


MOLAR FRESH 2021年39期
人工智能新鲜趣闻 每周一更新
01
黑客帝国真的可以!这100万个「活体人脑细胞」5分钟学会打游戏
缸中之脑要成真的了?
近日,来自澳大利亚研究团队Cortical Labs开发了一种微型人类大脑——盘中大脑(DishBrain)

AI要90分钟才学得会的「乒乓球」游戏,这个「大脑」仅仅用了5分钟就玩得有模有样了,这款电子游戏很经典,名为《Pong》,就是打乒乓球。

研究团队将这些人脑细胞生活的世界称为黑客帝国中的「模拟矩阵」。
DishBrain由生长在微电极阵列顶部的单层人类脑细胞组成,而微电极阵列可以刺激这些脑细胞。
这些人脑细胞从何而来?
虽然叫「人脑细胞」,但并非是从人脑中直接提取神经元细胞。
科学家提供了一种方案:用人类诱导的方式,让多能干细胞(hiPSC)分化为皮质神经元细胞,然后进行培殖。

接着,研究人员把这些神经元培养物被放置到 HD-MEA 高密度微电极阵列上,通过刺激这些细胞,就可以在虚拟环境中打Pong——乒乓球了。
要想完成「脑细胞打乒乓球」,得要一套精密的装置。
整个装置的结构是这样的,中央那个圆形的凹槽便是放置脑细胞和电极的地方。

该系统基于互补的氧化物半导体(CMOS)技术,可以记录多达1024个通道数和多达32个单元的刺激。
为了教会迷你「大脑」乒乓球,研究小组让这片神经元去玩了单人乒乓球游戏。
电极阵列的上半部分的神经元负责感知乒乓球的位置,而下半部分神经元分左右两块,负责输出乒乓球拍上下移动的距离。
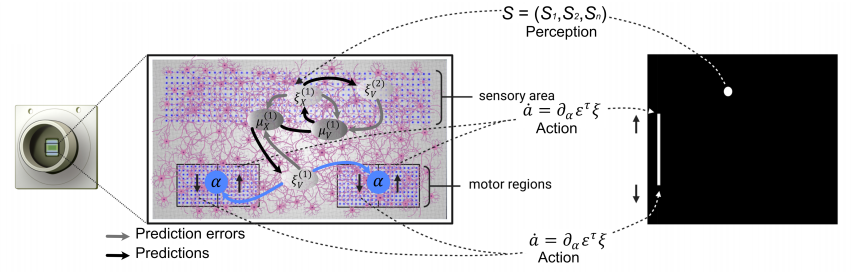
经过一段时间的训练,神经元们就能学会根据球的位置来回移动球拍。
来源:新智元
论文地址:https://www.biorxiv.org/content/10.1101/2021.12.02.471005v1.full
参考资料:
https://futurism.com/the-byte/brain-cells-play-pong
https://www.dailymail.co.uk/sciencetech/article-10322247/Human-brain-cells-grown-petri-dish-learn-play-Pong-faster-AII.html
02
理解物体之间潜在关系,MIT新研究让AI像人一样「看」世界
人工智能必须理解物体之间的潜在关系才能更好地与世界交互。
人们观察场景通常是观察场景中的物体和物体之间的关系。
比如我们经常这样描述一个场景:桌面上有一台笔记本电脑,笔记本电脑的右边是一个手机。
但这种观察方式对深度学习模型来说很难实现,因为这些模型不了解每个对象之间的关系。
为了解决这个问题,在一篇NeurIPS 2021 Spotlight论文中,来自MIT的研究者开发了一种可以理解场景中对象之间潜在关系的模型。
该模型一次表征一种个体关系,然后结合这些表征来描述整个场景,使得模型能够从文本描述中生成更准确的图像。

这项研究的成果将应用于工业机器人必须执行复杂的多步骤操作任务的情况,例如在仓库中堆叠物品、组装电器。
该研究提出使用 Energy-Based 模型将个体关系表征和分解为非规一化密度。
关系场景描述被表征为关系中的独立概率分布,每个个体关系指定一个单独的图像上的概率分布。

该研究表明所提框架能够可靠地捕获和生成带有多个组合关系的图像,并且能够推断潜在的关系场景描述,并且能够稳健地理解语义上等效的关系场景描述。
在泛化方面,该方法可以推广到以前未见过的关系描述上,包括对象和描述来自训练期间未见过的数据集。
此外,该系统还可以反向工作——给定一张图像,它可以找到与场景中对象之间的关系相匹配的文本描述。

研究人员将他们的模型与几种类似深度学习方法进行了比较,实验表明在每种情况下,他们的模型都优于基线。
来源:机器之心
论文地址:https://arxiv.org/abs/2111.09297
03
最新3D GAN可生成三维几何数据了!模型速度提升7倍,英伟达&斯坦福出品
2D图片变3D,还能给出3D几何数据?
英伟达和斯坦福大学联合推出的这个GAN,真是刷新了3D GAN的新高度。
而且生成画质也更高,视角随便摇,面部都没有变形。

最厉害的莫过于还可给出3D几何数据,根据提取的位置信息再渲染得到3D图像效果。
甚至还能实时交互编辑。

事实上,只用一张单视角2D照片生成3D效果,此前已经有许多模型框架可以实现。
但是它们要么需要计算量非常大,要么给出的近似值与真正的3D效果不一致。
这就导致生成的效果会出现画质低、变形等问题。
为了解决以上的问题,研究人员提出了一种显隐混合神经网络架构(hybrid explicit-implicit network architecture)。

英伟达和斯坦福大学提出的这个新方法EG3D,就将显式和隐式的表示优点结合在了一起,同时保证了输出质量和速度。
它主要包括一个以StyleGAN2为基础的特征生成器和映射网络,一个轻量级的特征解码器,一个神经渲染模块、一个超分辨率模块和一个可以双重识别位置的StyleGAN2鉴别器。
与典型的多层感知机制相比,该方法在速度上可快出7倍,而占用的内存却不到其十六分之一。
与此同时,该方法还继承了StyleGAN2的特性,比如效果良好的隐空间(latent space)。
比如,在数据集FFHQ中插值后,EG3D的表现非常nice:

该方法使用中等分辨率(128 x 128)进行渲染,再用2D图像空间卷积来提高最终输出的分辨率和图像质量。
来源:量子位
论文地址:https://arxiv.org/abs/2112.07945
参考链接:https://matthew-a-chan.github.io/EG3D/
04
论文图片误用?AI:这条路已被我堵死了
现在的AI已经开始参与论文打假了!
就像是这样,经过旋转、拉伸和缩放之后的图片,人眼或许无法辨认,但AI能看到数百个相似的特征:

即使通过高超的“图像处理手段”把一张完整图像中的局部画面挪到自己的图像里,也能一眼分辨:

对于AI来说,这可能是秒认的活儿,甚至就算是一篇图像繁杂的完整论文,也不过花费一两分钟。
近几年,AI打假员愈发频繁地被引入了论文审查,尤其是图像问题中。
比如,自今年1月份开始,世界上最大、最古老的癌症研究专业协会,美国癌症协会(AACR)就已经开始使用AI软件来评审旗下期刊文章里的图片造假或重复问题了。
官方网站上也已经写明:提交手稿中的所有图像都需要通过AI软件进行筛选。

不仅是AACR,世界第五大出版商SAGE、老牌经典医学期刊JCI、JCI Insight都已经用上了这种方法。
这些期刊和出版商们所使用的是一个由以色列公司Proofig开发的同名软件。
Proofig软件基于AI技术和图像处理技术,面向各种科学文稿中的图像。
软件会从论文中识别图像,然后提取它们共同的特征进行比较。
这些“共同的特征”包括对图像整体的缩放或旋转、部分重复或重叠、还有一些方位上的不同。
除此之外,软件也能额外检测到一些问题,比如高分辨率的原始数据被压缩到更小的文件中时,可能出现的压缩失真或压缩伪影(Compression artifact)情况。

来源:量子位
参考链接:
https://www.nature.com/articles/d41586-021-03807-6
https://www.nature.com/articles/nature.2016.19802
END

掌握AI资讯
了解更多科技趣闻
长按扫码 关注我们
原创文章,作者:整数智能,如若转载,请注明出处:https://www.agent-universe.cn/2021/12/8399.html