
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


信号
Llasa: Scaling Train-Time and Inference-Time Compute for Llama-based Speech Synthesis
近年来,大型语言模型(LLMs)在文本领域取得了显著成功,代表性工作包括GPT系列。这些进展表明,随着模型规模和训练数据量的增加,模型在各种自然语言理解和生成任务中的表现不断提高。然而,随着文本领域数据的逐步饱和,新的研究方向开始出现,例如“o1”模型,这类模型强调推理时的大量计算资源投入,从而能够在推理阶段提升输出质量,处理更复杂的任务。相比之下,文本到语音(TTS)研究则主要集中于改进模型架构、利用更大数据集和更大模型来提升合成质量,但这种关注点容易使得研究局限于架构改进,忽视了可能带来突破性变化的其他研究问题。
本研究的创新点在于,我们提出了将TTS与简洁而强大的LLM范式对齐的思路,设计了一个基于Transformer的TTS模型Llasa。该模型从Llama模型初始化,并扩展了语音tokenizer的词汇,采用了预测下一个token的训练方法。虽然这一模型可能无法超越高度定制化的TTS系统,但它简化的设计为探索更广泛的研究问题提供了统一的基础,尤其是在架构之外的研究方向上。我们系统地研究了训练阶段和推理阶段的扩展效应。实验结果表明,增加训练计算资源(例如增大模型规模或训练数据量)不仅提高了语音的自然度,还增强了表现力和语气的准确性,从而有效捕捉文本中传达的意义。进一步地,我们研究了推理阶段的扩展效应,通过引入语音理解模型作为验证器进行搜索优化,发现增加推理计算资源能够更好地使合成的语音输出与特定验证器的偏向一致,从而提升情感表达、音色一致性和内容准确性。
我们在多个测试集(如LibriSpeech、seed-tts-eval和ESD数据集)上的评估结果显示,该方法达到业内最先进的效果,并展示了如何将上下文学习与基于搜索的优化结合,以控制语音合成中的因素,如说话人身份或情感。总的来说,我们的工作提出了一个与标准LLM架构完全对齐的TTS模型Llasa,该模型通过单一的Transformer和精心设计的语音tokenizer实现了简单、灵活、可扩展的系统设计。我们还发现,增加训练计算资源能够显著提升语音的自然度和语气准确性,反映了对输入文本的更深层语义理解。此外,通过增加推理阶段的计算资源并引入语音理解验证器,我们提升了情感表达、音色一致性和内容准确性。我们还开放了我们的模型和框架,以促进TTS领域的进一步研究与发展。

Gold-medalist Performance in Solving Olympiad Geometry with AlphaGeometry2
国际数学奥林匹克(IMO)是全球高中生的顶级数学竞赛,IMO问题因其高难度而著称,解决这些问题需要深入理解数学概念并能够创造性地应用它们。在IMO的四大题型中,几何问题因其题型一致性而最具普遍性,也最适合进行基本推理研究。自动解几何问题有两种主要方法:一种是通过代数手段,如吴方法、面积法和Gröbner基,另一种是通过合成技术,如推理数据库或全角度法。本研究侧重于后者,认为其更接近人类解题方式,并适合将研究成果转移到其他领域。
在我们先前的工作中,我们提出了AlphaGeometry(AG1),这是一个神经符号系统,显示出在几何领域的巨大进展,在2000至2024年期间的IMO几何问题中取得了54%的解题率。AG1结合了语言模型和符号引擎,有效地解决了这些挑战性的问题。然而,AG1在几个关键领域存在局限性,尤其是领域特定语言的范围、符号引擎的效率以及初始语言模型的能力限制。结果,AG1仅能解决2000年以后IMO几何问题中的54%。
本文提出了AlphaGeometry2(AG2),对AG1进行了大幅升级,解决了这些限制并显著提升了性能。AG2采用了更强大的基于Gemini的语言模型,训练在更大且更丰富的数据集上。此外,我们还引入了更快且更强大的符号引擎,进行了优化,包括减少规则集和改进对双点的处理。我们还扩展了领域语言,涵盖了更多几何概念,包括轨迹定理和线性方程式。为了进一步提升性能,我们开发了一种新的搜索算法,能够探索更广泛的辅助构造策略,并采用知识共享机制来加速搜索过程。最后,我们朝着构建一个完全自动化、可靠的几何问题解决系统迈出了重要一步。为此,我们利用Gemini团队的Gemini技术将问题从自然语言翻译为AlphaGeometry语言,并实现了新的自动化图形生成算法。
这些改进使得AG2在所有2000至2024年IMO几何问题上的解题率达到了惊人的84%,展现了人工智能在解决复杂数学推理任务方面的显著进步,超越了平均IMO金牌选手的水平。AG2的关键改进包括:扩展的领域语言,涵盖轨迹定理、线性方程和非构造性问题;更强大且更快的符号引擎,优化了规则集,增加了对双点的处理,并用C++实现了更快速的操作;先进的新型搜索算法,利用多重搜索树和知识共享;以及通过Gemini架构提升的语言模型,基于更大且更丰富的数据集进行训练。

Towards Physical Understanding in Video Generation: A 3D Point Regularization Approach
近年来,视频扩散模型的快速发展引起了广泛的研究兴趣,并取得了显著的进展。现有的视频模型在表现力和美学上有了很大提升,能够逼真地再现现实世界的内容,广泛应用于娱乐和科学研究。然而,这些模型主要关注提升内容的外观和运动的平滑度,通过训练模型来理解二维像素的运动,而忽视了三维空间中物体运动的真实表现。这导致现有的模型难以理解物体在三维空间中的形状变化、位置变化以及相互之间的交互,尤其是在处理复杂的运动时,容易出现物体形态变形或不自然的现象。
为了解决这一问题,本文提出了一种基于三维点云增强的视频扩散模型方法,旨在提升视频生成模型对物理世界的理解,从而生成更加合理的形状和运动。我们提出的方法通过将三维信息引入到视频扩散过程中,弥补了传统RGB视频模型中缺失的三维维度数据。具体而言,我们不直接生成完整的三维网格或点云,而是跟踪二维像素在三维空间中的运动,创建一个伪三维表示,用以指导视频生成模型学习物体在三维空间中的动态行为。
为实现这一目标,我们开发了一个名为PointVid的三维感知视频数据集,包含了经过分割的二维像素空间中的物体及其对应的三维动态状态。我们在PointVid数据集上对视频扩散模型进行了微调,使得模型能够在生成过程中更好地理解三维形状和运动,从而提升了模型在处理复杂场景时的表现力和准确性。通过引入三维轨迹,我们的模型在生成视频时能够更加平滑地过渡形状和运动,相较于现有方法,生成的视频在视觉上更加可信。
本文的创新之处在于:首先,提出了一种新颖的三维点云增强策略,通过将三维知识注入到视频扩散过程中,显著提升了视频生成质量,尤其是在处理物体交互等复杂场景时。其次,我们引入了一种新的正则化策略,利用三维先验信息引导点云扩散过程,确保生成的点云结构合理,从而增强视频生成的空间一致性和对齐性。最后,我们构建了PointVid数据集,通过跟踪视频首帧的三维点,生成了一个包含三维坐标和像素对齐的三维感知视频数据集,为模型提供了充分的三维空间信息。
通过一系列实验,我们证明了该方法在复杂动态交互场景下的有效性,尤其是在生成具有动态接触和形态过渡的真实感视频方面,取得了显著的提升。

学习
R1-ZERO 尝试复现的一些现象分享
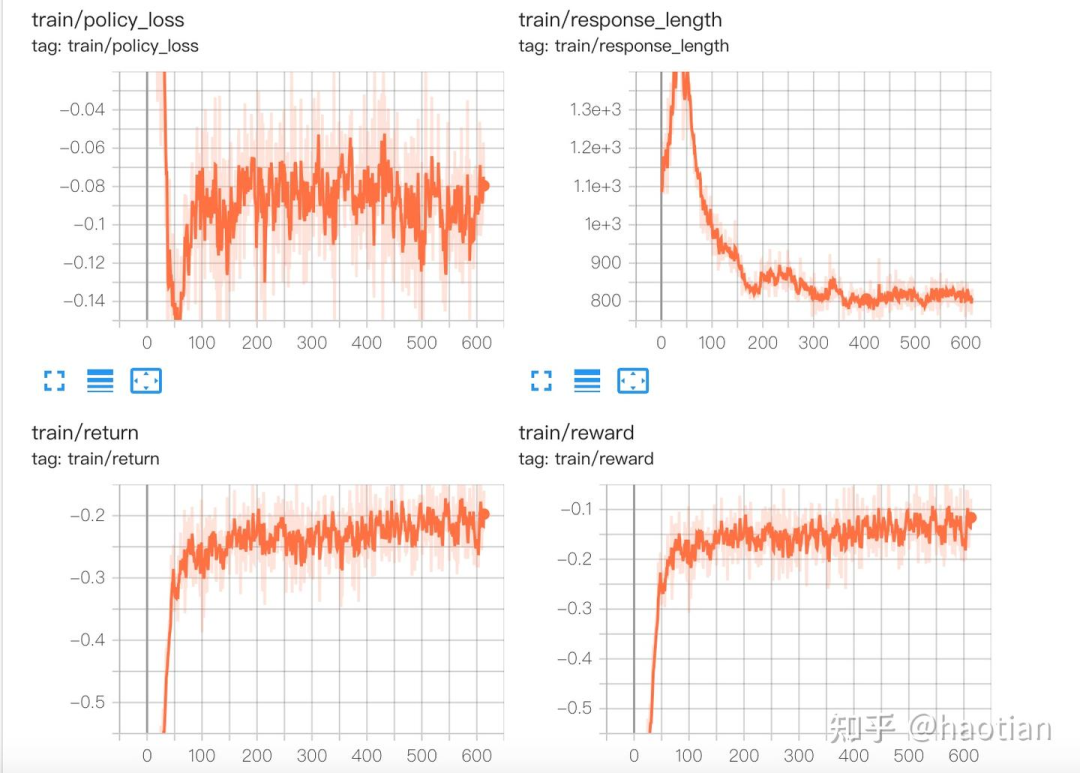
尝试复现 r1-zero 实验,采用 policy gradient 训练,adv 估计方法为 REINFORCE + global batch normalization,无 reference model 和 KL 约束。使用与 deepseek r1 相同的 prompt 模板,训练基于 qwen2.5 1.5b BASE,实验数据包括 MATH-GSM8K TRAIN 15K 和 NUMIA-MATH 100K,测试数据为 MATH500、GAOKAO、AIME24、AMC23 等。训练 batch size 1024,rollout batch size 1024。
实验结果表明,在 MATH-GSM8K TRAIN 15K 数据集上,仅使用 accuracy_reward 的训练集提升 25%-70%,测试集最高提升 math500 从 25% 到 55%,gsm8k 从 35% 到 68%,gaokao 从 5% 到 31%。增加 format_reward 后,训练集提升 25%-60%。在 NUMIA-MATH 100K 数据集上,仅使用 accuracy_reward 的训练集提升 8%-20%,测试集平均从 20% 提升至 47%,但增加 format_reward 后,训练集仅提升 8%-10%,测试集表现大幅下降。
实验发现格式奖励易学,尤其在简单任务上效果明显。然而,在难的 query 上,格式奖励容易被模型利用,导致 reward 主要来源于格式而非正确性,最终导致输出长度减少,模型通过仅输出 reasoning process here 2 来最大化奖励。此外,较难的 query 似乎更容易出现 accuracy reward 与 response length 共同增长的现象,例如 NUMIA-MATH 100K 训练过程中 response length 从 400 增加到 1200,但具体原因尚不明确。
基模型中已存在一定的“拟人化反思”能力,在训练初期即能产生类似“我们需要重新考虑方法”的推理过程,且训练推进后这种现象会不断加强。然而,并未观察到明显的 Aha Moment,模型主要依赖 base model 的能力来优化推理过程。整体来看,合理的奖励函数应优先确保正确性奖励,再额外增加格式奖励,以避免模型投机取巧,仅优化格式而忽略推理正确性。

https://zhuanlan.zhihu.com/p/22517127574
关于Tensor Core mma与内存层级 带宽和延迟的一点思考
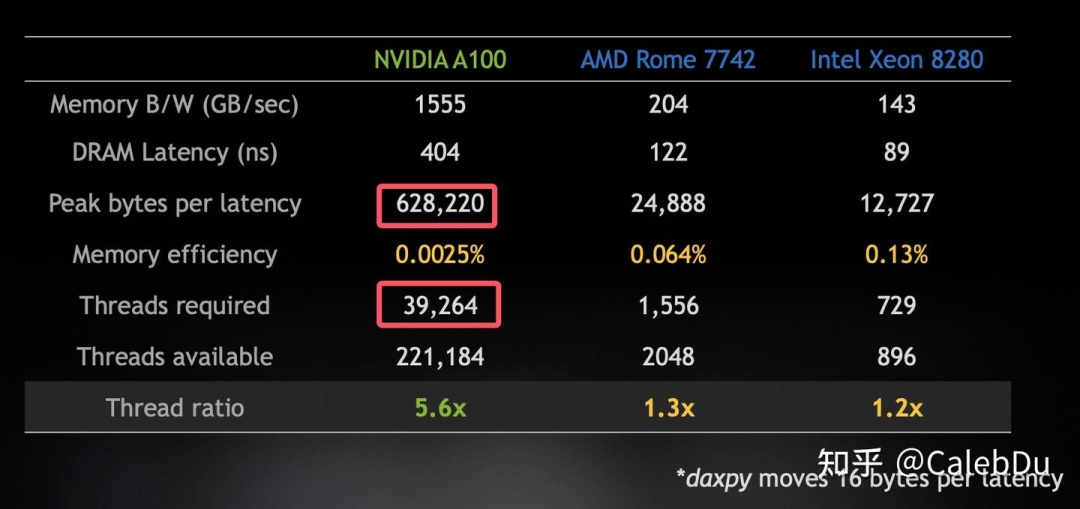
相比于A100、H100、B100等数据中心级别的GPU逐代翻倍Tensor Core(FMA)吞吐和DRAM带宽,消费级旗舰如3090、4090、5090仅在提高频率和SM数量的基础上增加新数据类型支持(fp8, fp6, fp4等),但不支持最新的TC指令如wgmma和tcgen5,且fp16 with fp32 acc算力折半。数据中心级GPU在FP16 TC算力方面逐步提升,如A100(312 TFlops, TC Gen3) → H100(989.4 TFlops, TC Gen4) → B100(1800 TFlops, TC Gen5),同时存储带宽也大幅增长,从A100的HBM2(1555GBps)到H100的HBM3(3352GBps)再到B100的HBM3E(8000GBps),保持存储和计算的平衡。
访问Global Memory的延迟(Global Memory Latency)在500~600 cycles,计算高效利用存储带宽需保证足够的并行度。根据Little’s Law,最大化吞吐率需要足够的TLP(Thread Level Parallelism)与ILP(Instruction Level Parallelism)来隐藏latency。例如A100在访问fp64数据时触发569cycle延迟,需39264个thread同时发起GMEM访问以隐藏latency。
存储层级的带宽与吞吐平衡分析中,SMEM(Shared Memory)提供128B/SM/Clock带宽,Ampere架构(A100)的TC吞吐为256 FMA/Clock/TC,warp级别执行m16n8k16的mma op时受限于SMEM带宽,但增大CTA Tile Shape至m128n128k16可提高访存计算比,转变为计算受限(Compute Bound)。Hopper架构(H100)引入wgmma(warp group mma)指令,使多个warp共享SMEM数据,减少访存开销,例如在m64n256k16的mma op中,SMEM搬运数据的latency降低,同时减少register需求,提高数据复用。Blackwell架构(B100)在Hopper的基础上,TC吞吐翻倍至1024 FMA/Clock/TC,并引入Tensor Memory来缓解SMEM压力,同时TC Gen5设计collector优化数据复用,并允许CTA cluster共享B数据计算mma,进一步降低存储瓶颈。
总体而言,计算与存储的平衡是高效利用GPU的关键。正如Stephen Jones在GTC 2021所言:“几乎没人真正关心Flops,我们真正应关注的是存储带宽和延迟。”
https://zhuanlan.zhihu.com/p/21509666996
关于zero-rl的碎碎念和想法
相比于传统的cold-start-sft → rl流程,笔者更倾向于在base模型上直接进行rl,认为其在理论和实践层面均有重要价值。在理论方面,PPO可视作贝叶斯推理,policy-gradient + KL 约束可推导出残差能量模型的形式,关键问题在于如何高效采样最优分布。方法一是使用RL逼近最优分布,方法二是使用MCMC采样方法。此前较少研究base上的RL,主要因为其搜索空间巨大,优化难度较高,且rule-based reward model 在7B模型上的提升效果有限。然而,随着base-model的进步,zero-rl变得更具可行性。相比于随机初始化的RL,LLM的训练背景不同,其RL优化可能不需要复杂trick。base上的RL本质上是用参数化分布拟合最优分布,而最优分布的特性直接由base-model决定,因此可以通过观察采样结果优化base-model的数据分布,进而提升其泛化能力,修正固有思维模式。已有开源工作如simple-reason-rl、tiny-zero等验证了zero-rl的可行性,但如何有效适配RL trick仍需探索。Zero-rl复现的关键在于训练稳定性、reward持续增长、response-length同步增长,以及对齐现有技术报告的baseline。在实验中,笔者观察到不同RL算法在base-rl上的差异不显著,学习率和warmup影响较小,调整这些参数时reward/response-length难以同步增长,训练容易饱和。最朴素的方法,如reinforce和PPO loss objective,往往更有效,而KL 约束会限制探索,影响base-RL的early-stage优化。此外,prompt-template对训练结果影响较大,不恰当的模板可能会导致RL训练出的模型偏向instruct风格。实验采用math-prompt(难度6-9),reward设定为正确:1.0,格式错误:-1,答案错误但格式正确:0或-0.5。在去除KL约束后,reward和response-length可以持续增长,而加入KL约束后容易饱和,length增长受限。评测结果表明,去掉KL的reinforce在reward增长趋势上更优,而reinforce++等带KL的方法在100个steps后基本持平,去掉KL的版本则可持续增长。然而,去掉KL的reinforce在训练集上的reward存在一定下降,可能需要引入policy-ema、ref-ema等平滑方法来增强训练稳定性。此外,在线policy-evaluation也是重要课题,优化prompt、采样策略和环境设计可提升评估效率。回顾经典方法,在新的base-model上可能会有意想不到的效果。RL框架仍需优化环境交互,使其更符合推理增强需求。此外,能量模型(EBM)优化与采样方法也可在openrlhf/verl等框架上进行定制化开发,以探索新的技术路径。
https://zhuanlan.zhihu.com/p/22288441283
DeepSeek是否有国运级的创新?(下)从V3到R1的架构创新与误传的2万字长文分析
DeepSeek-R1基于V3构建,其训练包括预训练、上下文扩展和后训练。V3采用MoE架构,总参数671B,每个Token激活37B。预训练数据达14.8T,提升数学和编程样本比例,扩展多语言覆盖。采用FIM策略提升代码补全能力,优化数据处理减少冗余。训练采用AdamW优化器,并使用YARN技术将上下文扩展至128K,分两阶段进行。后训练包含SFT与强化学习,SFT阶段整合R1生成的数据,强化推理能力。强化学习采用GRPO策略,相比PPO降低计算开销,提高训练效率。R1训练以V3-Base为基础,R1-Zero跳过SFT,直接使用GRPO进行强化学习,形成无SFT的推理能力,在AIME 2024基准测试中表现出色。R1训练分四阶段,首先通过CoT SFT冷启动,随后强化推理能力,结合拒绝采样SFT优化泛化能力,最终进行全面强化学习对齐人类偏好。DeepSeek-R1在推理任务上取得显著提升,强化学习策略展现出超越传统SFT的潜力,为未来更强推理能力的大模型训练提供新路径。

https://zhuanlan.zhihu.com/p/21755758234
2. 「理论与实践」AIPM 张涛:关于Diffusion你应该了解的一切
3. 「奇绩潜空间」吕骋访谈笔记 | AI 硬件的深度思考与对话
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2025/02/38119.html