
MOLAR NEWS
2021年第6期
MolarData人工智能每周见闻分享,每周一更新。
学界丨图灵奖得主 Yann LeCun 最新文章 :自监督学习,人工智能世界的“暗物质”
自监督学习让 AI 系统能够从很少的数据中学习知识,这样才能识别和理解世界上更微妙、更不常见的表示形式。自监督学习在自然语言处理(NLP)领域取得了显著的成就,包括 Collobert-Weston 2008 模型、Word2Vec、GloVE、fastText,以及最近的 BERT、RoBERTa、XLM-R 等成果。与仅以监督方式做训练的系统相比,以这种方式进行预训练的系统所提供的性能要高得多。
自监督学习是利用数据的基础结构来从数据本身获取监督信号的。一般来说,自监督学习使用的技术是根据输入的任何观察到的或非隐藏的部分,来预测输入的任何未观察到的或隐藏的部分(或属性)。例如,在 NLP 中很常见的例子是,我们可以隐藏句子的一部分,并从其余单词中预测隐藏的单词。我们还可以根据当前帧(观察到的数据)预测视频中的过去帧或未来帧(隐藏数据)。由于自监督学习使用的是数据本身的结构,因此它可以在多种共现模式(例如视频和音频)和大型数据集中利用各种监督信号,而无需依赖标记。

由于自监督学习是由监督信号推动的,因此与之前使用的术语“无监督学习”相比,“自监督学习”这个术语更容易被接受。无监督学习是一个定义不清、具有误导性的术语,让人觉得这种学习根本用不到监督。实际上,自监督学习并不是无监督的,因为它使用的反馈信号比标准的监督学习和强化学习方法要多得多。
来源:中国人工智能学会
AAAI学术新星 Noam Brown:不完美信息多智能体场景下的AI研究
Brown的研究倾向于关注不完美信息博弈。在这种博弈中,玩家可以获得其他玩家无法获得的私人信息。如果我们想要在现实世界中部署人工智能系统,我们必须能够解决这类隐藏信息的问题,因为大多数现实世界的策略交互都涉及到一些隐藏信息。例如,金融市场、安全交互、业务谈判,甚至车辆导航场景下都涉及隐藏信息。

在很长一段时间内,人工智能系统都无法击败世界上顶尖的扑克选手。直到 2017 年,Brown和导师研制出了 Libratus,它与世界上 4 位最顶尖的「无限制德州扑克」对战,并成功击败了他们。
Libratus 系统有一些有趣的地方。首先,它完全通过自己和自己博弈来训练,并没有使用任何的人类数据。另一个值得注意的地方是,该系统在 20 天内打了超过 12 万手德州扑克,而在这个过程中人类专家队伍试图寻找他们可以利用的系统的漏洞和弱点。但直到最后,他们也未能如愿以偿。这也证明了我们在 Libratus 汇总使用的博弈论方法是有效的。如果我们想要在现实世界中具有数以亿计的用户的场景下部署人工智能系统,这种对于对抗性的调整和利用的鲁棒性是十分重要的。如果这些系统中存在一些漏洞,那么用户们终究是会发现它们的。
Noam Brown 的研究工作主要关注对大规模环境下的均衡的高效计算,将搜索和学习技术泛化到单智能体环境和完美信息博弈中,最终开发适用于真实场景(混合协作、竞争、多智能体环境)下的人工智能技术。
来源:AI科技评论
对抗攻击层出不穷?神经科学带来新突破、导出智能统一框架,Hinton:我早有洞见
最近的神经科学研究指出了如何击败对抗性示例,并为实现更具弹性、一致性和灵活性的人工智能指明了道路。
当我们识别出一个物体时,我们的皮质柱已经就我们所看到的东西达成了共识。我们每个皮质柱中的投票单元(神经元)会形成一个稳定的模式,表征该物体以及该物体相对于我们的位置。
研究检测对抗性示例的新方法是一个有趣的领域,相关的学术活动不计其数。现在缺少的是重新思考我们的深度学习架构和系统,从当前的静态范式过渡到基于多模态、多模型、基于共识的预测系统(具有弹性、一致性和灵活性)的动态范式。当我们实现这一点时,我们将能够隐藏或扰乱系统的某些部分,并且仍然保持稳定的预测。
来源:AI科技评论
DeepMind提出基于视觉的强化学习模型,十八般兵器对机器人不在话下
对于机器人学习任务来说,模仿学习是一个强大的工具。但在这类环境感知任务中,使用强化学习来指定一个回报函数却是很困难的。
DeepMind最新论文主要探索了仅从第三人称视觉模仿操作轨迹的可能性,而不依赖action状态,团队的灵感来自于一个机器人机械手模仿视觉上演示的复杂的行为。
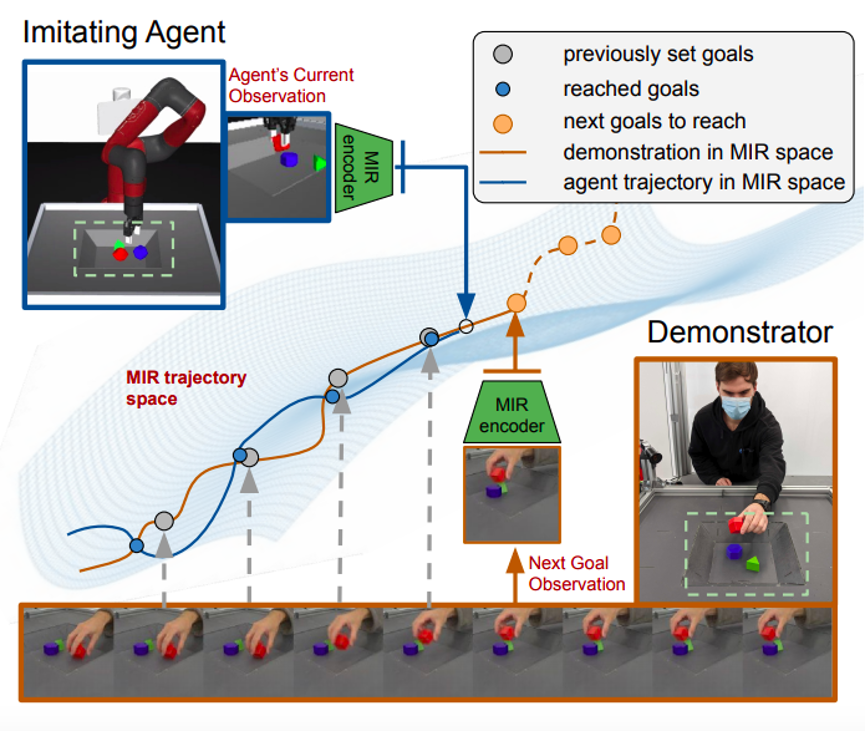
DeepMind提出的方法主要分为两个阶段:
1、提出一种操作器无关的表示(MIR, Manipulation-Independent Representations),即不管是机械手、人手或是其他设备,保证这种表示都能够用于后续任务的学习
2、使用强化学习来学习action策略
MIR 在所有测试领域都取得了最好的性能。它在叠加成功率方面的表现显著提高,并且以100% 的分数很好地模仿了模拟的 Jaco Hand 和 Invisible Arm。
这项研究论证了视觉模仿表征在视觉模仿中的重要性,并验证了操作无关表征在视觉模仿中的成功应用。
未来工厂中的机器人将拥有更强大的学习能力,并不局限于一种特定工具,一种特定任务。
来源:新智元
END





AI资讯
掌握最新时事新闻
长按扫码关注我们

原创文章,作者:整数智能,如若转载,请注明出处:https://www.agent-universe.cn/2021/03/8450.html