


MOLAR FRESH 2021年40期
人工智能新鲜趣闻 每周一更新
01
DIY最美数字女友!MIT开源最强虚拟人生成器,登Nature子刊
麻省理工学院媒体实验室(MIT Media Lab)的研究人员开源了一个易于使用的虚拟角色生成通道。
结合了面部、手势、语音和动作领域的人工智能模型,可用于创建各种音频和视频输出。

使用人工智能技术制作的蒙娜丽莎、玛丽·雪莱、等人的动画
该虚拟角色生成通道还使用了可追踪的、人类可读的水印标记了其输出的结果。
这样一来,它生成的内容就可以与真实的视频内容区分开来,进而防止一些恶意的用途。
研究人员表示,如果有更多的学生、教育工作者、卫生保健工作者和治疗师有机会构建和使用这些虚拟角色,那么,这些虚拟角色可能会为更多人带来福祉。
生成性对抗网络(GAN),是两个相互竞争的神经网络的组合,使得创建极具真实感的图像、克隆声音和生成人脸动画变得更加容易。
研究人员在一个名为Machinoia的项目中首次探索了生成人脸动画的可能性。

在这个项目中,研究人员创造了各个年龄段的自己:少年、青年、中年、老年,让他们从不同的角度和自己进行对话。
Machinoia技术还可以用于在视频会议中隐藏自己的脸,但是还能保留面部表情和情绪。

Machinoia项目还有更多好玩的用例。
在今年秋天,由Maes和研究机构Roy Shilkrot共同教授的Deepfakes实验课上,学生们用这项技术将一幅描绘清明历史场景的中国画中的人物制作成了动画。

来源:新智元
参考资料:
https://news.mit.edu/2021/ai-generated-characters-for-good-1216
https://www.nature.com/articles/s42256-021-00417-9
02
用“意念”发Twitter,静脉植入脑机接口电极,渐冻症患者把思想转化为文字
一名62岁的渐冻症(ALS)患者,发出了自己的第一条Twitter,他也成为全球首个用植入式脑机接口发布推文的人。

不过这条Twitter并非是通过患者本人账号发布,而是借助Synchron公司CEO账号发出的。
Synchron便是向这位用户提供脑机接口设备的公司。
看到这位用户胸口的设备了吗?那个就是他的脑机接口。
这位名叫Philip O’Keefe的渐冻症患者于2020年4月接受了脑机接口手术。
和马斯克的Neuralink不同的是,Synchron不需要在颅骨上打孔,而是通过静脉将电极植入大脑。
从手术方法和植入物来看,Synchron的脑机接口都与心脏支架颇为相似。

Synchron把这项技术叫做“支架电极记录阵列”Stentrode。
电极从颈静脉插入,进入脑部,经过14天的细胞生长,最后电极会与脑部血管壁融合。
大脑产生的电流通过导线从胸口的电极引出,然后与信号处理设备相连。

用户经过训练后,即可用眼球和意念控制鼠标。现在,O’Keefe可以电脑上“想点哪里就哪里”,能完成发送电子邮件、登录银行、线上购物等操作。
但通过脑机接口学习一项新技能并非易事,O’Keefe的女儿说,为了发布这条Twitter,父亲学习了4个小时。
目前,Synchron的支架电极在今年7月已获得FDA批准,允许在志愿者身上进行试验。
来源:量子位
参考链接:
https://twitter.com/tomoxl/status/1473809025254846467
https://interestingengineering.com/a-62-year-old-paralyzed-man-sent-out-his-first-tweet-with-brain-chip
https://www.fiercebiotech.com/medtech/synchron-raises-40m-for-u-s-trials-neurotech-helping-paralysis-patients-text-email-and
03
7分钟分析人类全基因组,他们刷新全球纪录,此前最快也要24小时
全球首次将人类全基因组分析,推进分钟级时代。

这支团队,由三家来自中国的机构共同组建。
他们这次所做的具体任务,叫做30X人类全基因组测序(WGS)胚系变异分析。
(其中,“30X”是指全基因组测序的深度)
而在这个团队之前,同等条件下完成这项任务所需的时间,却长达近24小时之久。
所以咱就是说,现在的“battle”结果就是——24小时 vs 7分钟,性能整个提升了200多倍!
与此同时,在相同条件下的计算成本还降低了80%,存储成本也下降30%。
这一次的“7分钟”,可以说是把基因测序这件事往“平民时代”更推近了一步。
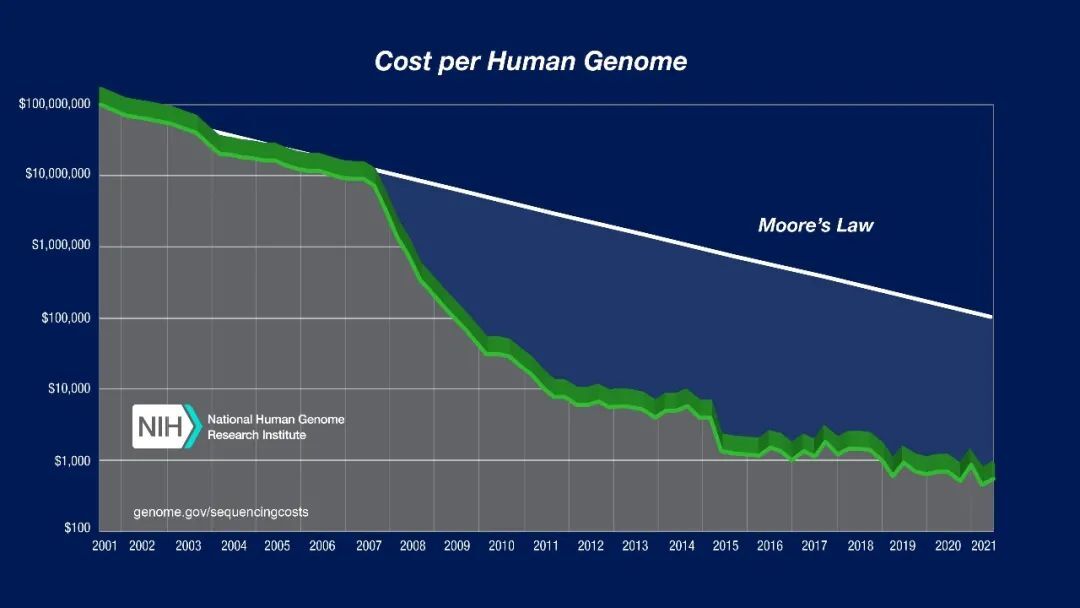
从24小时到7分钟,他们是怎么办到的?
人类全基因组测序要做的事,就是对未知基因组序列的物种进行个体的基因组测序。
但非常明显的一个难题,就是其数量过于庞大。
对象是组成人体2.5万基因的约30亿碱基对,换算成容量大小则约为3GB。
为了保障基因数据的完整性,在此基础上还需要做30次的平行测试。最终测序完成之后,全基因组的数据量便将达到约100G。
也正是因为数据量和数据种类的日益庞大,这方面的工作数据存储动辄便以PB为单位来保存。
团队在面对这些挑战所选择的突破口,并不是大多数人以为的强行堆算力,而是用底层数据存储的飞跃来做到提速。
简单来说,就是通过把以往不能合并处理的海量数据,打破它们之间的壁障,让整体的处理效率“更上一层楼”。
团队在这项任务中的存储系统,是来自华为面向高性能数据分析(HPDA)的分布式存储OceanStor Pacific系列。

来源:量子位
参考链接:
[1]https://en.wikipedia.org/wiki/Human_Genome_Project
[2]https://www.genome.gov/about-genomics/fact-sheets/Sequencing-Human-Genome-cost
[3]https://io500.org/
04
这款AI语音模型让派大星承认自己是钢铁侠,造假小扎对口型
你敢信,派大星当众宣称自己是钢铁侠,漫威宇宙和比基尼海滩梦幻联动:

I am Iron Man!
这深沉憨厚又有点喜感的嗓音,是派大星本星没错了。
而小扎也疯狂乱入,直接抢了派大星的台词,喊海绵宝宝去抓水母:
hi,spongebob,shall we go to catch jellyfishes?
没错,这又是AI的杰作——FakeYou语音伪造模型。
目前上传的人物语音模型已经有很多,包括海绵宝宝、摩根·弗里曼、辛普森一家、马男波杰克、灭霸等等。
demo在线可玩,快来试试~
操作也很简单,只需两步:

在图中第一个红框中的下拉菜单中选择你喜欢的人物,然后在下面的文本框中输入你希望TA说的话,再点击“Speak”就ok了~
另外,如果你还想让TA对上口型,FakeYou也在线提供了相关功能。
选择不同的视频model,上传音频文件就可以了。
那FakeYou是怎么实现文本转语音和对口型的呢?
对于文本转语音的任务,FakeYou提到了一系列的模型,主要是其中值得一提的是MelGAN。
它的整体结构也比较简单,工作流是这样的:

首先将输入的文本转化为梅尔声谱图,然后再利用GAN去学习图中的特征,提取声音的信息。
最后再通过傅里叶逆变换还原出原始声波。
而对口型任务使用的则是Wav2Lip模型。
并将口型的真值和遮住口型的部分输入网络,用残差网络相连。
同时还使用了视觉判别器来提高视觉质量和同步精度,进一步提高模型质量。
来源:量子位
试玩地址:https://fakeyou.com/
论文地址:https://arxiv.org/abs/1910.06711
END
