得了优异的成绩。在无分类器引导的情况下,REPA训练的模型取得了当前最佳的生成效果,达到FID=1.42。 通过对比,研究团队发现扩散模型与先进视觉编码器之间存在较大的语义差距。REPA的应用显著缩小了这种差距,提升了模型的生成质量和特征对齐效果。此外,研究表明,模型规模和训练迭代次数的增加能够进一步提升表征对齐效果。REPA技术不仅提高了训练效率,还在视觉生成领域展现了强大的可扩展性。 REPA的引入让扩散模型的训练变得更加高效,通过与预训练视觉表征的对齐,扩散模型能够在更少的训练迭代中达到更好的生成效果。这一发现有望推动生成模型在多个领域的应用,并提升其训练效率和性能。 https://mp.weixin.qq.com/s/a725rxzvyQXqNJoL1NsMaA 数据中心技术的爆发与创业公司的挑战 随着人工智能的飞速发展,数据中心行业正在迅速扩展,成为AI公司不可或缺的基础设施。然而,建设和运行数据中心的成本极其高昂,且对能源的消耗巨大。尽管许多初创企业试图通过提高效率和减少环境影响来革新这一领域,但实现这一目标并非易事。 根据P&S Intelligence的数据,全球数据中心市场预计到2030年将从3010亿美元增长到6224亿美元。当前,数据中心在美国的电力消耗约占总电力的4%,预计到2030年将增至9%。这一飞速增长导致了对电力的巨大需求,一些公司如微软甚至重新启用了核能来满足数据中心的电力需求。 初创公司如Incooling和Submer专注于通过冷却现有的数据中心技术来减少热量产生,而Phaidra则通过软件优化数据中心的冷却管理。另有公司如Verrus通过构建基于微电网的灵活数据中心,Sage Geosystems则尝试用热压水代替天然气为数据中心提供电力。 尽管初创公司积极探索新技术,但面临的挑战依然严峻。数据中心是昂贵的资产,成本动辄数十亿美元,因此大型数据中心并非实验性技术的理想场所。S2G Ventures的管理董事Francis O’Sullivan指出,这些资产的高价值和运行稳定性要求使得大型数据中心不愿意轻易测试新技术。此外,数据中心技术的客户群体高度集中,主要是微软、亚马逊等巨头公司,这些公司在采购过程中压缩利润空间,给初创公司带来巨大压力。 尽管如此,随着欧洲和美国一些数据中心集中的州(如弗吉尼亚州)即将出台新规,未来大公司不得不寻求更高效的解决方案。这为数据中心技术初创企业提供了增长机会。初创公司Incooling的联合创始人Helena Samodurova表示,近年来对数据中心技术的关注度显著提升,公司也受到了更多潜在客户和投资者的关注。
https://techcrunch.com/2024/10/13/data-center-tech-is-exploding-but-adoption-wont-be-easy-for-startups/ 合成数据的潜力与风险 随着人工智能的发展,是否可以仅依靠AI生成的数据来训练另一AI成为热门话题。虽然听起来大胆,但合成数据在AI领域的应用已经越来越普遍,尤其是在真实数据难以获取的背景下。Anthropic、Meta和OpenAI等公司已经在部分模型的训练中使用了合成数据。然而,合成数据能否完全替代真实数据,仍然存在争议。 AI系统依赖大量数据来学习模式,而数据的标注起到了至关重要的作用。标注数据帮助模型区分物体、地点和概念,形成判断依据。例如,通过成千上万张标注为“厨房”的图片,模型学会识别厨房的特征。然而,标注数据获取成本高,且受限于标注员的速度、偏见和错误。因此,寻找替代人类标注的方法非常重要。 随着越来越多的公司选择限制数据访问,数据获取变得愈加困难。据估计,35%的全球顶级网站已禁止OpenAI等公司的网络爬虫,数据资源变得稀缺。如果这种趋势持续下去,预计到2026至2032年,AI开发者将面临数据枯竭的困境。 合成数据作为替代方案开始受到广泛关注。许多公司已成功应用合成数据,降低了训练成本。例如,Writer公司利用合成数据开发模型,成本仅为70万美元,而类似规模的OpenAI模型则需耗资460万美元。Gartner预测,到2024年,60%的AI项目将使用合成数据。 尽管合成数据在一定程度上解决了数据短缺问题,但其风险不容忽视。合成数据面临“垃圾进,垃圾出”的问题。如果用于生成合成数据的模型存在偏见或缺陷,这些问题会被放大。例如,训练数据中对某些群体的代表性不足,可能导致模型生成的数据同样具有偏见。研究发现,过度依赖合成数据可能导致模型质量和多样性下降,混合使用真实数据能在一定程度上缓解这一问题。
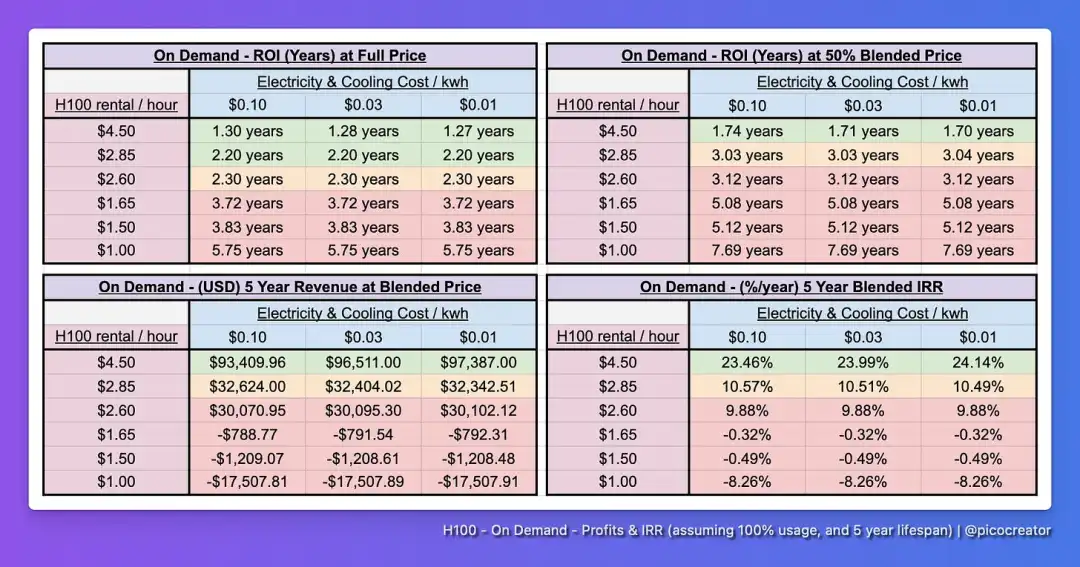
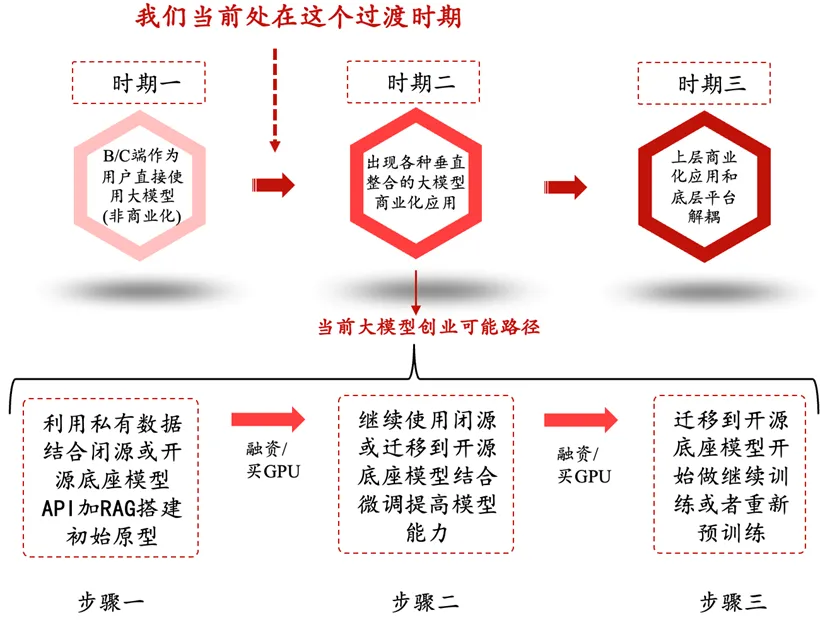
https://techcrunch.com/2024/10/13/the-promise-and-perils-of-synthetic-data/ 2美元/小时出租H100:GPU泡沫破灭前夜 AI竞赛自2022年末加速,OpenAI通过A100 GPU训练的GPT-3.5和ChatGPT引发了全球关注,H100 GPU于2023年推出,加速了AI竞赛。H100的性能较A100提升3倍,但价格也翻倍,推动了AI基础设施的需求。初期H100的价格高达每小时8美元,吸引了大量资本投入,导致GPU价格飙升。尽管NVIDIA预测H100租赁价格将保持在4美元/小时,2024年市场价格却大幅下跌,至2.85美元甚至更低。 从经济角度看,H100的投资回报率在不同租赁模式下差异显著。对于按需租赁,价格低于2.85美元/小时时,回报率接近或低于股市收益。长期租赁则在高峰期签订了价格较高的合同,部分基础设施提供商面临困境。GPU市场供需变化剧烈,H100算力需求因微调模型替代了从零开始训练的需求而减少,大量闲置算力通过算力转售商进入市场。 此外,市场上出现了L40S等推理性能较好的替代品,以及来自AMD和Intel的竞争者,加剧了H100的价格压力。长期来看,开放权重模型的兴起和算力价格的下降可能加速AI推理和微调的普及,但对那些依赖高价H100集群的投资者来说,未来或面临亏损风险。 https://mp.weixin.qq.com/s/4rgDaOmXXVRXMBfh7uLtmA 硅谷深思:GPT应用迟未爆发,大模型泡沫根源初探 目前,AI领域的投资者和创业者主要分为两大派别:应用场景派和底层技术派。 应用场景派 这一派的投资者关注利用底层大模型驱动特定垂直行业的商业化公司,创始人往往有场景侧或产品背景,而不一定深入理解底层大模型。这类投资的关键问题包括:1. 识别驱动LLM推动应用场景爆发的核心要素是什么;2. 这些驱动因素是否具有长期持续性;3. 应用场景大规模爆发的里程碑。盲目押注应用场景的投资,可能导致泡沫。 底层技术派 这一派专注于AI底座大模型的开发,认为未来应用依赖于底层平台的驱动。该类公司遇到的瓶颈主要包括:1. 上层应用未爆发,底层平台需亲自做定制化服务;2. 应用和底层模型边界模糊,底座升级时可能压垮应用;3. 训练数据枯竭,无法持续扩展;4. 算力需求高,投入成为资本游戏。上层应用迟迟未见大爆发,也让这类投资面临不确定性。 技术困境与商业化挑战 AI产业化从深度学习到大模型的发展依赖于数据和算力的充分利用,但当前数据困局尤为明显。只有拥有私有数据并能有效利用这些数据的公司才有竞争力。大模型的高算力需求和数据依赖导致了基础设施和应用场景的强耦合,阻碍了大规模商业化应用的落地。 https://mp.weixin.qq.com/s/KMwTAStHWWXboAijHn7FYw 推特 ClipbookLM:YouTube视频转换生成博客文章 参加由Y Combinator 和 OpenAI 举办的黑客松 我在这次黑客松中为Overlap开发了ClipbookLM工具,使用了o1技术。 你只需上传一个较长的YouTube视频,我们将为你提取出最佳时刻,提供直接分享的功能,帮助你找到引人注目的语录,并生成博客文章。查看下方帖子以获取链接!🧵 https://x.com/caseytraina/status/1845338263558684859s=46&t=GRStLXDcUNuun8J5Noyw4Q 0097
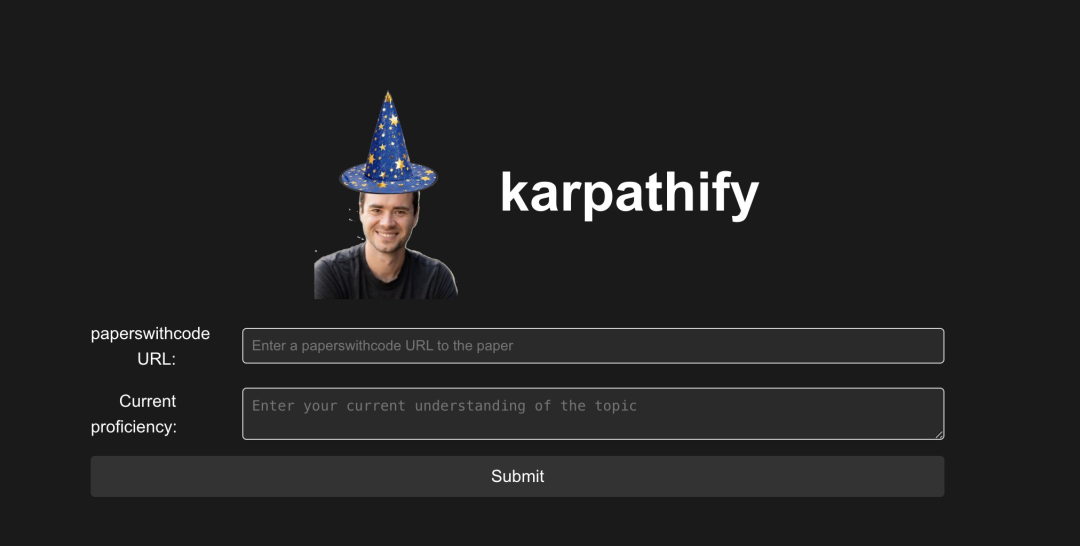
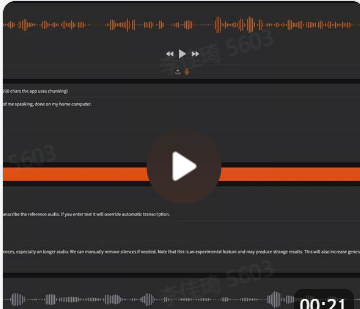
开发Karpathy-fy:为论文实现量身定制学习计划的创新工具 @arpit_tarang 和我一起开发了@karpathy-fy!它能够接收一个paperswithcode的链接,根据你的当前熟练程度,为你量身定制一个5节课的学习计划,帮助你从现有水平逐步深入到论文实现的核心部分,就像Karpathy视频系列或Labml风格一样。这是之前的模型都无法完成的任务,而O1的表现非常出色。 最棒的是什么?输出的是一个可执行的ipynb笔记本(你可以使用@minusxai来进行学习:) )下面的视频展示了苹果最新的单目深度估计论文。我可以通过这个工具深入理解它,甚至包括论文中的损失函数和所有相关内容! https://x.com/nuwandavek/status/1845189691286671479?s=46&t=GRStLXDcUNuun8J5Noyw4Q 仅用10秒音频即可实现音频克隆
就在几个月前,克隆一个声音还需要商业服务。但现在不再需要了。以下是我在家用电脑上,仅使用一个10秒的参考音频片段克隆出我的声音。
https://x.com/emollick/status/1845619684709679517?s=46&t=GRStLXDcUNuun8J5Noyw4Q
自监督学习中的视觉编码器训练与REPA模型 在使用自监督学习训练视觉编码器时,我们知道使用带有重建损失的解码器效果远不如使用带有特征预测损失和崩溃预防机制的联合嵌入架构。即使对于生成像素(如使用扩散变压器生成图片)的任务,加入特征预测损失也非常重要。这能让解码器的内部表示从预训练的视觉编码器(如DINOv2)中预测出有效的特征。 纽约大学的Saining Xie团队的最新研究表明,生成模型的表示也至关重要。事实上,研究表明我们可能一直在用错误的方法训练扩散模型。他们提出了一种名为REPA的新方法,强调训练扩散变压器比预想的要简单得多。 https://x.com/ylecun/status/1845535264917364983s=46&t=GRStLXDcUNuun8J5Noyw4Q LongCite:在长上下文问答中实现细粒度引用生成 在过去,RAG(Retrieval-Augmented Generation)系统是从文档中检索信息的标准方法。然而,如果不是反复查询同一份文档,使用长上下文的大型语言模型(LLMs)可能更方便和有效。比如,Llama 3.1 8B 和 Llama 3.2 1B/3B 现在支持多达 131k 输入tokens,只要硬件允许,它们是可行的替代方案。 无论采用哪种方法,使用LLMs进行问答的一个主要局限是它们无法提供引用。 我最近阅读了一篇有趣的论文,旨在通过细粒度引用来改进信息检索,标题为《LongCite:使LLMs在长上下文问答中生成细粒度引用》 ( https://arxiv.org/abs/2409.02897)。 在这篇论文中,研究人员使用现成的LLM生成一个包含精确句子级引用的长上下文问答实例的数据集,然后使用该数据集微调一个开源权重的LLM,使其能够生成带有引用的答案。最终生成的 LongCite 8B 和 9B 模型与 GPT4o 和 Llama 3.1 等相比表现出色。
生成问答数据集:研究人员首先从长文本或文档开始,使用现有的LLM通过自我指令(Self-Instruct)方法生成问答数据集。
粗粒度引用:接下来,他们使用答案从输入文本中检索多个128-tokens的片段,作为粗粒度的引用。
细粒度引用:LLM然后在这些片段中查找相关句子,以提供更细粒度的句子级引用。
筛选数据集:研究人员过滤掉那些答案中少于20%的声明没有引用的问答对。
https://x.com/rasbt/status/1845468766118850862s=46&t=GRStLXDcUNuun8J5Noyw4Q 投融资 COVU完成1250万美元A轮融资 COVU,作为保险行业AI服务的领导者,宣布成功完成了1250万美元的A轮融资,其中包括股权和债务融资。此次融资使COVU的总融资额超过2000万美元,并且在达到关键里程碑后,还将解锁额外的400万美元债务和股权资金。本轮融资由Benhamou Global Ventures (BGV)、ManchesterStory和Markd领投,同时吸引了新老投资者的参与。 此次注入的资金将帮助COVU进一步提升其平台,使保险机构能够简化工作流程、改善客户服务,并更自信地扩展业务。COVU专注于为保险机构提供基于AI的产品和服务,包括CRM(客户关系管理)、营销工具和专业支持,旨在通过AI技术帮助保险机构提高运营效率并优化客户体验。 COVU的联合创始人兼CEO Ali Safavi表示:“我们致力于为保险机构提供AI原生的解决方案,提升效率和信任感。此次融资让我们能够加大对AI原生服务的投入,帮助合作伙伴优化业务运营,并提供卓越的客户体验。” 主要投资者对COVU的未来发展充满信心,认为其通过将AI洞察与人类服务相结合,正在引领保险服务行业的变革。 公司官网:https://www.covu.com/ https://www.insurtechinsights.com/covu-secures-12-5-million-in-series-a-funding/
— END —
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/10/21579.html