
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即
可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!



HuggingFace&Github
Phi-4-multimodal-instruct:轻量级的开源多模态基础模型
Phi-4-multimodal-instruct 是微软推出的一款轻量级开源多模态基础模型,借助 Phi-3.5 和 4.0 模型的语言、视觉及语音研究与数据集,此版本基于 Phi-3 系列用户反馈,改进了此前双模型管道的局限,新架构和训练技术提升了性能。
应用场景:处理文本、图像和音频输入并生成文本输出,有 128K 令牌上下文长度。该模型经监督微调、直接偏好优化和强化学习从人类反馈等增强,支持多种语言。
模型质量:
-
具有强大的自动语音识别(ASR)和语音翻译(ST)性能,超越专家ASR模型WhisperV3和ST模型SeamlessM4T-v2-Large。
-
在 Huggingface OpenASR 排行榜上排名第一,词错误率为 6.14%,而当前最佳模型的错误率为 6.5%。
-
第一个可以进行语音摘要的开源模型,且性能接近GPT4o。
-
在语音问答任务上,与 Gemini-1.5-Flash 和 GPT-4o-realtime-preview 等接近的模型存在差距。

https://huggingface.co/microsoft/Phi-4-multimodal-instruct
学习
Multi-Die芯片设计如何更健康、更可靠?
Multi-Die设计通过在单个封装中集成多个裸片,解决了芯片制造和良率问题,但也带来了复杂性和可靠性挑战。新思科技与台积公司合作,展示了基于UCIe规范的Multi-Die互连通信,并通过监控、测试和修复(MTR)IP,确保互连的健康状况和可靠性。UCIe规范标准化了Die-to-Die互连,但高速通信特性要求严格监控和修复,以应对窄间距、仅主带和边带通信、高速信号完整性、冗余与修复以及环境变化性等挑战。
新思科技的MTR IP解决方案由多个组件组成,提供全面的健康检查。其中包括专用任务模式信号完整性监控(SIM),用于实时监控Die-to-Die通信通道;内置自测(BIST)算法,检测高级互连故障;累积修复功能,通过冗余通道和内置冗余分析(BIRA)算法进行硬修复,并将修复数据存储在E-Fuse中;以及通过高速接口实现高速访问与测试(HSAT)和自动测试向量生成(ATPG),降低测试成本并支持全生命周期测试。该解决方案适用于单个裸片、Multi-Die制造堆叠、开机模式和实时任务模式等多种场景。
在小芯片峰会上,新思科技展示了采用台积公司工艺的UCIe PHY IP一次性流片成功,并演示了两个裸片通过UCIe接口和GPIO接口通信。MTR IP在两种配置中分别提供互连可靠性、测试和修复功能,以及对IEEE 1838测试访问基础结构的支持。这些功能覆盖了制造、开机和定期健康监控阶段,确保在Multi-Die封装的全生命周期内实现高覆盖率和无向量膨胀。
新思科技致力于为客户提供基于UCIe的Multi-Die设计解决方案,确保芯片在设计、试制、生产和现场阶段的高良率和鲁棒性,推动半导体技术的创新和突破
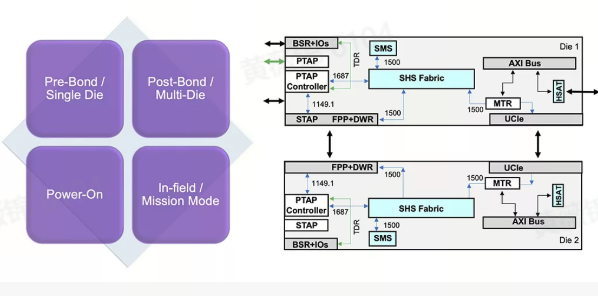
https://zhuanlan.zhihu.com/p/26810328567
Self-rewarding self-correction for LLMs
本文探讨了如何让大型语言模型学会像O1/R1那样进行自我修正(self-correction),以提升数学推理能力。现有方法(如基于prompting或fine-tuning)难以实现真正的自我修正,因为模型缺乏对自身回答及问题的判断能力,无法决定何时修正答案。近期Google研究表明,强化学习(RL)可以提升模型的修正能力,但现有框架存在两个问题:依赖外部prompt和缺乏选择性修正的判断机制。
针对这些问题,我们提出了一种新方法,将生成式奖励模型(generative reward model, RM)融入推理过程,使模型能够自主判断答案质量,并决定何时进行自我修正或输出最终答案。我们推测,类似“wait”、“aha”这样的词语可能类似于生成式RM中的预设token,帮助模型进行自我奖励,从而决定是否修正答案。
我们的方法分为两个步骤。首先,采用顺序拒绝采样(sequential rejection sampling),让基础模型在指令引导下逐步生成不同阶段的回复,并拼接成一个长的推理路径(CoT),其中包含期望的自我奖励与自我修正行为。然后在合成数据上进行fine-tuning,让模型学会这种模式。其次,在第一步的基础上,使用RL方法(如PPO和迭代DPO)对真实奖励进行优化。
尽管有技术报告称单独使用RL也能让自我修正能力自然涌现,但近期研究发现,许多开源复现的“aha”时刻其实已经存在于基础模型中,简单的RL训练并未增强该能力。此外,RL训练的效果依赖于基础模型的选择,而R1/O1的基础模型退火策略及预训练数据未公开,难以判断自我修正是否完全由RL训练导致。
相反,我们的实验表明,如果模型先通过数据合成学习自我修正模式(第一步),我们的框架可以让模型更有选择性地进行自我修正,提升测试准确率的同时减少推理所需的token数。我们还分析了模型作为奖励模型的能力,发现其准确率已接近单独训练的ORM(Oracle Reward Model)。模型作为奖励模型的能力主要源于第一阶段的数据合成与训练,第二阶段的强化学习主要寻找两个类别(识别错误答案与正确答案)准确率的最优权衡。此外,模型倾向于保守,尽量在答案正确时以大概率识别,避免将正确答案修改为错误。
未来,我们的框架可进一步扩展至中间步骤的判断与纠错,提升推理过程的灵活性。此外,目前的RL方法以单轮为主,引入多轮RL训练可能进一步增强模型的自我修正能力。

https://zhuanlan.zhihu.com/p/26811377177
CUTLASS库使用与优化指北(一)
CUTLASS(CUDA Template Linear Algebra Subroutine Library)是NVIDIA推出的一个高性能、开源的CUDA模板库,专注于优化GPU上的矩阵计算(如GEMM和CONV),尤其针对深度学习中的张量核心(Tensor Core)。它通过模板元编程和高度抽象的接口,允许开发者灵活定义计算流程,同时保持接近手写CUDA内核的性能。
CUTLASS通过模块化设计将计算过程分解为多个可组合的组件,支持自定义数据布局、流水线策略等。它针对NVIDIA的Volta、Ampere、Hopper等架构进行了优化,支持多种数据类型(如FP16、BF16、TF32、FP64等),并提供接近理论峰值的计算效率。此外,CUTLASS还支持跨平台兼容,适配不同CUDA版本和NVIDIA GPU全系列。
CUTLASS采用层级化的计算结构,包括Thread(单线程处理的小数据块)、Warp(多个线程协作)、Block(线程块内协作)和Grid(全局调度)。这种结构通过共享内存加速数据复用,显著提升计算效率。
通过CUTLASS的模板参数化,开发者可以轻松定义GEMM操作。例如,一个完整的FP32矩阵乘法可以通过指定数据类型、数据布局、计算架构等参数实现。CUTLASS内部自动处理线程块/网格划分、共享内存分配等细节,简化了开发流程。
CUTLASS支持Tensor Core加速计算,开发者可以通过调整模板参数启用FP16/BF16等数据类型。此外,还可以自定义分块大小(如ThreadBlockShape和WarpShape)以优化性能。性能调优建议包括数据对齐、内存布局优化和流水线策略调整。
https://zhuanlan.zhihu.com/p/26869575907
用DDPM来离散编码
文章介绍了DDCM(Denoising Diffusion Codebook Models)模型,这是一种基于预训练DDPM(Denoising Diffusion Probabilistic Models)的创新方法,通过将噪声采样限制在有限集合(Codebook)中,实现了类似VQ-VAE的离散编码与重构功能,而无需额外训练。DDCM的核心思想是将DDPM的噪声采样空间从连续变为有限集合,通过预采样固定噪声向量,并在每次采样时从中均匀选择。实验表明,即使采样空间有限,DDCM仍能保持接近DDPM的生成能力,当Codebook大小达到一定程度时,FID指标几乎不受影响。
DDCM的另一个创新点是将离散编码视为条件控制生成问题。通过预测模型选择最优噪声向量,使生成结果尽可能接近目标样本。这一过程将图片转化为整数序列,重构效果较为理想。此外,DDCM还引入了重要采样机制,通过概率密度函数对噪声向量进行加权采样,以更贴近连续采样轨迹,从而在理论上保证了离散化过程的合理性。
文章还探讨了DDCM在条件生成和分类器引导生成中的应用,并提出了相应的选择规则和采样分布构造方法。作者认为DDCM具有重要的潜在影响,尤其是在多模态LLM中作为“图片Tokenizer”的角色。DDCM生成的离散编码天然为1D,解决了VQ、FSQ等方案中编码结果保留2D特性的难题,简化了自回归生成时的排序问题。然而,DDCM目前仍存在改进空间,例如编码速度受限于DDPM采样速度,且加速采样会增加重构损失。总体而言,DDCM是一种具有潜力且值得进一步优化的离散编码方法。

https://zhuanlan.zhihu.com/p/26898362967
2. 「理论与实践」AIPM 张涛:关于Diffusion你应该了解的一切
3. 「奇绩潜空间」吕骋访谈笔记 | AI 硬件的深度思考与对话
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2025/02/43189.html