
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


潜空间活动报名

信号
Improving LLM Reasoning through Scaling Inference Computation with Collaborative Verification
-
提出了一个基于多解复核的推理验证框架。通过生成多个推理路径,并使用验证器(Math-Rev和Code-Rev)来评估和选择最佳答案。验证器通过对正确和错误解法的训练数据进行学习,从而提高分辨能力。 -
创新性地结合了Chain-of-Thought(CoT)和Program-of-Thought(PoT)两种解决方案进行验证。CoT提供清晰的步骤推理,而PoT提供可执行的精确验证机制。通过结合两者的优势,显著提升了验证的准确性和可靠性。
-
验证器的训练采用了无参考(reference-free)的偏好优化方法SimPO,表现优于现有方法 -
在多个基准测试(如GSM8k和MATH)上取得了SOTA结果 -
使用Qwen-72B-Instruct作为推理器时,甚至超越了GPT-4的表现 -
对于较弱的模型改进更为显著,例如可以帮助LLaMA2-7B等模型显著提升性能
-
采样和重排序策略会带来额外的计算开销 -
当前的验证器基于整体解决方案给出反馈,缺乏对每个推理步骤的细粒度评估 -
对于短序列任务的效果相对较差。
 https://arxiv.org/abs/2410.05318
https://arxiv.org/abs/2410.05318Relaxed Recursive Transformers: Effective Parameter Sharing with Layer-wise LoRA
-
使用递归结构压缩模型
-
层级LoRA放松约束
-
Continuous Depth-wise Batching策略
-
参数压缩效果
-
推理加速
-
初始化方法研究
 https://arxiv.org/abs/2410.20672
https://arxiv.org/abs/2410.20672Looped Transformers for Length Generalization
-
采用端到端训练,不需要中间步骤的监督信号,只需要任务的最终输出和所需步数 -
在每次迭代中注入原始输入,增强表征能力 -
使用自适应的停止条件,包括基于已知步数的Oracle和基于最大置信度的动态判断
-
在多个长度泛化任务上,Looped Transformer 的性能都显著优于基线模型,可以泛化到远超训练集长度的输入 -
与使用 pause token 等其他变体相比,自适应深度循环方案效果更好 -
可视化结果显示模型学会了何时停止迭代,并能在合适的步数后收敛

LLM The Genius Paradox: A Linguistic and Math Expert’s Struggle with Simple Word-based Counting Problems
-
推翻了三个主流假设:
-
子词标记化导致性能差 – 通过设计多种字符级评估实验发现并非如此 -
缺乏字符级训练 – 在分类任务上使用字符输入仍有较好表现 -
单词中独特字符过多 – 性能与独特字符数量无关
-
数学/代码训练数据无助于改善:
-
专门训练的数学和代码模型在这类简单任务上仍然表现糟糕 -
但代码模型在显式编写Python代码时可以完美解决
-
使用推理可以显著提升性能:
-
比直接回答或微调更有效 -
通过链式推理等方法,GPT-4o可以完美解决所有计数任务 -
强调了”先推理后回答”的重要性
-
模型缺陷研究方法:
-
应该通过严格的实验设计验证假设 -
不能轻易归因于模型或数据的固有限制
-
能力获取与评估:
-
复杂任务的能力不一定能迁移到简单任务 -
需要更全面的能力评估标准
-
训练策略:
-
应该在预训练中培养推理意识 -
推理能力比简单的任务特定训练更重要

Kotaemon

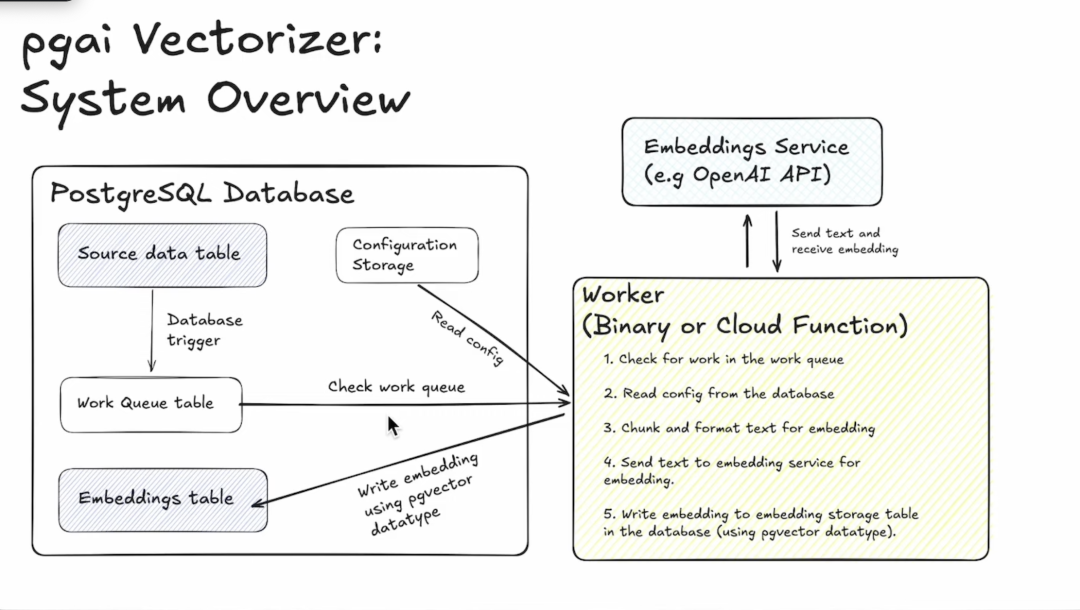
pgai
2. 「理论与实践」AIPM 张涛:关于Diffusion你应该了解的一切
3. 「奇绩潜空间」吕骋访谈笔记 | AI 硬件的深度思考与对话
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/11/21661.html